Reliable robot grasping across many objects is challenging due to sensor noise
and occlusions that lead to uncertainty about the precise shape, position, and
mass of objects. The Dexterity Network (Dex-Net) 2.0 is a project centered on
using physics-based models of robust robot grasping to generate massive datasets
of parallel-jaw grasps across thousands of 3D CAD object models. These datasets
are used to train deep neural networks to plan grasps from a point clouds on a
physical robot that can lift and transport a wide variety of objects.
To facilitate reproducibility and future research, this blog post announces the
release of the:
Dexterity Network (Dex-Net) 2.0 dataset: 6.7 million pairs of synthetic point clouds and grasps with robustness labels. [link to data folder]
Grasp Quality CNN (GQ-CNN) model: 18 million parameters trained on the Dex-Net 2.0 dataset. [link to our models]
GQ-CNN Python Package: Code to replicate our GQ-CNN training results on synthetic data (note System Requirements below). [link to code].
In the post, we also summarize the methods behind Dex-Net 2.0 (1), our
experimental results on a real robot, and details on the datasets, models, and
code.
(Joint work with Ronghang Hu, Marcus Rohrbach, Trevor Darrell, Dan Klein and
Kate Saenko.)
Suppose we’re building a household robot, and want it to be able to answer
questions about its surroundings. We might ask questions like these:
How can we ensure that the robot can answer these questions correctly? The
standard approach in deep learning is to collect a large dataset of questions,
images, and answers, and train a single neural network to map directly from
questions and images to answers. If most questions look like the one on the
left, we have a familiar image recognition problem, and these kinds of
monolithic approaches are quite effective:
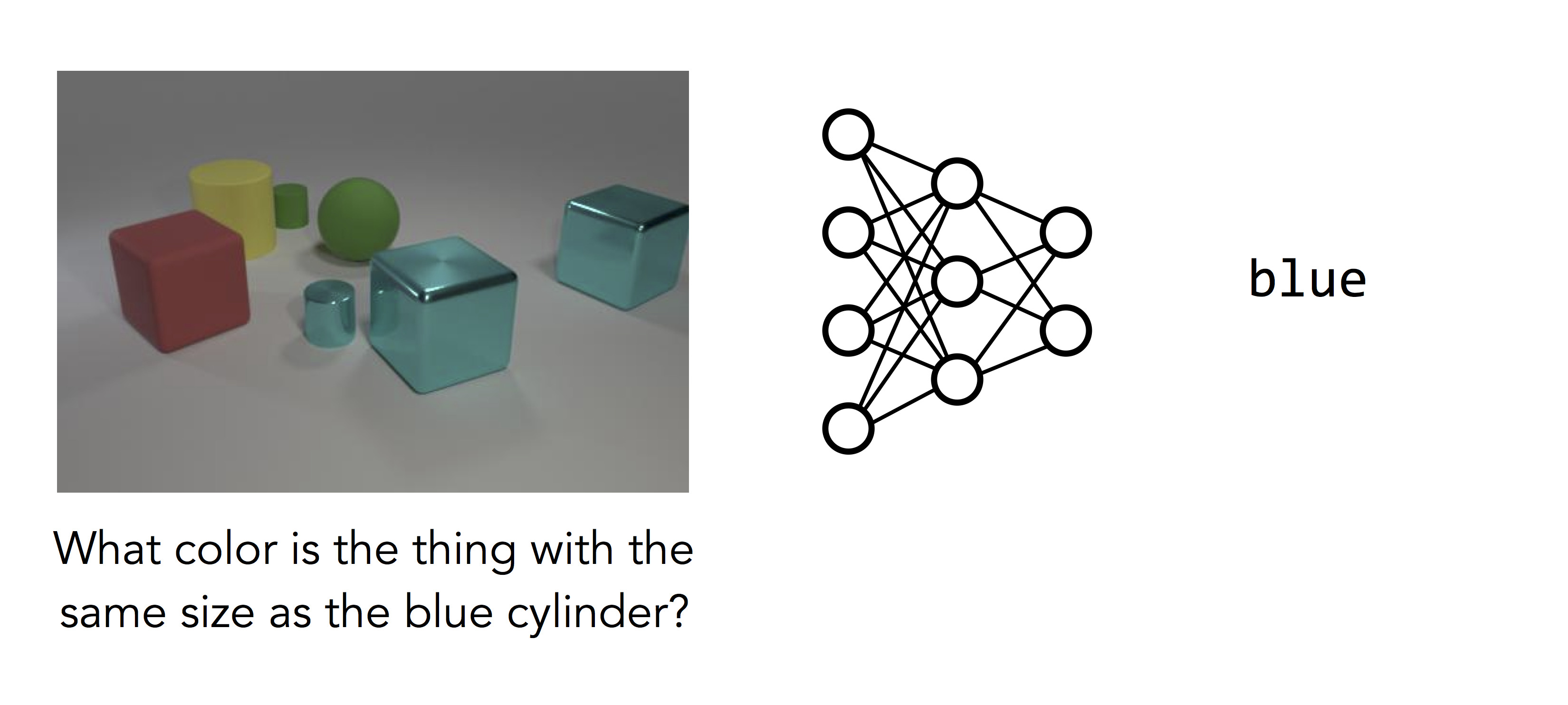
But things don’t work quite so well for questions like the one on the
right:
Here the network we trained has given up and guessed the most common color in
the image. What makes this question so much harder? Even though the image is
cleaner, the question requires many steps of reasoning: rather than
simply recognizing the main object in the image, the model must first find the
blue cylinder, locate the other object with the same size, and then determine
its color. This is a complicated computation, and it’s a computation
specific to the question that was asked. Different questions require
different sequences of steps to solve.
The dominant paradigm in deep learning is a "one size fits all" approach: for
whatever problem we’re trying to solve, we write down a fixed model architecture
that we hope can capture everything about the relationship between the input and
output, and learn parameters for that fixed model from labeled training
data.
But real-world reasoning doesn’t work this way: it involves a variety of
different capabilities, combined and synthesized in new ways for every new
challenge we encounter in the wild. What we need is a model that can
dynamically determine how to reason about the problem in front of it—a
network that can choose its own structure on the fly. In this post, we’ll talk
about a new class of models we call neural module networks
(NMNs), which incorporate this more flexible approach to problem-solving while
preserving the expressive power that makes deep learning so effective.
Berkeley AI Research (BAIR) brings together researchers at UC Berkeley across
the areas of computer vision, machine learning, natural language processing,
planning, and robotics, and each year we publish cutting edge research across
all of these areas. Dissemination of scientific results is a core component of
our mission, and while the traditional avenues for fulfilling this mission –
publications and presentations at academic conferences – continue to be the
primary method for disseminating our results, we must also strive to make our
results accessible, easily interpretable, and available to all. As part of this
effort, we are launching the BAIR Blog, a general audience blog where we will
present and discuss recent results in computer vision, deep learning, robotics,
NLP, and a variety of other areas where BAIR conducts cutting-edge research. Our
aim with the BAIR Blog will be to present recent scientific findings in a format
that is engaging, accessible, but at the same time informative for readers with
all levels of expertise. Our inaugural post describes some recent work at BAIR
at the intersection of vision and natural language processing. Posts on a
variety of other topics will follow on a weekly basis.