As computer vision researchers, we believe that every pixel can tell a story. However, there seems to be a writer’s block settling into the field when it comes to dealing with large images. Large images are no longer rare—the cameras we carry in our pockets and those orbiting our planet snap pictures so big and detailed that they stretch our current best models and hardware to their breaking points when handling them. Generally, we face a quadratic increase in memory usage as a function of image size.
Today, we make one of two sub-optimal choices when handling large images: down-sampling or cropping. These two methods incur significant losses in the amount of information and context present in an image. We take another look at these approaches and introduce $x$T, a new framework to model large images end-to-end on contemporary GPUs while effectively aggregating global context with local details.
Every year, the Berkeley Artificial Intelligence Research (BAIR) Lab graduates some of the most talented and innovative minds in artificial intelligence and machine learning. Our Ph.D. graduates have each expanded the frontiers of AI research and are now ready to embark on new adventures in academia, industry, and beyond.
These fantastic individuals bring with them a wealth of knowledge, fresh ideas, and a drive to continue contributing to the advancement of AI. Their work at BAIR, ranging from deep learning, robotics, and natural language processing to computer vision, security, and much more, has contributed significantly to their fields and has had transformative impacts on society.
This website is dedicated to showcasing our colleagues, making it easier for academic institutions, research organizations, and industry leaders to discover and recruit from the newest generation of AI pioneers. Here, you’ll find detailed profiles, research interests, and contact information for each of our graduates. We invite you to explore the potential collaborations and opportunities these graduates present as they seek to apply their expertise and insights in new environments.
Join us in celebrating the achievements of BAIR’s latest PhD graduates. Their journey is just beginning, and the future they will help build is bright!
AI caught everyone’s attention in 2023 with Large Language Models (LLMs) that can be instructed to perform general tasks, such as translation or coding, just by prompting. This naturally led to an intense focus on models as the primary ingredient in AI application development, with everyone wondering what capabilities new LLMs will bring.
As more developers begin to build using LLMs, however, we believe that this focus is rapidly changing: state-of-the-art AI results are increasingly obtained by compound systems with multiple components, not just monolithic models.
For example, Google’s AlphaCode 2 set state-of-the-art results in programming through a carefully engineered system that uses LLMs to generate up to 1 million possible solutions for a task and then filter down the set. AlphaGeometry, likewise, combines an LLM with a traditional symbolic solver to tackle olympiad problems. In enterprises, our colleagues at Databricks found that 60% of LLM applications use some form of retrieval-augmented generation (RAG), and 30% use multi-step chains.
Even researchers working on traditional language model tasks, who used to report results from a single LLM call, are now reporting results from increasingly complex inference strategies: Microsoft wrote about a chaining strategy that exceeded GPT-4’s accuracy on medical exams by 9%, and Google’s Gemini launch post measured its MMLU benchmark results using a new CoT@32 inference strategy that calls the model 32 times, which raised questions about its comparison to just a single call to GPT-4. This shift to compound systems opens many interesting design questions, but it is also exciting, because it means leading AI results can be achieved through clever engineering, not just scaling up training.
In this post, we analyze the trend toward compound AI systems and what it means for AI developers. Why are developers building compound systems? Is this paradigm here to stay as models improve? And what are the emerging tools for developing and optimizing such systems—an area that has received far less research than model training? We argue that compound AI systems will likely be the best way to maximize AI results in the future, and might be one of the most impactful trends in AI in 2024.
The structure of Ghostbuster, our new state-of-the-art method for detecting AI-generated text.
Large language models like ChatGPT write impressively well—so well, in fact, that they’ve become a problem. Students have begun using these models to ghostwrite assignments, leading some schools to ban ChatGPT. In addition, these models are also prone to producing text with factual errors, so wary readers may want to know if generative AI tools have been used to ghostwrite news articles or other sources before trusting them.
What can teachers and consumers do? Existing tools to detect AI-generated text sometimes do poorly on data that differs from what they were trained on. In addition, if these models falsely classify real human writing as AI-generated, they can jeopardize students whose genuine work is called into question.
Our recent paper introduces Ghostbuster, a state-of-the-art method for detecting AI-generated text. Ghostbuster works by finding the probability of generating each token in a document under several weaker language models, then combining functions based on these probabilities as input to a final classifier. Ghostbuster doesn’t need to know what model was used to generate a document, nor the probability of generating the document under that specific model. This property makes Ghostbuster particularly useful for detecting text potentially generated by an unknown model or a black-box model, such as the popular commercial models ChatGPT and Claude, for which probabilities aren’t available. We’re particularly interested in ensuring that Ghostbuster generalizes well, so we evaluated across a range of ways that text could be generated, including different domains (using newly collected datasets of essays, news, and stories), language models, or prompts.
Asymmetric Certified Robustness via Feature-Convex Neural Networks
TLDR: We propose the asymmetric certified robustness problem, which requires certified robustness for only one class and reflects real-world adversarial scenarios. This focused setting allows us to introduce feature-convex classifiers, which produce closed-form and deterministic certified radii on the order of milliseconds.
Figure 1. Illustration of feature-convex classifiers and their certification for sensitive-class inputs. This architecture composes a Lipschitz-continuous feature map $\varphi$ with a learned convex function $g$. Since $g$ is convex, it is globally underapproximated by its tangent plane at $\varphi(x)$, yielding certified norm balls in the feature space. Lipschitzness of $\varphi$ then yields appropriately scaled certificates in the original input space.
Despite their widespread usage, deep learning classifiers are acutely vulnerable to adversarial examples: small, human-imperceptible image perturbations that fool machine learning models into misclassifying the modified input. This weakness severely undermines the reliability of safety-critical processes that incorporate machine learning. Many empirical defenses against adversarial perturbations have been proposed—often only to be later defeated by stronger attack strategies. We therefore focus on certifiably robust classifiers, which provide a mathematical guarantee that their prediction will remain constant for an $\ell_p$-norm ball around an input.
Conventional certified robustness methods incur a range of drawbacks, including nondeterminism, slow execution, poor scaling, and certification against only one attack norm. We argue that these issues can be addressed by refining the certified robustness problem to be more aligned with practical adversarial settings.
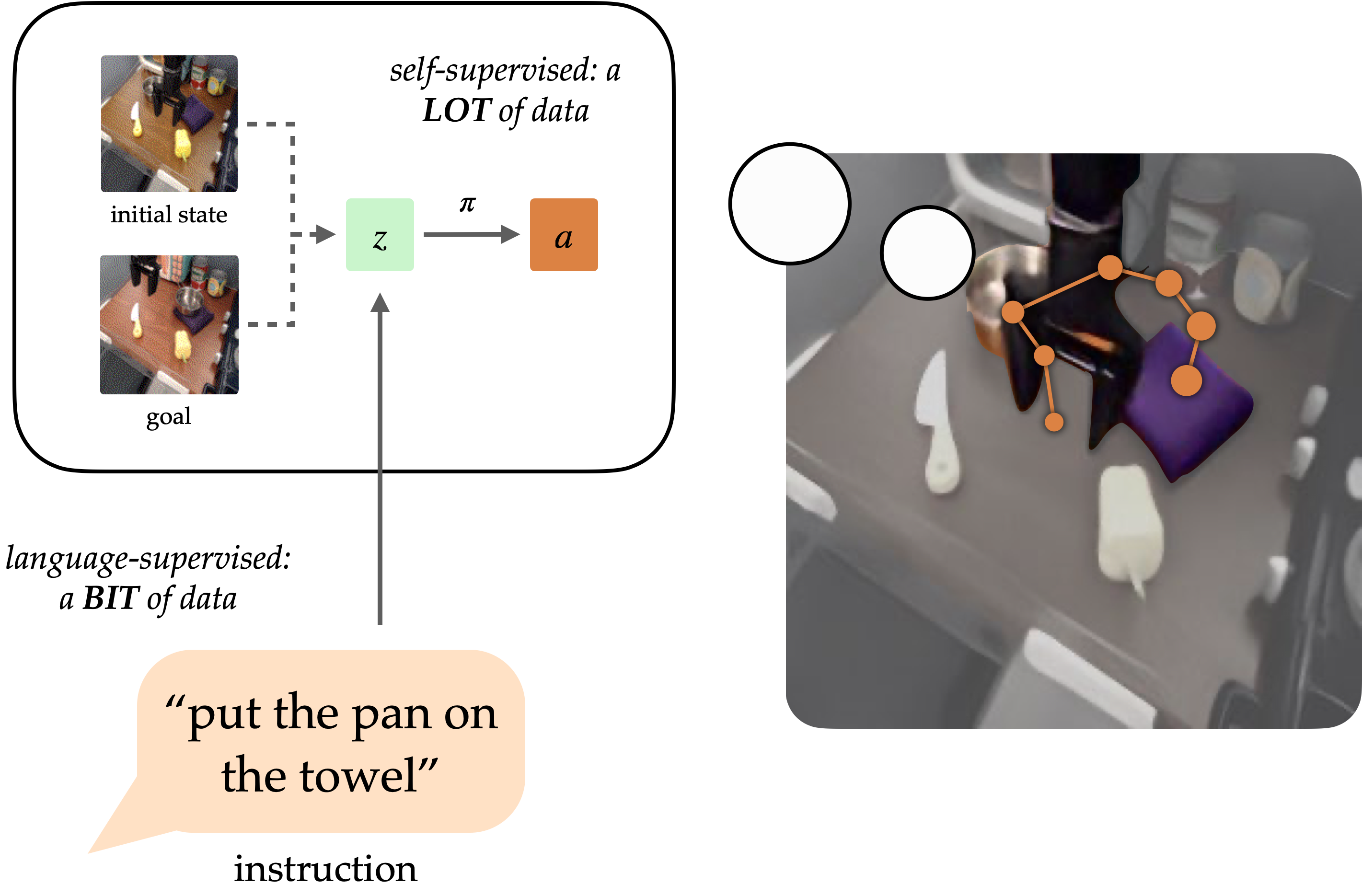
A longstanding goal of the field of robot learning has been to create generalist agents that can perform tasks for humans. Natural language has the potential to be an easy-to-use interface for humans to specify arbitrary tasks, but it is difficult to train robots to follow language instructions. Approaches like language-conditioned behavioral cloning (LCBC) train policies to directly imitate expert actions conditioned on language, but require humans to annotate all training trajectories and generalize poorly across scenes and behaviors. Meanwhile, recent goal-conditioned approaches perform much better at general manipulation tasks, but do not enable easy task specification for human operators. How can we reconcile the ease of specifying tasks through LCBC-like approaches with the performance improvements of goal-conditioned learning?
TL;DR: In RLHF, there’s tension between the reward learning phase, which uses human preference in the form of comparisons, and the RL fine-tuning phase, which optimizes a single, non-comparative reward. What if we performed RL in a comparative way?
Figure 1:
This diagram illustrates the difference between reinforcement learning from absolute feedback and relative feedback. By incorporating a new component - pairwise policy gradient, we can unify the reward modeling stage and RL stage, enabling direct updates based on pairwise responses.
Large Language Models (LLMs) have powered increasingly capable virtual assistants, such as GPT-4, Claude-2, Bard and Bing Chat. These systems can respond to complex user queries, write code, and even produce poetry. The technique underlying these amazing virtual assistants is Reinforcement Learning with Human Feedback (RLHF). RLHF aims to align the model with human values and eliminate unintended behaviors, which can often arise due to the model being exposed to a large quantity of low-quality data during its pretraining phase.
Proximal Policy Optimization (PPO), the dominant RL optimizer in this process, has been reported to exhibit instability and implementation complications. More importantly, there’s a persistent discrepancy in the RLHF process: despite the reward model being trained using comparisons between various responses, the RL fine-tuning stage works on individual responses without making any comparisons. This inconsistency can exacerbate issues, especially in the challenging language generation domain.
Given this backdrop, an intriguing question arises: Is it possible to design an RL algorithm that learns in a comparative manner? To explore this, we introduce Pairwise Proximal Policy Optimization (P3O), a method that harmonizes the training processes in both the reward learning stage and RL fine-tuning stage of RLHF, providing a satisfactory solution to this issue.
Training Diffusion Models with Reinforcement Learning
replay
Diffusion models have recently emerged as the de facto standard for generating complex, high-dimensional outputs. You may know them for their ability to produce stunning AI art and hyper-realistic synthetic images, but they have also found success in other applications such as drug design and continuous control. The key idea behind diffusion models is to iteratively transform random noise into a sample, such as an image or protein structure. This is typically motivated as a maximum likelihood estimation problem, where the model is trained to generate samples that match the training data as closely as possible.
However, most use cases of diffusion models are not directly concerned with matching the training data, but instead with a downstream objective. We don’t just want an image that looks like existing images, but one that has a specific type of appearance; we don’t just want a drug molecule that is physically plausible, but one that is as effective as possible. In this post, we show how diffusion models can be trained on these downstream objectives directly using reinforcement learning (RL). To do this, we finetune Stable Diffusion on a variety of objectives, including image compressibility, human-perceived aesthetic quality, and prompt-image alignment. The last of these objectives uses feedback from a large vision-language model to improve the model’s performance on unusual prompts, demonstrating how powerful AI models can be used to improve each other without any humans in the loop.
Figure 1: stepwise behavior in self-supervised learning. When training common SSL algorithms, we find that the loss descends in a stepwise fashion (top left) and the learned embeddings iteratively increase in dimensionality (bottom left). Direct visualization of embeddings (right; top three PCA directions shown) confirms that embeddings are initially collapsed to a point, which then expands to a 1D manifold, a 2D manifold, and beyond concurrently with steps in the loss.
It is widely believed that deep learning’s stunning success is due in part to its ability to discover and extract useful representations of complex data. Self-supervised learning (SSL) has emerged as a leading framework for learning these representations for images directly from unlabeled data, similar to how LLMs learn representations for language directly from web-scraped text. Yet despite SSL’s key role in state-of-the-art models such as CLIP and MidJourney, fundamental questions like “what are self-supervised image systems really learning?” and “how does that learning actually occur?” lack basic answers.
Our recent paper (to appear at ICML 2023) presents what we suggest is the first compelling mathematical picture of the training process of large-scale SSL methods. Our simplified theoretical model, which we solve exactly, learns aspects of the data in a series of discrete, well-separated steps. We then demonstrate that this behavior can be observed in the wild across many current state-of-the-art systems.
This discovery opens new avenues for improving SSL methods, and enables a whole range of new scientific questions that, when answered, will provide a powerful lens for understanding some of today’s most important deep learning systems.
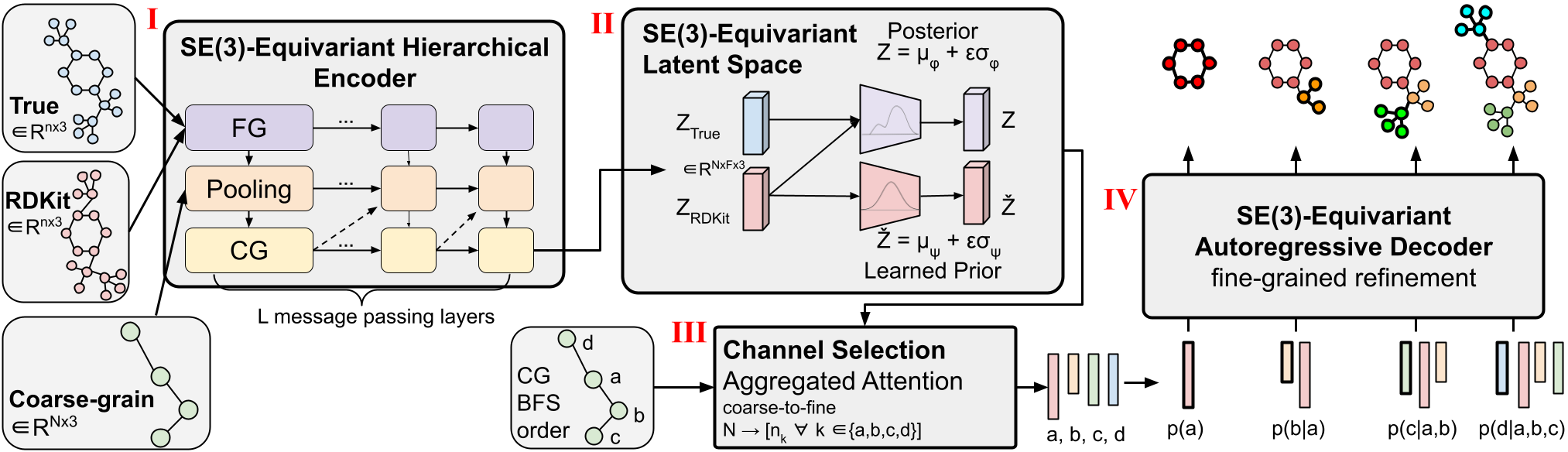
Molecular conformer generation is a fundamental task in computational chemistry. The objective is to predict stable low-energy 3D molecular structures, known as conformers, given the 2D molecule. Accurate molecular conformations are crucial for various applications that depend on precise spatial and geometric qualities, including drug discovery and protein docking.
We introduce CoarsenConf, an SE(3)-equivariant hierarchical variational autoencoder (VAE) that pools information from fine-grain atomic coordinates to a coarse-grain subgraph level representation for efficient autoregressive conformer generation.