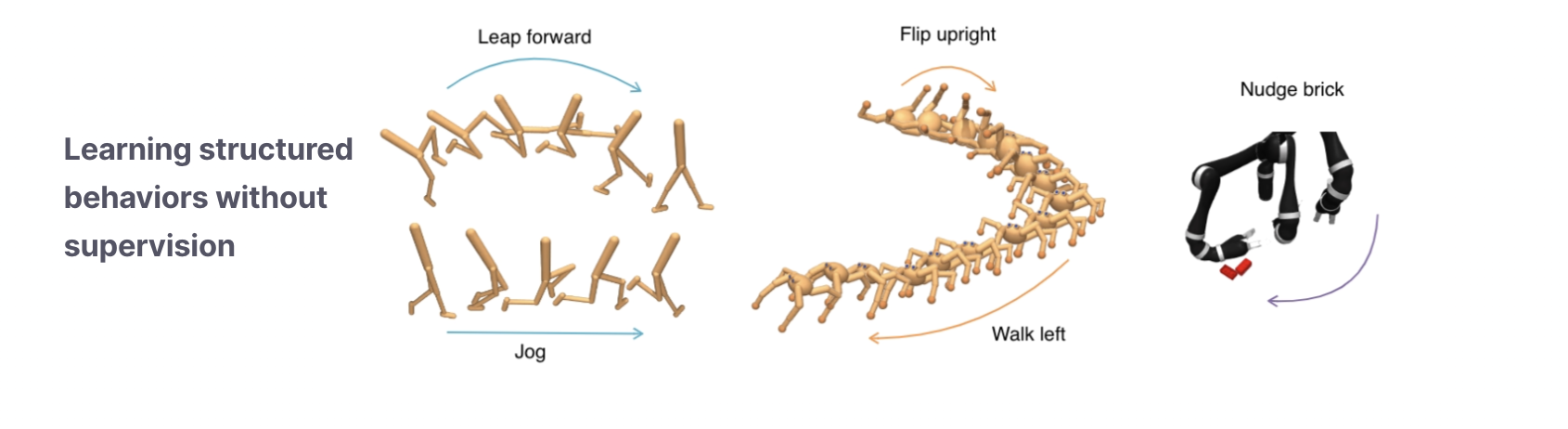
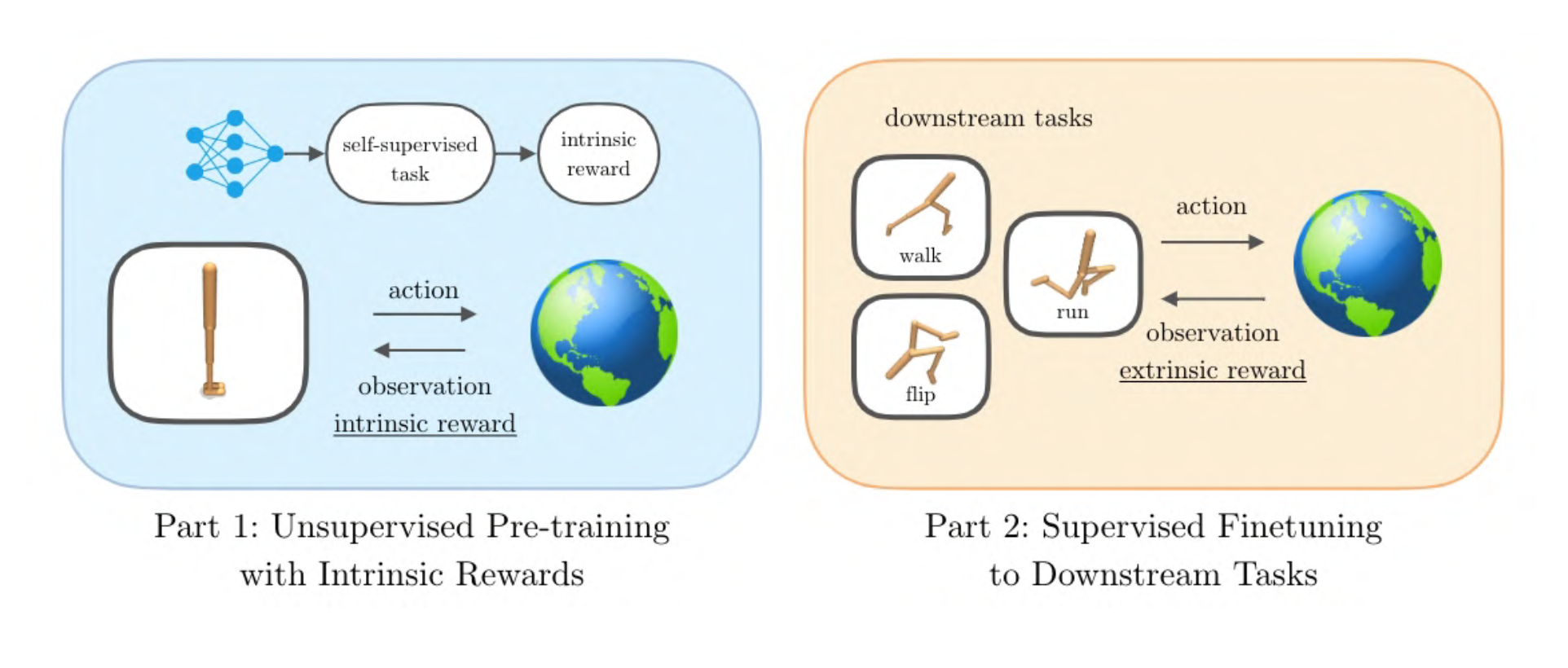
Unsupervised Reinforcement Learning (RL), where RL agents pre-train with self-supervised rewards, is an emerging paradigm for developing RL agents that are capable of generalization. Recently, we released the Unsupervised RL Benchmark (URLB) which we covered in a previous post. URLB benchmarked many unsupervised RL algorithms across three categories — competence-based, knowledge-based, and data-based algorithms. A surprising finding was that competence-based algorithms significantly underperformed other categories. In this post we will demystify what has been holding back competence-based methods and introduce Contrastive Intrinsic Control (CIC), a new competence-based algorithm that is the first to achieve leading results on URLB.
imodels: A python package with cutting-edge techniques for concise, transparent, and accurate predictive modeling. All sklearn-compatible and easy to use.
Recent machine-learning advances have led to increasingly complex predictive models, often at the cost of interpretability. We often need interpretability, particularly in high-stakes applications such as medicine, biology, and political science (see here and here for an overview). Moreover, interpretable models help with all kinds of things, such as identifying errors, leveraging domain knowledge, and speeding up inference.
Despite new advances in formulating/fitting interpretable models, implementations are often difficult to find, use, and compare. imodels (github, paper) fills this gap by providing a simple unified interface and implementation for many state-of-the-art interpretable modeling techniques, particularly rule-based methods.
Reinforcement Learning (RL) is a powerful paradigm for solving many problems of interest in AI, such as controlling autonomous vehicles, digital assistants, and resource allocation to name a few. We’ve seen over the last five years that, when provided with an extrinsic reward function, RL agents can master very complex tasks like playing Go, Starcraft, and dextrous robotic manipulation. While large-scale RL agents can achieve stunning results, even the best RL agents today are narrow. Most RL algorithms today can only solve the single task they were trained on and do not exhibit cross-task or cross-domain generalization capabilities.
A side-effect of the narrowness of today’s RL systems is that today’s RL agents are also very data inefficient. If we were to train AlphaGo-like agents on many tasks each agent would likely require billions of training steps because today’s RL agents don’t have the capabilities to reuse prior knowledge to solve new tasks more efficiently. RL as we know it is supervised - agents overfit to a specific extrinsic reward which limits their ability to generalize.
Sequence Modeling Solutions for Reinforcement Learning Problems
Long-horizon predictions of (top) the Trajectory Transformer compared to those of (bottom) a single-step dynamics model.
Modern machinelearningsuccessstories often have one thing in common: they use methods that scale gracefully with ever-increasing amounts of data.
This is particularly clear from recent advances in sequence modeling, where simply increasing the size of a stable architecture and its training set leads to qualitativelydifferentcapabilities.1
Meanwhile, the situation in reinforcement learning has proven more complicated.
While it has been possible to apply reinforcement learning algorithms to large-scaleproblems, generally there has been much more friction in doing so.
In this post, we explore whether we can alleviate these difficulties by tackling the reinforcement learning problem with the toolbox of sequence modeling.
The end result is a generative model of trajectories that looks like a large language model and a planning algorithm that looks like beam search.
Code for the approach can be found here.
Processing raw sensory inputs is crucial for applying deep RL algorithms to real-world problems.
For example, autonomous vehicles must make decisions about how to drive safely given information flowing from cameras, radar, and microphones about the conditions of the road, traffic signals, and other cars and pedestrians.
However, direct “end-to-end” RL that maps sensor data to actions (Figure 1, left) can be very difficult because the inputs are high-dimensional, noisy, and contain redundant information.
Instead, the challenge is often broken down into two problems (Figure 1, right): (1) extract a representation of the sensory inputs that retains only the relevant information, and (2) perform RL with these representations of the inputs as the system state.
Figure 1. Representation learning can extract compact representations of states for RL.
A wide variety of algorithms have been proposed to learn lossy state representations in an unsupervised fashion (see this recent tutorial for an overview).
Recently, contrastive learning methods have proven effective on RL benchmarks such as Atari and DMControl (Oord et al. 2018, Stooke et al. 2020, Schwarzer et al. 2021), as well as for real-world robotic learning (Zhan et al.).
While we could ask which objectives are better in which circumstances, there is an even more basic question at hand: are the representations learned via these methods guaranteed to be sufficient for control?
In other words, do they suffice to learn the optimal policy, or might they discard some important information, making it impossible to solve the control problem?
For example, in the self-driving car scenario, if the representation discards the state of stoplights, the vehicle would be unable to drive safely.
Surprisingly, we find that some widely used objectives are not sufficient, and in fact do discard information that may be needed for downstream tasks.
Fig. 1: The BRIDGE dataset contains 7200 demonstrations of kitchen-themed manipulation tasks across 71 tasks in 10 domains. Note that any GIF compression artifacts in this animation are not present in the dataset itself.
When we apply robot learning methods to real-world systems, we must usually collect new datasets for every task, every robot, and every environment. This is not only costly and time-consuming, but it also limits the size of the datasets that we can use, and this, in turn, limits generalization: if we train a robot to clean one plate in one kitchen, it is unlikely to succeed at cleaning any plate in any kitchen. In other fields, such as computer vision (e.g., ImageNet) and natural language processing (e.g., BERT), the standard approach to generalization is to utilize large, diverse datasets, which are collected once and then reused repeatedly. Since the dataset is reused for many models, tasks, and domains, the up-front cost of collecting such large reusable datasets is worth the benefits. Thus, to obtain truly generalizable robotic behaviors, we may need large and diverse datasets, and the only way to make this practical is to reuse data across many different tasks, environments, and labs (i.e. different background lighting conditions, etc.).
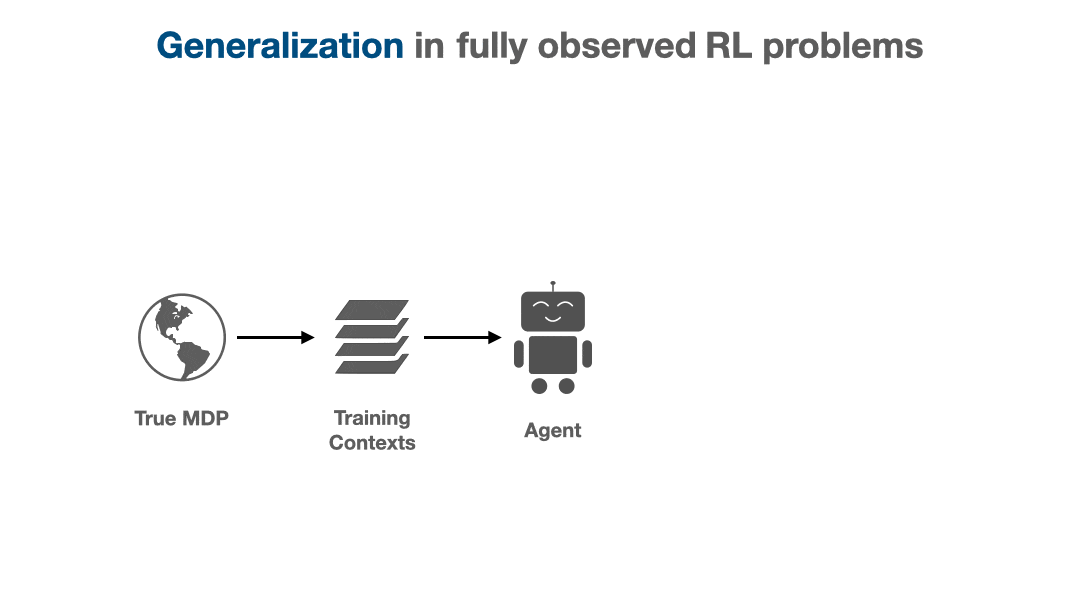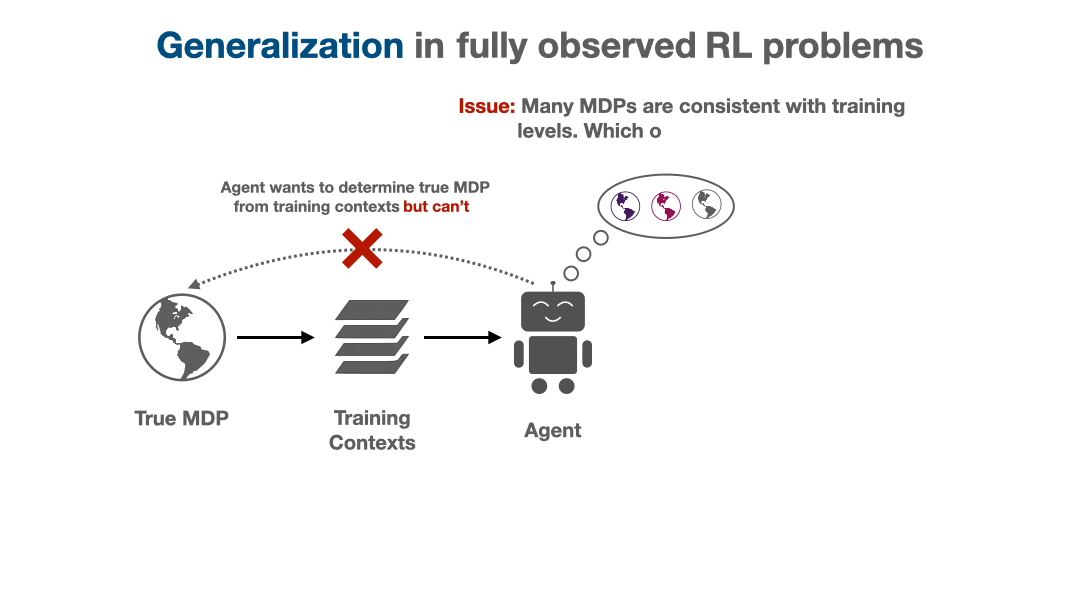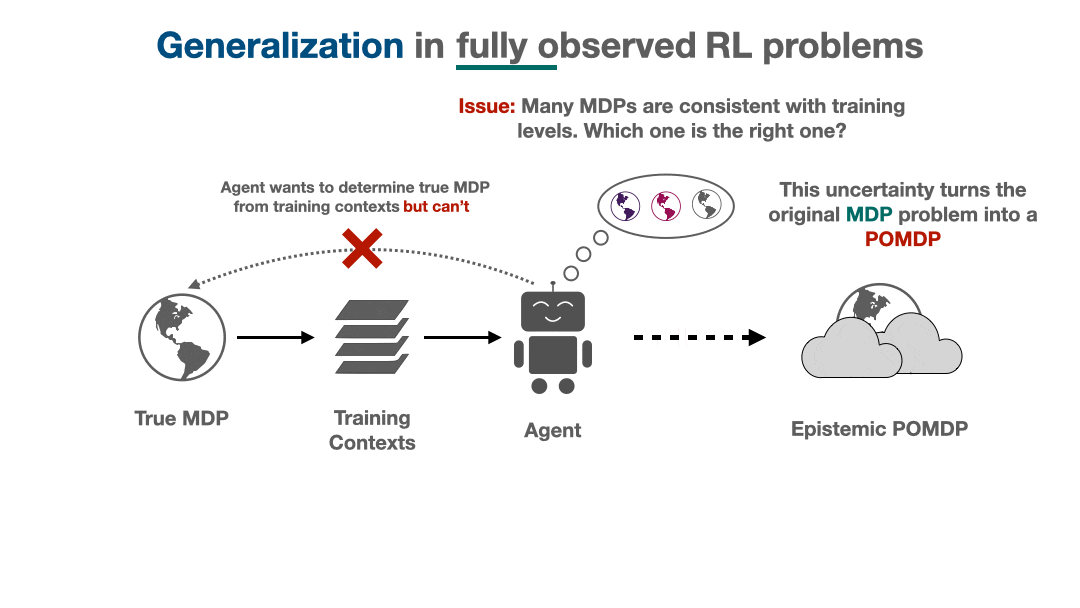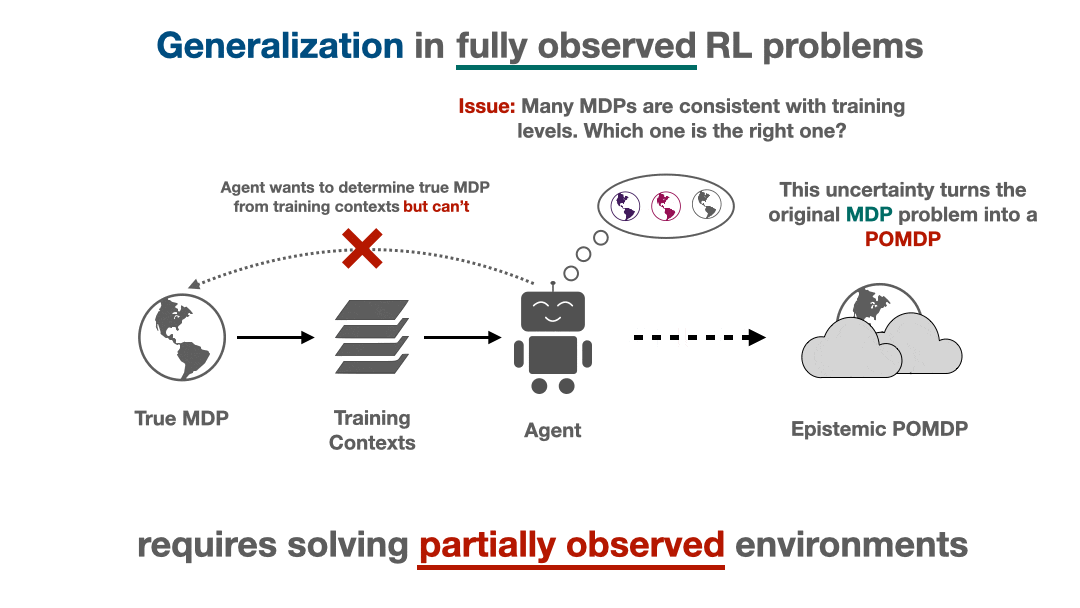
Many experimental works have observed that generalization in deep RL appears to be difficult: although RL agents can learn to perform very complex tasks, they don’t seem to generalize over diverse task distributions as well as the excellent generalization of supervised deep nets might lead us to expect. In this blog post, we will aim to explain why generalization in RL is fundamentally harder, and indeed more difficult even in theory.
We will show that attempting to generalize in RL induces implicit partial observability, even when the RL problem we are trying to solve is a standard fully-observed MDP. This induced partial observability can significantly complicate the types of policies needed to generalize well, potentially requiring counterintuitive strategies like information-gathering actions, recurrent non-Markovian behavior, or randomized strategies. Ordinarily, this is not necessary in fully observed MDPs but surprisingly becomes necessary when we consider generalization from a finite training set in a fully observed MDP. This blog post will walk through why partial observability can implicitly arise, what it means for the generalization performance of RL algorithms, and how methods can account for partial observability to generalize well.
An example of our method deployed on a Clearpath Jackal ground robot (left) exploring a suburban environment to find a visual target (inset). (Right) Egocentric observations of the robot.
Imagine you’re in an unfamiliar neighborhood with no house numbers and I give you a photo that I took a few days ago of my house, which is not too far away. If you tried to find my house, you might follow the streets and go around the block looking for it. You might take a few wrong turns at first, but eventually you would locate my house. In the process, you would end up with a mental map of my neighborhood. The next time you’re visiting, you will likely be able to navigate to my house right away, without taking any wrong turns.
Such exploration and navigation behavior is easy for humans. What would it take for a robotic learning algorithm to enable this kind of intuitive navigation capability? To build a robot capable of exploring and navigating like this, we need to learn from diverse prior datasets in the real world. While it’s possible to collect a large amount of data from demonstrations, or even with randomized exploration, learning meaningful exploration and navigation behavior from this data can be challenging – the robot needs to generalize to unseen neighborhoods, recognize visual and dynamical similarities across scenes, and learn a representation of visual observations that is robust to distractors like weather conditions and obstacles. Since such factors can be hard to model and transfer from simulated environments, we tackle these problems by teaching the robot to explore using only real-world data.