Ke Li
Sep 12, 2017
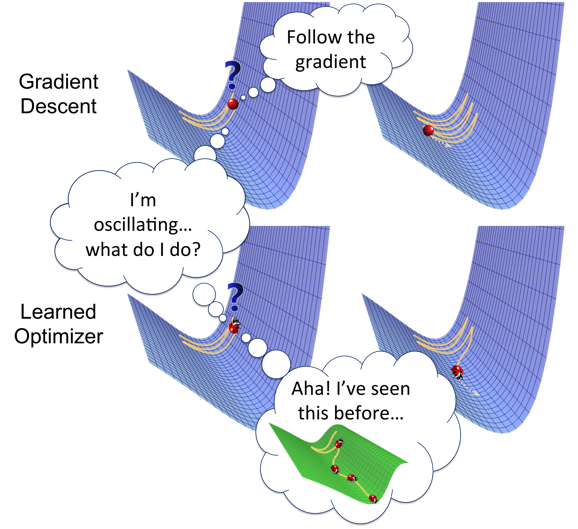
Since we posted our paper on “Learning to Optimize” last year, the area of optimizer learning has received growing attention. In this article, we provide an introduction to this line of work and share our perspective on the opportunities and challenges in this area.
Machine learning has enjoyed tremendous success and is being applied to a wide variety of areas, both in AI and beyond. This success can be attributed to the data-driven philosophy that underpins machine learning, which favours automatic discovery of patterns from data over manual design of systems using expert knowledge.
Yet, there is a paradox in the current paradigm: the algorithms that power machine learning are still designed manually. This raises a natural question: can we learn these algorithms instead? This could open up exciting possibilities: we could find new algorithms that perform better than manually designed algorithms, which could in turn improve learning capability.
Continue
Abhishek Kar
Sep 5, 2017
Consider looking at a photograph of a chair.
We humans have the remarkable capacity of inferring properties about the 3D shape of the chair from this single photograph even if we might not have seen such a chair ever before.
A more representative example of our experience though is being in the same physical space as the chair and accumulating information from various viewpoints around it to build up our hypothesis of the chair’s 3D shape.
How do we solve this complex 2D to 3D inference task? What kind of cues do we use?
How do we seamlessly integrate information from just a few views to build up a holistic 3D model of the scene?
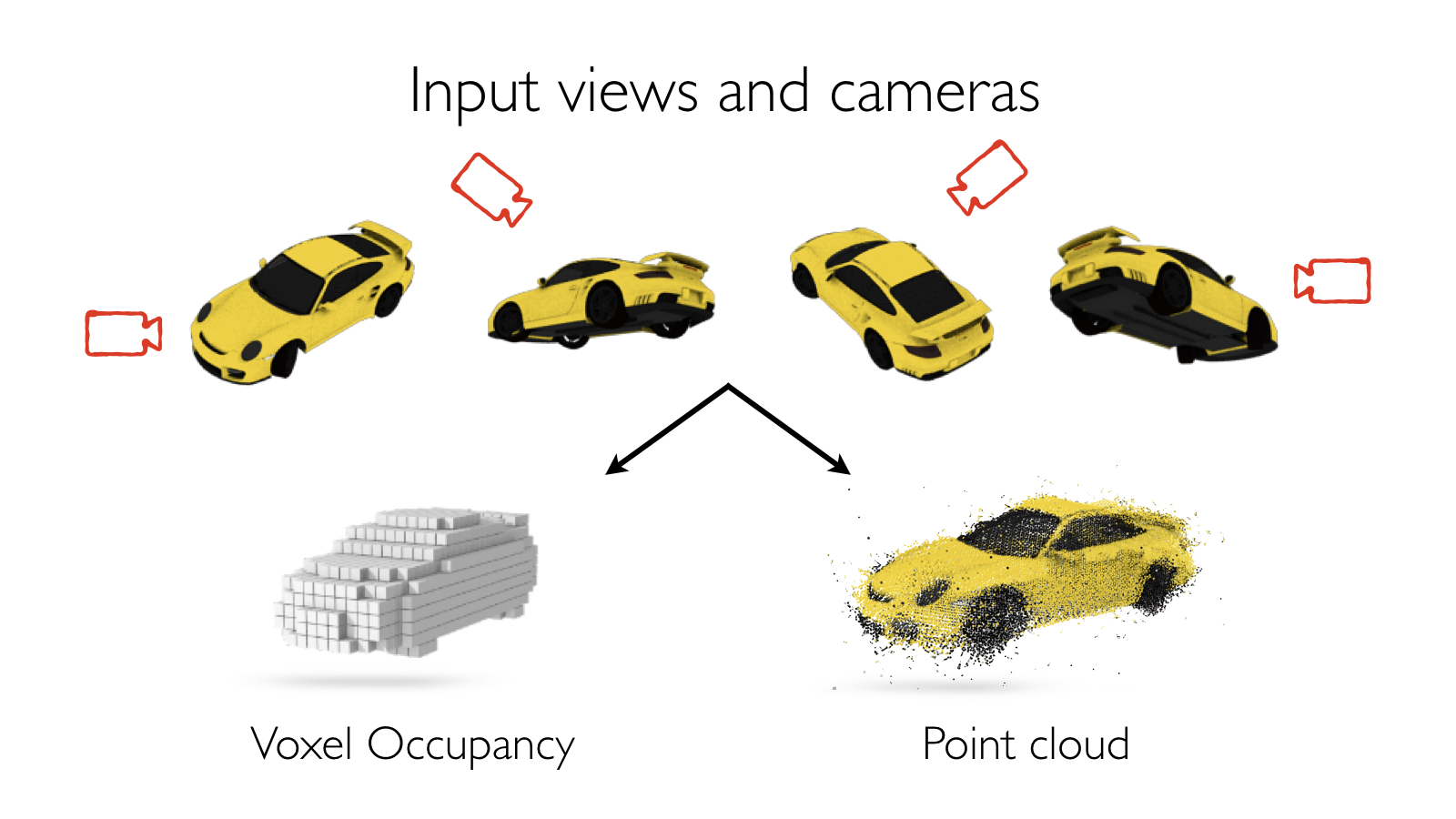
A vast body of work in computer vision has been devoted to developing algorithms which leverage various cues from images that enable this task of 3D reconstruction.
They range from monocular cues such as shading, linear perspective, size constancy etc. to binocular and even multi-view stereopsis.
The dominant paradigm for integrating multiple views has been to leverage stereopsis, i.e. if a point in the 3D world is viewed from multiple viewpoints, its location in 3D can be determined by triangulating its projections in the respective views.
This family of algorithms has led to work on Structure from Motion (SfM) and Multi-view Stereo (MVS) and have been used to produce city-scale 3D models and enable rich visual experiences such as 3D flyover maps.
With the advent of deep neural networks and their immense power in modelling visual data, the focus has recently shifted to modelling monocular cues implicitly with a CNN and predicting 3D from a single image as depth/surface orientation maps or 3D voxel grids.
In our recent work, we tried to unify these paradigms of single and multi-view 3D reconstruction.
We proposed a novel system called a Learnt Stereo Machine (LSM) that can leverage monocular/semantic cues for single-view 3D reconstruction while also being able to integrate information from multiple viewpoints using stereopsis - all within a single end-to-end learnt deep neural network.
Continue
Chi Jin and Michael Jordan
Aug 31, 2017
This post was initially published on Off the Convex Path. It is reposted here with authors’ permission.
A core, emerging problem in nonconvex optimization involves the escape of saddle points. While recent research has shown that gradient descent (GD) generically escapes saddle points asymptotically (see Rong Ge’s and Ben Recht’s blog posts), the critical open problem is one of efficiency — is GD able to move past saddle points quickly, or can it be slowed down significantly? How does the rate of escape scale with the ambient dimensionality? In this post, we describe our recent work with Rong Ge, Praneeth Netrapalli and Sham Kakade, that provides the first provable positive answer to the efficiency question, showing that, rather surprisingly, GD augmented with suitable perturbations escapes saddle points efficiently; indeed, in terms of rate and dimension dependence it is almost as if the saddle points aren’t there!
Continue
Christian Häne
Aug 23, 2017
Digitally reconstructing 3D geometry from images is a core problem in computer vision. There are various applications, such as movie productions, content generation for video games, virtual and augmented reality, 3D printing and many more. The task discussed in this blog post is reconstructing high quality 3D geometry from a single color image of an object as shown in the figure below.
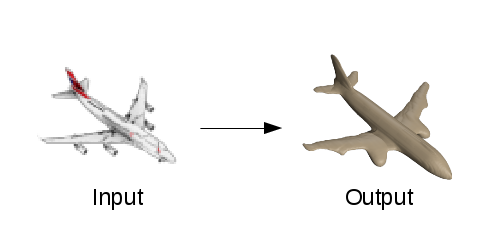
Humans have the ability to effortlessly reason about the shapes of objects and scenes even if we only see a single image. Note that the binocular arrangement of our eyes allows us to perceive depth, but it is not required to understand 3D geometry. Even if we only see a photograph of an object we have a good understanding of its shape. Moreover, we are also able to reason about the unseen parts of objects such as the back, which is an important ability for grasping objects. The question which immediately arises is how are humans able to reason about geometry from a single image? And in terms of artificial intelligence: how can we teach machines this ability?
Continue
Dylan Hadfield-Menell
Aug 17, 2017
Be careful what you reward
“Be careful what you wish for!” – we’ve all heard it! The story of King Midas
is there to warn us of what might happen when we’re not. Midas, a king who loves
gold, runs into a satyr and wishes that everything he touches would turn to gold.
Initially, this is fun and he walks around turning items to gold. But his
happiness is short lived. Midas realizes the downsides of his wish when he hugs
his daughter and she turns into a golden statue.

We, humans, have a notoriously difficult time specifying what we actually want,
and the AI systems we build suffer from it. With AI, this warning actually
becomes “Be careful what you reward!”. When we design and deploy an AI agent
for some application, we need to specify what we want it to do, and this
typically takes the form of a reward function: a function that tells the agent
which state and action combinations are good. A car reaching its destination is
good, and a car crashing into another car is not so good.
AI research has made a lot of progress on algorithms for generating AI behavior
that performs well according to the stated reward function, from classifiers
that correctly label images with what’s in them, to cars that are starting to
drive on their own. But, as the example of King Midas teaches us, it’s not the
stated reward function that matters: what we really need are algorithms for
generating AI behavior that performs well according to the designer or user’s
intended reward function.
Our recent work on Cooperative
Inverse Reinforcement Learning formalizes and investigates optimal
solutions to this value alignment problem — the joint problem of eliciting
and optimizing a user’s intended objective.
Continue
Subhashini Venugopalan and Lisa Anne Hendricks
Aug 8, 2017
Given an image, humans can easily infer the salient entities in it, and describe the scene effectively, such as, where objects are located (in a forest or in a kitchen?), what attributes an object has (brown or white?), and, importantly, how objects interact with other objects in a scene (running in a field, or being held by a person etc.). The task of visual description aims to develop visual systems that generate contextual descriptions about objects in images. Visual description is challenging because it requires recognizing not only objects (bear), but other visual elements, such as actions (standing) and attributes (brown), and constructing a fluent sentence describing how objects, actions, and attributes are related in an image (such as the brown bear is standing on a rock in the forest).
Current State of Visual Description

|

|
LRCN [Donahue et al. ‘15]: A brown bear standing on top of a lush green field.
MS CaptionBot [Tran et al. ‘16]: A large brown bear walking through a forest.
|
LRCN [Donahue et al. ‘15]: A black bear is standing in the grass.
MS CaptionBot [Tran et al. ‘16]: A bear that is eating some grass.
|
Descriptions generated by existing captioners on two images. On the left is an image of an object (bear) that is present in training data. On the right is an object (anteater) that the model hasn't seen in training.
Current visual description or image captioning models work quite well, but they can only describe objects seen in existing image captioning training datasets, and they require a large number of training examples to generate good captions. To learn how to describe an object like “jackal” or “anteater” in context, most description models require many examples of jackal or anteater images with corresponding descriptions. However, current visual description datasets, like MSCOCO, do not include descriptions about all objects. In contrast, recent works in object recognition through Convolutional Neural Networks (CNNs) can recognize hundreds of categories of objects. While object recognition models can recognize jackals and anteaters, description models cannot compose sentences to describe these animals correctly in context. In our work, we overcome this problem by building visual description systems which can describe new objects without pairs of images and sentences about these objects.
Continue
Over the last few years we have experienced an enormous data deluge, which has
played a key role in the surge of interest in AI. A partial list of some large
datasets:
- ImageNet, with over 14 million images for classification and object detection.
- Movielens, with 20 million user ratings of movies for collaborative filtering.
- Udacity’s car dataset (at least 223GB) for training self-driving cars.
- Yahoo’s 13.5 TB dataset of user-news interaction for studying human behavior.
Stochastic Gradient Descent (SGD) has been the engine fueling the
development of large-scale models for these datasets. SGD is remarkably
well-suited to large datasets: it estimates the gradient of the loss function on
a full dataset using only a fixed-sized minibatch, and updates a model many
times with each pass over the dataset.
But SGD has limitations. When we construct a model, we use a loss function
$L_\theta(x)$ with dataset $x$ and model parameters $\theta$ and attempt to
minimize the loss by gradient descent on $\theta$. This shortcut approach makes
optimization easy, but is vulnerable to a variety of problems including
over-fitting, excessively sensitive coefficient values, and possibly slow
convergence. A more robust approach is to treat the inference problem for
$\theta$ as a full-blown posterior inference, deriving a joint distribution
$p(x,\theta)$ from the loss function, and computing the posterior $p(\theta|x)$.
This is the Bayesian modeling approach, and specifically the Bayesian Neural
Network approach when applied to deep models. This recent tutorial by Zoubin
Ghahramani discusses some of the advantages of this approach.
The model posterior $p(\theta|x)$ for most problems is intractable (no closed
form). There are two methods in Machine Learning to work around intractable
posteriors: Variational Bayesian methods and Markov Chain Monte Carlo
(MCMC). In variational methods, the posterior is approximated with a simpler
distribution (e.g. a normal distribution) and its distance to the true posterior
is minimized. In MCMC methods, the posterior is approximated as a sequence of
correlated samples (points or particle densities). Variational Bayes methods
have been widely used but often introduce significant error — see this recent
comparison with Gibbs Sampling, also Figure 3 from the Variational
Autoencoder (VAE) paper. Variational methods are also more computationally
expensive than direct parameter SGD (it’s a small constant factor, but a small
constant times 1-10 days can be quite important).
MCMC methods have no such bias. You can think of MCMC particles as rather like
quantum-mechanical particles: you only observe individual instances, but they
follow an arbitrarily-complex joint distribution. By taking multiple samples you
can infer useful statistics, apply regularizing terms, etc. But MCMC methods
have one over-riding problem with respect to large datasets: other than the
important class of conjugate models which admit Gibbs sampling, there has been
no efficient way to do the Metropolis-Hastings tests required by general MCMC
methods on minibatches of data (we will define/review MH tests in a moment). In
response, researchers had to design models to make inference tractable, e.g.
Restricted Boltzmann Machines (RBMs) use a layered, undirected design to
make Gibbs sampling possible. In a recent breakthrough, VAEs use
variational methods to support more general posterior distributions in
probabilistic auto-encoders. But with VAEs, like other variational models, one
has to live with the fact that the model is a best-fit approximation, with
(usually) no quantification of how close the approximation is. Although they
typically offer better accuracy, MCMC methods have been sidelined recently in
auto-encoder applications, lacking an efficient scalable MH test.
Continue
Chelsea Finn
Jul 18, 2017
A key aspect of intelligence is versatility – the capability of doing many
different things. Current AI systems excel at mastering a single skill, such as
Go, Jeopardy, or even helicopter aerobatics. But, when you instead ask an AI
system to do a variety of seemingly simple problems, it will struggle. A
champion Jeopardy program cannot hold a conversation, and an expert helicopter
controller for aerobatics cannot navigate in new, simple situations such as
locating, navigating to, and hovering over a fire to put it out. In contrast, a
human can act and adapt intelligently to a wide variety of new, unseen
situations. How can we enable our artificial agents to acquire such versatility?
There are several techniques being developed to solve these sorts of problems
and I’ll survey them in this post, as well as discuss a recent technique from
our lab, called model-agnostic
meta-learning. (You can check out the research paper here, and the code
for the underlying technique here.)
Current AI systems can master a complex skill from scratch, using an
understandably large amount of time and experience. But if we want our agents to
be able to acquire many skills and adapt to many environments, we cannot afford
to train each skill in each setting from scratch. Instead, we need our agents to
learn how to learn new tasks faster by reusing previous experience, rather than
considering each new task in isolation. This approach of learning to learn, or
meta-learning, is a key stepping stone towards versatile agents that can
continually learn a wide variety of tasks throughout their lifetimes.
So, what is learning to learn, and what has it been used for?
Continue
Shubham Tulsiani and Tinghui Zhou
Jul 11, 2017
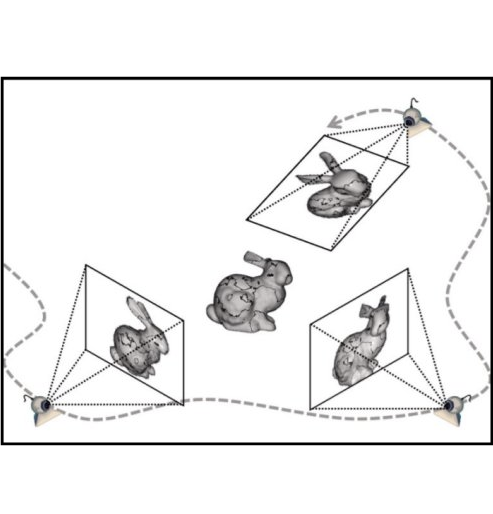
Given only a single 2D image, humans are able to effortlessly infer the rich 3D structure of the underlying scene. Since inferring 3D from 2D is an ambiguous task by itself (see e.g. the left figure below), we must rely on learning from our past visual experiences. These visual experiences solely consist of 2D projections (as received on the retina) of the 3D world. Therefore, the learning signal for our 3D perception capability likely comes from making consistent connections among different perspectives of the world that only capture partial evidence of the 3D reality. We present methods for building 3D prediction systems that can learn in a similar manner.
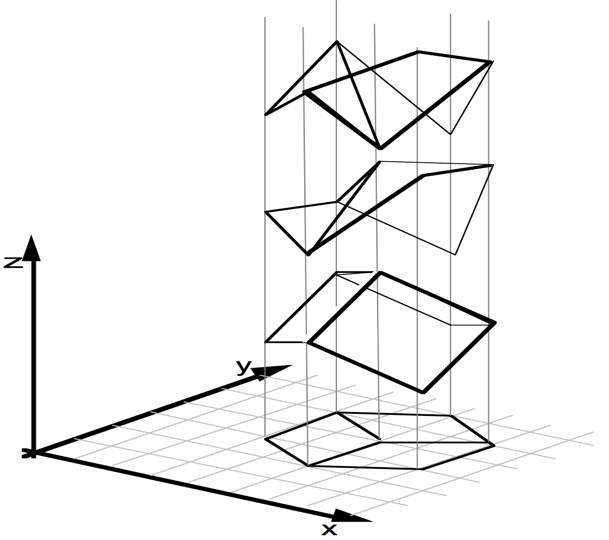 |
 |
 |
| An image could be the projection of infinitely many 3D structures (figure from Sinha & Adelson). |
Our visual experiences solely comprise of 2D projections of the 3D world. |
Our approach can learn from 2D projections and predict shape (top) or depth (bottom) from a single image. |
Building computational models for single image 3D inference is a long-standing problem in computer vision. Early attempts, such as the Blocks World or 3D surface from line drawings, leveraged explicit reasoning over geometric cues to optimize for the 3D structure. Over the years, the incorporation of supervised learning allowed approaches to scale to more realistic settings and infer qualitative (e.g. Hoiem et al.) or quantitative (e.g. Saxena et al.) 3D representations. The trend of obtaining impressive results in realistic settings has since continued to the current CNN-based incarnations (e.g. Eigen & Fergus, Wang et al.), but at the cost of increasing reliance on direct 3D supervision, making this paradigm rather restrictive. It is costly and painstaking, if not impossible, to obtain such supervision at a large scale. Instead, akin to the human visual system, we want our computational systems to learn 3D prediction without requiring 3D supervision.
With this goal in mind, our work and several other recent approaches explore another form of supervision: multi-view observations, for learning single-view 3D. Interestingly, not only do these different works share the goal of incorporating multi-view supervision, the methodologies used also follow common principles. A unifying foundation to these approaches is the interaction between learning and geometry, where predictions made by the learning system are encouraged to be ‘geometrically consistent’ with the multi-view observations. Therefore, geometry acts as a bridge between the learning system and the multi-view training data.
Continue
Joshua Achiam
Jul 6, 2017
(Based on joint work with David Held, Aviv Tamar, and Pieter Abbeel.)
Deep reinforcement learning (RL) has enabled some remarkable achievements in hard control problems: with deep RL, agents have learned to play video games directly from pixels, to control robots in simulation and in the real world, to learn object manipulation from demonstrations, and even to beat human grandmasters at Go. Hopefully, we’ll soon be able to take deep RL out of the lab and put it into practical, everyday technologies, like UAV control and household robots. But before we can do that, we have to address the most important concern: safety.
We recently developed a principled way to incorporate safety requirements and other constraints directly into a family of state-of-the-art deep RL algorithms. Our approach, Constrained Policy Optimization (CPO), makes sure that the agent satisfies constraints at every step of the learning process. Specifically, we try to satisfy constraints on costs: the designer assigns a cost and a limit for each outcome that the agent should avoid, and the agent learns to keep all of its costs below their limits.
This kind of constrained RL approach has been around for a long time, and has even inspired closely-related work here at Berkeley on probabilistically safe policy transfer. But CPO is the first algorithm that makes it practical to apply deep RL to the constrained setting for general situations—and furthermore, it comes with theoretical performance guarantees.
In our paper, we describe an efficient way to run CPO, and we show that CPO can successfully train neural network agents to maximize reward while satisfying constraints in tasks with realistic robot simulations. If you want to try applying CPO to your constrained RL problem, we’ve open-sourced our code.
Continue