Be careful what you reward
“Be careful what you wish for!” – we’ve all heard it! The story of King Midas is there to warn us of what might happen when we’re not. Midas, a king who loves gold, runs into a satyr and wishes that everything he touches would turn to gold. Initially, this is fun and he walks around turning items to gold. But his happiness is short lived. Midas realizes the downsides of his wish when he hugs his daughter and she turns into a golden statue.

We, humans, have a notoriously difficult time specifying what we actually want, and the AI systems we build suffer from it. With AI, this warning actually becomes “Be careful what you reward!”. When we design and deploy an AI agent for some application, we need to specify what we want it to do, and this typically takes the form of a reward function: a function that tells the agent which state and action combinations are good. A car reaching its destination is good, and a car crashing into another car is not so good.
AI research has made a lot of progress on algorithms for generating AI behavior that performs well according to the stated reward function, from classifiers that correctly label images with what’s in them, to cars that are starting to drive on their own. But, as the example of King Midas teaches us, it’s not the stated reward function that matters: what we really need are algorithms for generating AI behavior that performs well according to the designer or user’s intended reward function.
Our recent work on Cooperative Inverse Reinforcement Learning formalizes and investigates optimal solutions to this value alignment problem — the joint problem of eliciting and optimizing a user’s intended objective.
Faulty incentives in AI systems
Open AI gave a recent example of the difference between stated vs. intended reward functions. The system designers were working on reinforcement learning for racing games. They decided to reward the system for obtaining points; this seems reasonable as we expect policies that win races to get a lot of points. Unfortunately, this lead to quite suboptimal behavior in several environments:
This video demonstrates a racing strategy that pursues points and nothing else, failing to actually win the race. This is clearly distinct from the desired behavior, yet the designers did get exactly the behavior they asked for.
For a less light-hearted example of value misalignment, we can look back to late June 2015. Google had just released an image classifier feature that leveraged some of the recent advances in image classification. Unfortunately for one user, the system decided to classify his African-American friend as a gorilla.
Google Photos, y'all fucked up. My friend's not a gorilla. pic.twitter.com/SMkMCsNVX4
— Oluwafemi J Alciné (@jackyalcine) June 29, 2015
This didn’t happen because someone was ill-intentioned. It happened because of a misalignment between the objective given to the system and the underlying objective the company had in building their classifier. The reward function (or loss function) in classification is defined on pairs: (predicted label, true label). The standard reward function in classification research gives a reward of 0 for a correct classification (i.e., the predicted and true labels match) and a reward of -1 otherwise. This implies that all misclassifications are equally bad — but that’s not right, especially when it comes to misclassifying people.
According to the incentives it was given, the learning algorithm was willing to trade a reduction in the chance of, say, misclassifying a bicycle as a toaster for an equivalent increase in the chance of misclassifying a person as an animal. This is not a trade that a system designer would knowingly make.
The Value Alignment Problem
We can attribute the failures above to the mistaken assumption that the reward function communicated to the learning system is the true reward function that the system designer cares about. But in reality, there is often a mismatch, and this mismatch eventually leads to undesired behavior.
As AI systems are deployed further into the world, the potential consequences of this undesired behavior grow. For example, we must be quite sure that the optimization behind the control policy of, e.g., a self-driving car is making the right tradeoffs. However, ensuring this is hard: there are lots of ways to drive incorrectly. Enumerating and evaluating them is challenging, to say the least.
The value alignment problem is the problem of aligning AI objectives to ours. The reason this is so challenging is precisely because it is not always easy for us to describe what we want, even to other people. We should expect the same will be true when we communicate goals to AI. And yet, this is not reflected in the models we use to build AI algorithms. We typically assume, as in the examples above, that the objective is known and observable.
Inverse Reinforcement Learning
One area of research we can look to for inspiration is inverse reinforcement learning. In artificial intelligence research (e.g., reinforcement learning) we primarily focus on computing optimal (or even OK) behaviors. That is, given a reward function we compute an optimal policy. In inverse reinforcement learning, we do the opposite. We observe optimal behavior and try to compute the reward function that agent is optimizing. This suggests a rough strategy for value alignment: the robot observes human behavior, learns the human reward function with inverse reinforcement learning, and behaves according to that function.
This strategy suffers from three flaws. The first is fairly simple: the robot needs to know that it is optimizing reward for the human; if a robot learns that a person wants coffee it should get coffee for the person, as opposed to obtaining coffee for itself. The second challenge is harder to account for: people are strategic. If you know that a robot is watching you to learn what you want, that will change your behavior. You may exaggerate steps of the task, or demonstrate common mistakes or pitfalls. These types of cooperative teaching behaviors are simply not modelled by inverse reinforcement learning. Finally, inverse reinforcement learning is a pure inference problem, but in value alignment the robot has to jointly learn its goal and take steps to accomplish it. This means the robot has to account for an exploration-exploitation tradeoff during learning. Inverse reinforcement learning does not provide any guidance on how to balance these competing concerns.
Cooperative Inverse Reinforcement Learning
Our recent work within the Center for Human-compatible AI introduced a formalism for the value alignment problem that accounts for these discrepancies called Cooperative Inverse Reinforcement Learning (CIRL).
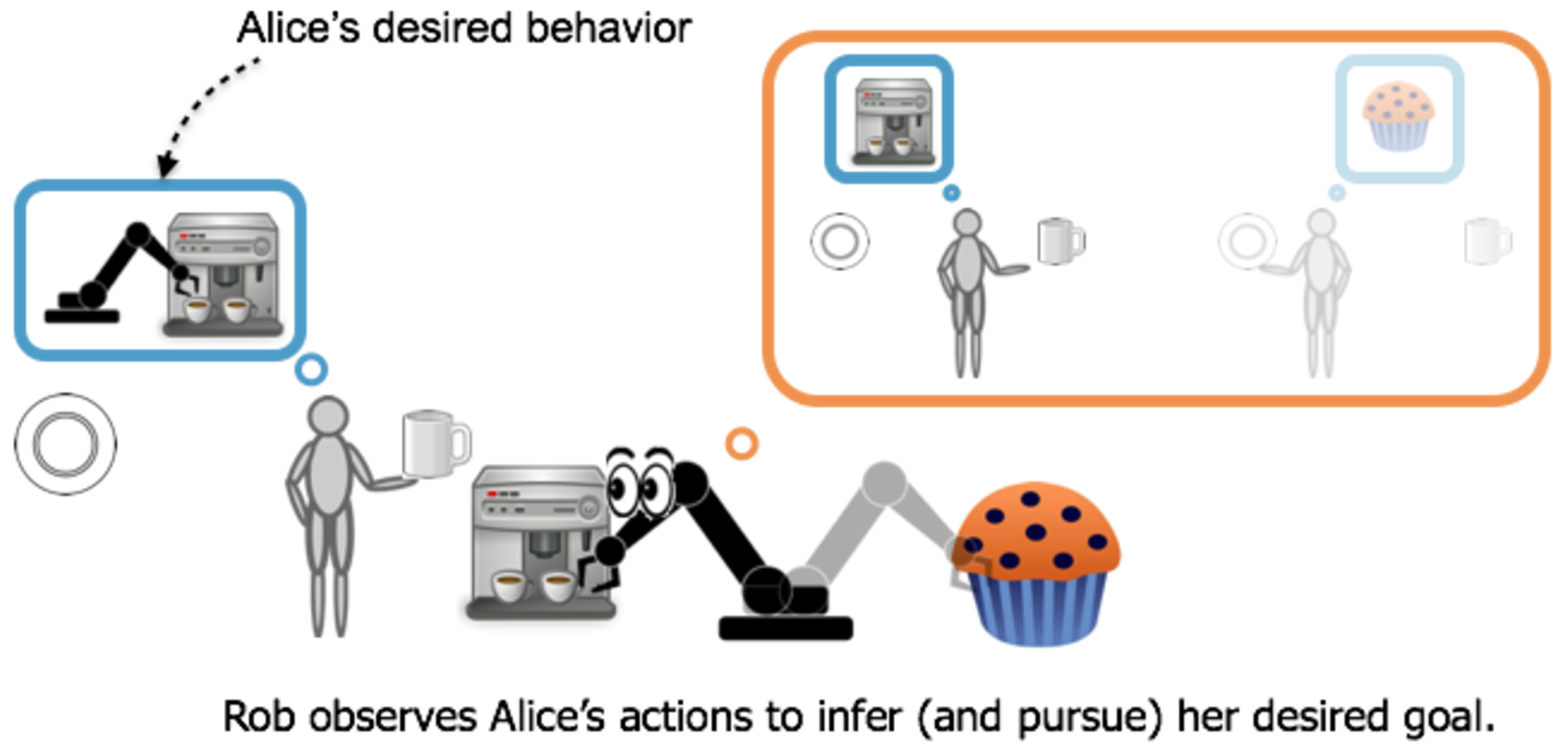
CIRL formalizes value alignment as a game with two players. A human player - we’ll call her Alice, and a robot player - we’ll call it Rob. Instead of Rob optimizing some given reward function, the two are cooperating to accomplish a shared goal, say making coffee. Importantly, only Alice knows this goal. Thus, Rob’s task is to learn the goal (e.g., by communicating with or observing Alice) and take steps to help accomplish it. A solution to this game is a cooperation strategy that describes how Alice and Rob should act and respond to each other. Rob will interpret what Alice does to get a better understanding of the goal, and even act to get clarification. Alice, in turn, will act in a way that makes it easy for Rob to help.
We can see that there is a close connection to inverse reinforcement learning. Alice is acting optimally according to some reward function and, in the course of helping her, Rob will learn the reward function Alice is optimizing. The crucial difference is that Alice knows Rob is trying to help and this means that the optimal cooperation strategy will include teaching behaviors for Alice and determine the best way for Rob to manage the exploration-exploitation tradeoff.
What’s Next?
With CIRL, we advocate that robots should have uncertainty about what the right reward function is. In two upcoming publications, to be presented at IJCAI 2017, we investigated the impact of this reward uncertainty on optimal behavior. “The Off-Switch Game” analyzes robots’ incentives to accept human oversight or intervention. We model this with a CIRL game where Alice can switch Rob off, but Rob can disable the off switch. We find that Rob’s uncertainty about Alice’s goal is a crucial component of the incentive to listen to her.
However, as the story of King Midas illustrates, we humans are not always perfect at giving orders. There may be situations where we want Rob to do what Alice means, not what she says. In “Should Robots be Obedient?”, we analyze the tradeoff between Rob’s obedience level (the rate at which it follows Alice’s orders) and the value it can generate for Alice. We show that, at least in theory, Rob can be more valuable if it can disobey Alice, but also analyze how this performance degrades if Rob’s model of the world is incorrect.
In studying the value alignment problem, we hope to lay the groundwork for algorithms that can reliably determine and pursue our desired objectives. In the long run, we expect this to lead to safer designs for artificial intelligence. The key idea in our approach is that we must account for uncertainty about the true reward signal, rather than taking the reward as given. Our work shows that this leads to AI systems that are more willing to accept human oversight and generate more value for human users. Our work also gives us a tool to analyze potential pitfalls in preference learning and investigate the impacts of model misspecification. Going further, we plan to explore efficient algorithms for computing solutions to CIRL games, as well as consider extensions to the value alignment problem that account for multiple people, each with their own goals and preferences.