Digitally reconstructing 3D geometry from images is a core problem in computer vision. There are various applications, such as movie productions, content generation for video games, virtual and augmented reality, 3D printing and many more. The task discussed in this blog post is reconstructing high quality 3D geometry from a single color image of an object as shown in the figure below.
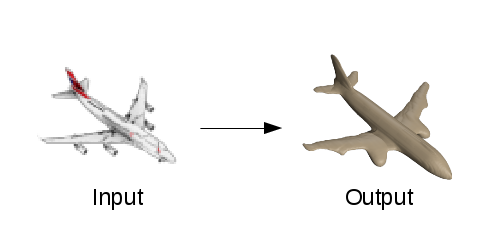
Humans have the ability to effortlessly reason about the shapes of objects and scenes even if we only see a single image. Note that the binocular arrangement of our eyes allows us to perceive depth, but it is not required to understand 3D geometry. Even if we only see a photograph of an object we have a good understanding of its shape. Moreover, we are also able to reason about the unseen parts of objects such as the back, which is an important ability for grasping objects. The question which immediately arises is how are humans able to reason about geometry from a single image? And in terms of artificial intelligence: how can we teach machines this ability?
Shape Spaces
The basic principle used to reconstruct geometry from ambiguous input is the fact that shapes are not arbitrary, and hence some shapes are likely, and some very unlikely. In general surfaces tend to be smooth. In man-made environments they are often piece-wise planar. For objects high level rules apply. For example airplanes very commonly have a fuselage with two main wings attached on each side and on the back a vertical stabilizer. Humans are able to acquire this knowledge by observing the world with their eyes and interacting with the world using their hands. In computer vision the fact that shapes are not arbitrary allows us to describe all possible shapes of an object class or multiple object classes as a low dimensional shape space, which is acquired from large collections of example shapes.
Voxel Prediction Using CNNs
One of the most recent lines of work for 3D reconstruction [Choy et al. ECCV 2016, Girdhar et al. ECCV 2016] utilizes convolutional neural networks (CNNs) to predict the shape of objects as a 3D occupancy volume. The 3D output volume is subdivided into volume elements, called voxels, and for each voxel an assignment to be either occupied or free space, i.e. the interior or exterior of the object respectively, is determined. The input is commonly given as a single color image which depicts the object, and the CNN predicts an occupancy volume using an up-convolutional decoder architecture. The network is trained end-to-end and supervised with known ground truth occupancy volumes which are acquired from synthetic CAD model datasets. Using this 3D representation and CNNs, models which are able to fit into a variety of object classes can be learned.
Hierarchical Surface Prediction
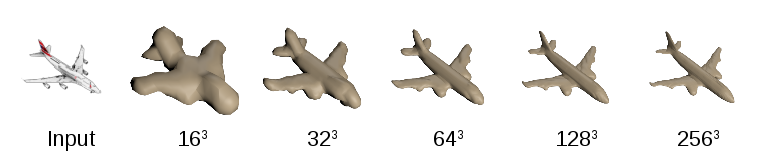
The main shortcoming with predicting occupancy volumes using a CNN is that the output space is three dimensional and hence has cubic growth with respect to increased resolution. This problem prevents the works mentioned above from predicting high quality geometry and is therefore restricted to coarse resolution voxel grids, e.g. 323 (c.f. figure above). In our work we argue that this is an unnecessary restriction given that surfaces are actually only two dimensional. We exploit the two dimensional nature of surfaces by hierarchically predicting fine resolution voxels only where a surface is expected judging from the low resolution prediction. The basic idea is closely related to octree representations which are often used in multi-view stereo and depth map fusion to represent high resolution geometry.
Method
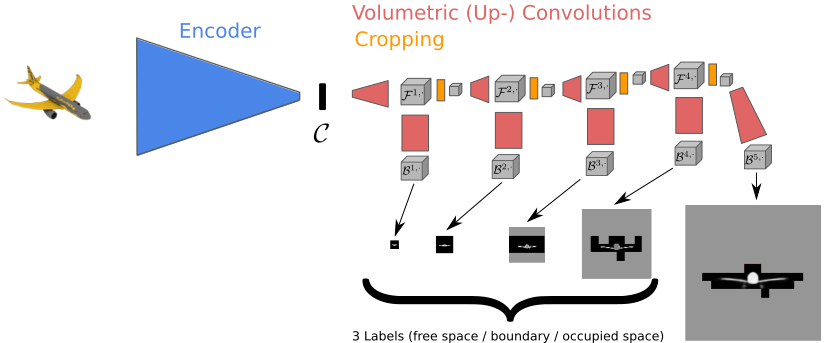
The basic 3D prediction pipeline takes a color image as input which gets first encoded into a low dimensional representation using a convolutional encoder. This low dimensional representation then gets decoded into a 3D occupancy volume. The main idea of our method, called hierarchical surface prediction (HSP), is to start decoding by predicting low resolution voxels. However, in contrast to the standard approach where each voxel would get classified into either free or occupied space, we use three classes: free space, occupied space, and boundary. This allows us to analyze the outputs at low resolution and only predict a higher resolution of the parts of the volume where there is evidence that it contains the surface. By iterating the refinement procedure we hierarchically predict high resolution voxel grids (see figure below). For more details about the method we refer the reader to our tech report [Häne et al. arXiv 2017].
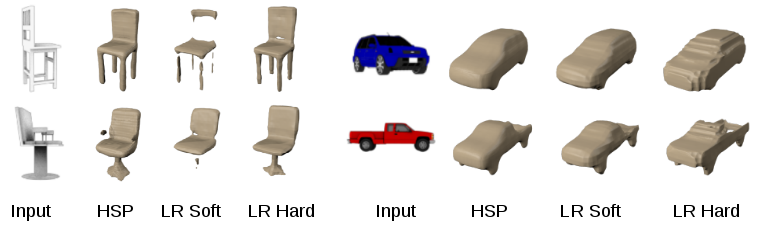
Experiments
Our experiments are mainly conducted on the synthetic ShapeNet dataset [Chang et al. arXiv 2015]. The main task we studied is predicting high resolution geometry from a single color image. We compare our method to two baselines which we call low resolution hard (LR hard) and low resolution soft (LR soft). These baselines predict at the same coarse resolution of 323 but differ in how the training data is generated. The LR hard baseline uses binary assignments for the voxels. All voxels are labeled as occupied if at least one of the corresponding high resolution voxels is occupied. The LR soft baseline uses fractional assignments reflecting the percentage of occupied voxels in the corresponding high resolution voxels. Our method, HSP predicts at a resolution of 2563. The results in the figures below show the benefits in terms of surface quality and completeness of the high resolution prediction compared to the low resolution baselines. Quantitative results and more experiments can be found in our tech report.

I would like to thank Shubham Tulsiani and Jitendra Malik for their valuable feedback.
This blog post is based on the tech report:
- Hierarchical Surface Prediction for 3D Object Reconstruction, C. Häne, S.Tulsiani, J.Malik, ArXiv 2017