Asymmetric Certified Robustness via Feature-Convex Neural Networks
TLDR: We propose the asymmetric certified robustness problem, which requires certified robustness for only one class and reflects real-world adversarial scenarios. This focused setting allows us to introduce feature-convex classifiers, which produce closed-form and deterministic certified radii on the order of milliseconds.
Figure 1. Illustration of feature-convex classifiers and their certification for sensitive-class inputs. This architecture composes a Lipschitz-continuous feature map $\varphi$ with a learned convex function $g$. Since $g$ is convex, it is globally underapproximated by its tangent plane at $\varphi(x)$, yielding certified norm balls in the feature space. Lipschitzness of $\varphi$ then yields appropriately scaled certificates in the original input space.
Despite their widespread usage, deep learning classifiers are acutely vulnerable to adversarial examples: small, human-imperceptible image perturbations that fool machine learning models into misclassifying the modified input. This weakness severely undermines the reliability of safety-critical processes that incorporate machine learning. Many empirical defenses against adversarial perturbations have been proposed—often only to be later defeated by stronger attack strategies. We therefore focus on certifiably robust classifiers, which provide a mathematical guarantee that their prediction will remain constant for an $\ell_p$-norm ball around an input.
Conventional certified robustness methods incur a range of drawbacks, including nondeterminism, slow execution, poor scaling, and certification against only one attack norm. We argue that these issues can be addressed by refining the certified robustness problem to be more aligned with practical adversarial settings.
A longstanding goal of the field of robot learning has been to create generalist agents that can perform tasks for humans. Natural language has the potential to be an easy-to-use interface for humans to specify arbitrary tasks, but it is difficult to train robots to follow language instructions. Approaches like language-conditioned behavioral cloning (LCBC) train policies to directly imitate expert actions conditioned on language, but require humans to annotate all training trajectories and generalize poorly across scenes and behaviors. Meanwhile, recent goal-conditioned approaches perform much better at general manipulation tasks, but do not enable easy task specification for human operators. How can we reconcile the ease of specifying tasks through LCBC-like approaches with the performance improvements of goal-conditioned learning?
TL;DR: In RLHF, there’s tension between the reward learning phase, which uses human preference in the form of comparisons, and the RL fine-tuning phase, which optimizes a single, non-comparative reward. What if we performed RL in a comparative way?
Figure 1:
This diagram illustrates the difference between reinforcement learning from absolute feedback and relative feedback. By incorporating a new component - pairwise policy gradient, we can unify the reward modeling stage and RL stage, enabling direct updates based on pairwise responses.
Large Language Models (LLMs) have powered increasingly capable virtual assistants, such as GPT-4, Claude-2, Bard and Bing Chat. These systems can respond to complex user queries, write code, and even produce poetry. The technique underlying these amazing virtual assistants is Reinforcement Learning with Human Feedback (RLHF). RLHF aims to align the model with human values and eliminate unintended behaviors, which can often arise due to the model being exposed to a large quantity of low-quality data during its pretraining phase.
Proximal Policy Optimization (PPO), the dominant RL optimizer in this process, has been reported to exhibit instability and implementation complications. More importantly, there’s a persistent discrepancy in the RLHF process: despite the reward model being trained using comparisons between various responses, the RL fine-tuning stage works on individual responses without making any comparisons. This inconsistency can exacerbate issues, especially in the challenging language generation domain.
Given this backdrop, an intriguing question arises: Is it possible to design an RL algorithm that learns in a comparative manner? To explore this, we introduce Pairwise Proximal Policy Optimization (P3O), a method that harmonizes the training processes in both the reward learning stage and RL fine-tuning stage of RLHF, providing a satisfactory solution to this issue.
Training Diffusion Models with Reinforcement Learning
replay
Diffusion models have recently emerged as the de facto standard for generating complex, high-dimensional outputs. You may know them for their ability to produce stunning AI art and hyper-realistic synthetic images, but they have also found success in other applications such as drug design and continuous control. The key idea behind diffusion models is to iteratively transform random noise into a sample, such as an image or protein structure. This is typically motivated as a maximum likelihood estimation problem, where the model is trained to generate samples that match the training data as closely as possible.
However, most use cases of diffusion models are not directly concerned with matching the training data, but instead with a downstream objective. We don’t just want an image that looks like existing images, but one that has a specific type of appearance; we don’t just want a drug molecule that is physically plausible, but one that is as effective as possible. In this post, we show how diffusion models can be trained on these downstream objectives directly using reinforcement learning (RL). To do this, we finetune Stable Diffusion on a variety of objectives, including image compressibility, human-perceived aesthetic quality, and prompt-image alignment. The last of these objectives uses feedback from a large vision-language model to improve the model’s performance on unusual prompts, demonstrating how powerful AI models can be used to improve each other without any humans in the loop.
Figure 1: stepwise behavior in self-supervised learning. When training common SSL algorithms, we find that the loss descends in a stepwise fashion (top left) and the learned embeddings iteratively increase in dimensionality (bottom left). Direct visualization of embeddings (right; top three PCA directions shown) confirms that embeddings are initially collapsed to a point, which then expands to a 1D manifold, a 2D manifold, and beyond concurrently with steps in the loss.
It is widely believed that deep learning’s stunning success is due in part to its ability to discover and extract useful representations of complex data. Self-supervised learning (SSL) has emerged as a leading framework for learning these representations for images directly from unlabeled data, similar to how LLMs learn representations for language directly from web-scraped text. Yet despite SSL’s key role in state-of-the-art models such as CLIP and MidJourney, fundamental questions like “what are self-supervised image systems really learning?” and “how does that learning actually occur?” lack basic answers.
Our recent paper (to appear at ICML 2023) presents what we suggest is the first compelling mathematical picture of the training process of large-scale SSL methods. Our simplified theoretical model, which we solve exactly, learns aspects of the data in a series of discrete, well-separated steps. We then demonstrate that this behavior can be observed in the wild across many current state-of-the-art systems.
This discovery opens new avenues for improving SSL methods, and enables a whole range of new scientific questions that, when answered, will provide a powerful lens for understanding some of today’s most important deep learning systems.
Molecular conformer generation is a fundamental task in computational chemistry. The objective is to predict stable low-energy 3D molecular structures, known as conformers, given the 2D molecule. Accurate molecular conformations are crucial for various applications that depend on precise spatial and geometric qualities, including drug discovery and protein docking.
We introduce CoarsenConf, an SE(3)-equivariant hierarchical variational autoencoder (VAE) that pools information from fine-grain atomic coordinates to a coarse-grain subgraph level representation for efficient autoregressive conformer generation.
TL;DR: Text Prompt -> LLM -> Intermediate Representation (such as an image layout) -> Stable Diffusion -> Image.
Recent advancements in text-to-image generation with diffusion models have yielded remarkable results synthesizing highly realistic and diverse images. However, despite their impressive capabilities, diffusion models, such as Stable Diffusion, often struggle to accurately follow the prompts when spatial or common sense reasoning is required.
The following figure lists four scenarios in which Stable Diffusion falls short in generating images that accurately correspond to the given prompts, namely negation, numeracy, and attribute assignment, spatial relationships. In contrast, our method, LLM-grounded Diffusion (LMD), delivers much better prompt understanding in text-to-image generation in those scenarios.
Figure 1: LLM-grounded Diffusion enhances the prompt understanding ability of text-to-image diffusion models.
Figure 1: “Interactive Fleet Learning” (IFL) refers to robot fleets in industry and academia that fall back on human teleoperators when necessary and continually learn from them over time.
In the last few years we have seen an exciting development in robotics and artificial intelligence: large fleets of robots have left the lab and entered the real world. Waymo, for example, has over 700 self-driving cars operating in Phoenix and San Francisco and is currently expanding to Los Angeles. Other industrial deployments of robot fleets include applications like e-commerce order fulfillment at Amazon and Ambi Robotics as well as food delivery at Nuro and Kiwibot.
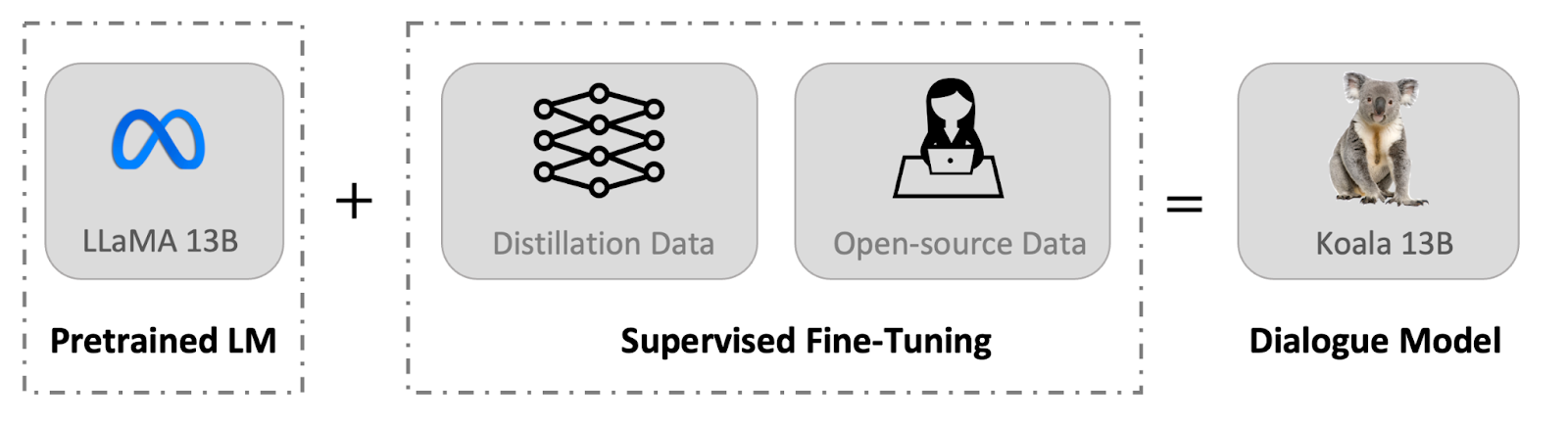
In this post, we introduce Koala, a chatbot trained by fine-tuning Meta’s LLaMA on dialogue data gathered from the web. We describe the dataset curation and training process of our model, and also present the results of a user study that compares our model to ChatGPT and Stanford’s Alpaca. Our results show that Koala can effectively respond to a variety of user queries, generating responses that are often preferred over Alpaca, and at least tied with ChatGPT in over half of the cases.
We hope that these results contribute further to the discourse around the relative performance of large closed-source models to smaller public models. In particular, it suggests that models that are small enough to be run locally can capture much of the performance of their larger cousins if trained on carefully sourced data. This might imply, for example, that the community should put more effort into curating high-quality datasets, as this might do more to enable safer, more factual, and more capable models than simply increasing the size of existing systems. We emphasize that Koala is a research prototype, and while we hope that its release will provide a valuable community resource, it still has major shortcomings in terms of content, safety, and reliability, and should not be used outside of research.
Reinforcement learning provides a conceptual framework for autonomous agents to learn from experience, analogously to how one might train a pet with treats. But practical applications of reinforcement learning are often far from natural: instead of using RL to learn through trial and error by actually attempting the desired task, typical RL applications use a separate (usually simulated) training phase. For example, AlphaGo did not learn to play Go by competing against thousands of humans, but rather by playing against itself in simulation. While this kind of simulated training is appealing for games where the rules are perfectly known, applying this to real world domains such as robotics can require a range of complex approaches, such as the use of simulated data, or instrumenting real-world environments in various ways to make training feasible under laboratory conditions. Can we instead devise reinforcement learning systems for robots that allow them to learn directly “on-the-job”, while performing the task that they are required to do? In this blog post, we will discuss ReLMM, a system that we developed that learns to clean up a room directly with a real robot via continual learning.
We evaluate our method on different tasks that range in difficulty. The top-left task has uniform white blobs to pickup with no obstacles, while other rooms have objects of diverse shapes and colors, obstacles that increase navigation difficulty and obscure the objects and patterned rugs that make it difficult to see the objects against the ground.

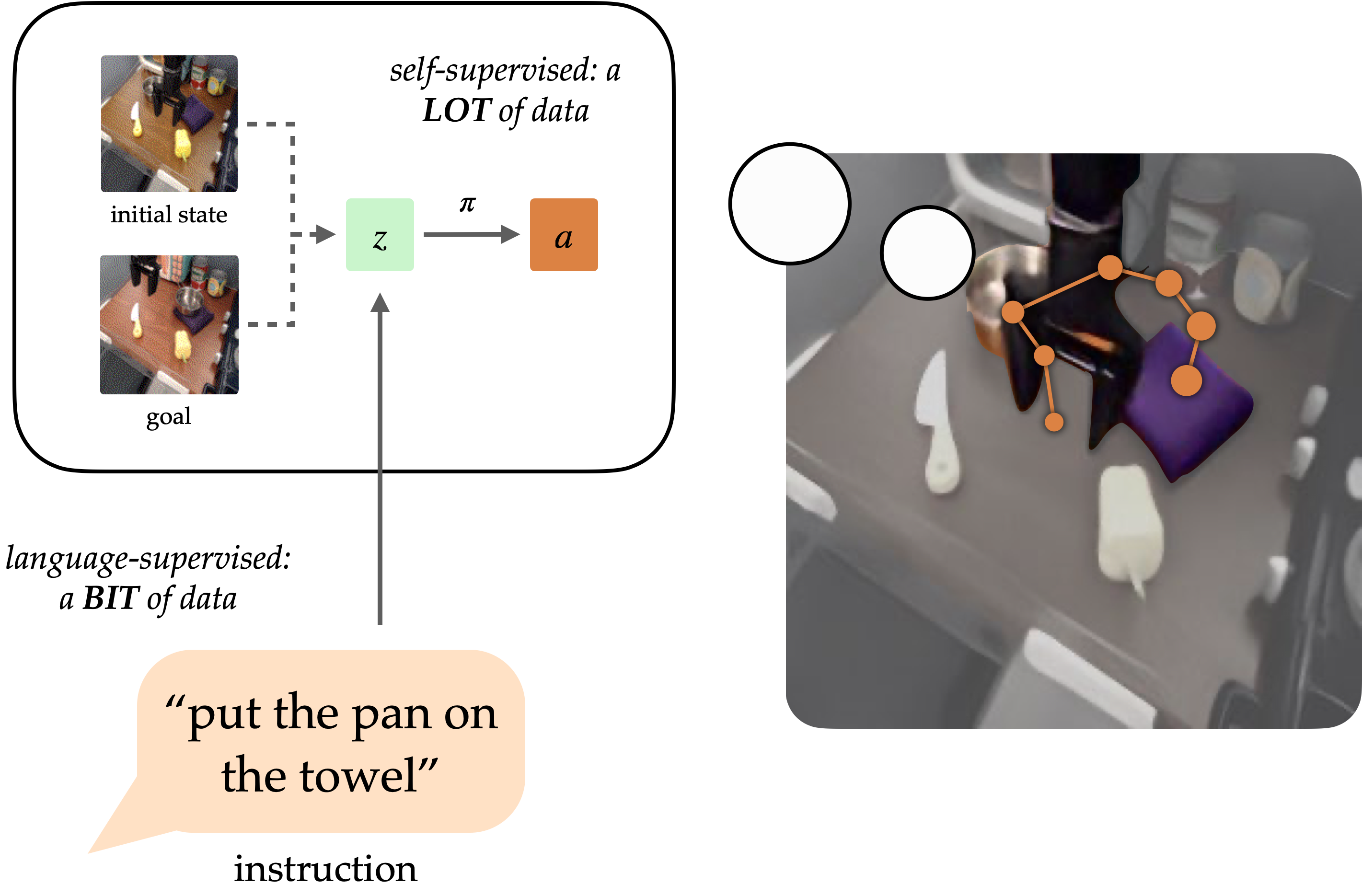

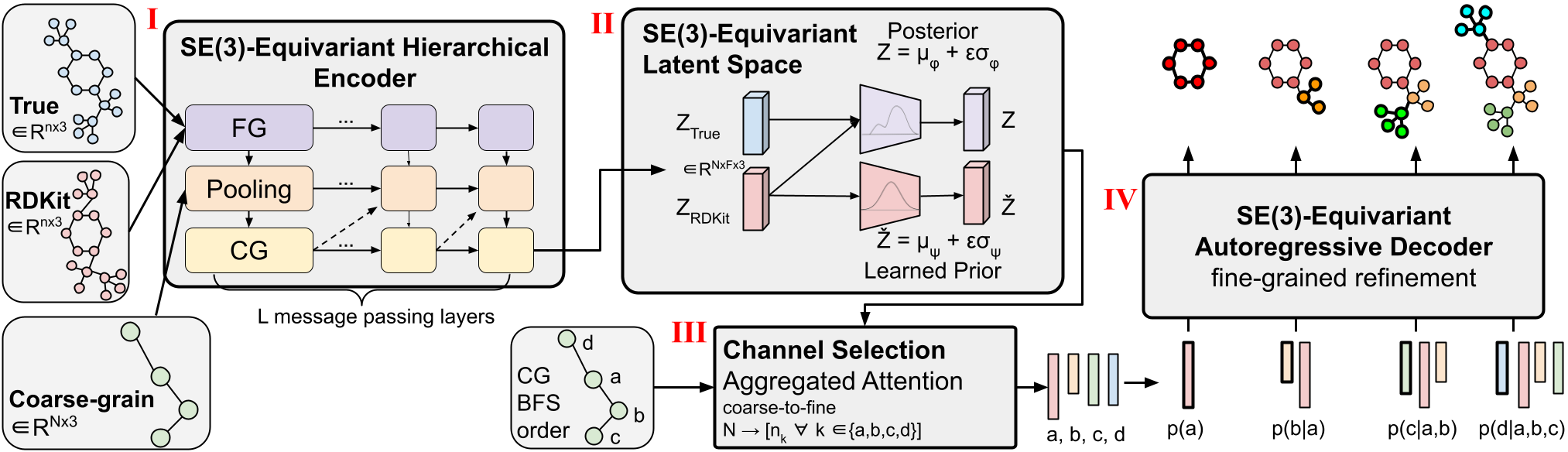
 Figure 1: LLM-grounded Diffusion enhances the prompt understanding ability of text-to-image diffusion models.
Figure 1: LLM-grounded Diffusion enhances the prompt understanding ability of text-to-image diffusion models.