Humans excel at processing vast arrays of visual information, a skill that is crucial for achieving artificial general intelligence (AGI). Over the decades, AI researchers have developed Visual Question Answering (VQA) systems to interpret scenes within single images and answer related questions. While recent advancements in foundation models have significantly closed the gap between human and machine visual processing, conventional VQA has been restricted to reason about only single images at a time rather than whole collections of visual data.
This limitation poses challenges in more complex scenarios. Take, for example, the challenges of discerning patterns in collections of medical images, monitoring deforestation through satellite imagery, mapping urban changes using autonomous navigation data, analyzing thematic elements across large art collections, or understanding consumer behavior from retail surveillance footage. Each of these scenarios entails not only visual processing across hundreds or thousands of images but also necessitates cross-image processing of these findings. To address this gap, this project focuses on the “Multi-Image Question Answering” (MIQA) task, which exceeds the reach of traditional VQA systems.

Visual Haystacks: the first "visual-centric" Needle-In-A-Haystack (NIAH) benchmark designed to rigorously evaluate Large Multimodal Models (LMMs) in processing long-context visual information.
How to Benchmark VQA Models on MIQA?
The “Needle-In-A-Haystack” (NIAH) challenge has recently become one of the most popular paradigms for benchmarking LLM’s ability to process inputs containing “long contexts”, large sets of input data (such as long documents, videos, or hundreds of images). In this task, essential information (“the needle”), which contains the answer to a specific question, is embedded within a vast amount of data (“the haystack”). The system must then retrieve the relevant information and answer the question correctly.
The first NIAH benchmark for visual reasoning was introduced by Google in the Gemini-v1.5 technical report. In this report, they asked their models to retrieve text overlaid on a single frame in a large video. It turns out that existing models perform quite well on this task—primarily due to their strong OCR retrieval capabilities. But what if we ask more visual questions? Do models still perform as well?
What is the Visual Haystacks (VHs) Benchmark?
In pursuit of evaluating “visual-centric” long-context reasoning capabilities, we introduce the “Visual Haystacks (VHs)” benchmark. This new benchmark is designed to assess Large Multimodal Models (LMMs) in visual retrieval and reasoning across large uncorrelated image sets. VHs features approximately 1K binary question-answer pairs, with each set containing anywhere from 1 to 10K images. Unlike previous benchmarks that focused on textual retrieval and reasoning, VHs questions center on identifying the presence of specific visual content, such as objects, utilizing images and annotations from the COCO dataset.
The VHs benchmark is divided into two main challenges, each designed to test the model’s ability to accurately locate and analyze relevant images before responding to queries. We have carefully designed the dataset to ensure that guessing or relying on common sense reasoning without viewing the image won’t get any advantages (i.e., resulting in a 50% accuracy rate on a binary QA task).
-
Single-Needle Challenge: Only a single needle image exists in the haystack of images. The question is framed as, “For the image with the anchor object, is there a target object?”
-
Multi-Needle Challenge: Two to five needle images exist in the haystack of images. The question is framed as either, “For all images with the anchor object, do all of them contain the target object?” or “For all images with the anchor object, do any of them contain the target object?”
Three Important Findings from VHs
The Visual Haystacks (VHs) benchmark reveals significant challenges faced by current Large Multimodal Models (LMMs) when processing extensive visual inputs. In our experiments1 across both single and multi-needle modes, we evaluated several open-source and proprietary methods including LLaVA-v1.5, GPT-4o, Claude-3 Opus, and Gemini-v1.5-pro. Additionally, we include a “Captioning” baseline, employing a two-stage approach where images are initially captioned using LLaVA, followed by answering the question using the captions’ text content with Llama3. Below are three pivotal insights:
-
Struggles with Visual Distractors
In single-needle settings, a notable decline in performance was observed as the number of images increased, despite maintaining high oracle accuracy—a scenario absent in prior text-based Gemini-style benchmarks. This shows that existing models may mainly struggle with visual retrieval, especially in the presence of challenging visual distractors. Furthermore, it’s crucial to highlight the constraints on open-source LMMs like LLaVA, which can handle only up to three images due to a 2K context length limit. On the other hand, proprietary models such as Gemini-v1.5 and GPT-4o, despite their claims of extended context capabilities, often fail to manage requests when the image count exceeds 1K, due to payload size limits when using the API call.
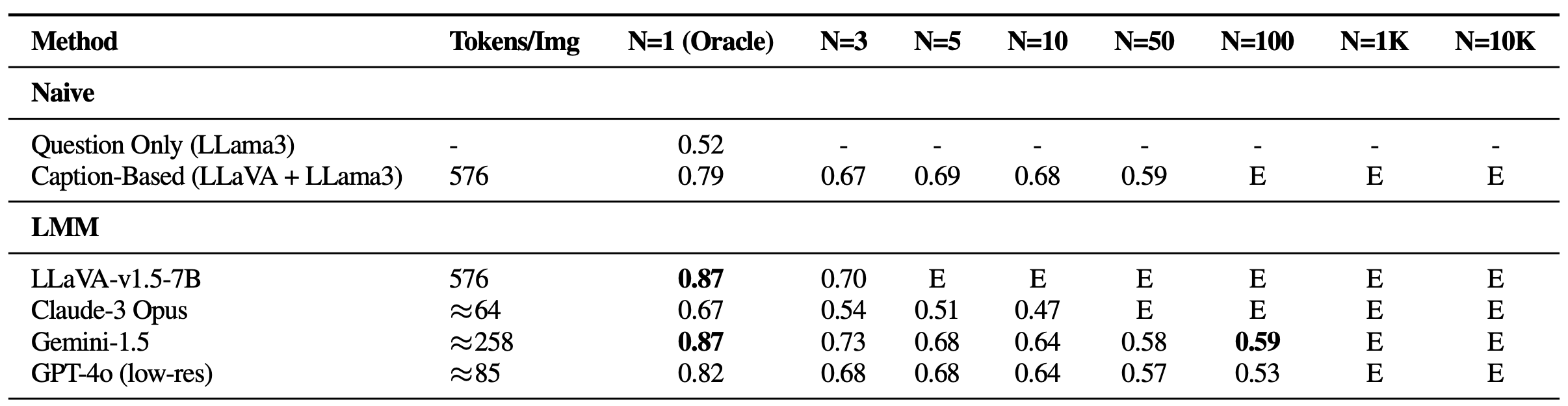
Performance on VHs for single-needle questions. All models experience significant falloff as the size of the haystack (N) increases, suggesting none of them are robust against visual distractors. E: Exceeds context length. -
Difficulty Reasoning Across Multiple Images
Interestingly, all LMM-based methods showed weak performance with 5+ images in single-image QA and all multi-needle settings compared to a basic approach chaining a captioning model (LLaVA) with an LLM aggregator (Llama3). This discrepancy suggests that while LLMs are capable of integrating long-context captions effectively, existing LMM-based solutions are inadequate for processing and integrating information across multiple images. Notably, the performance hugely deteriorates in multi-image scenarios, with Claude-3 Opus showing weak results with only oracle images, and Gemini-1.5/GPT-4o dropping to 50% accuracy (just like a random guess) with larger sets of 50 images.

Results on VHs for multi-needle questions. All visually-aware models perform poorly, indicating that models find it challenging to implicitly integrate visual information. -
Phenomena in Visual Domain
Finally, we found that the accuracy of LMMs is hugely affected by the position of the needle image within the input sequence. For instance, LLaVA shows better performance when the needle image is placed immediately before the question, suffering up to a 26.5% drop otherwise. In contrast, proprietary models generally perform better when the image is positioned at the start, experiencing up to a 28.5% decrease when not. This pattern echoes the “lost-in-the-middle” phenomenon seen in the field of Natural Language Processing (NLP), where crucial information positioned at the beginning or end of the context influences model performance. This issue was not evident in previous Gemini-style NIAH evaluation, which only required text retrieval and reasoning, underscoring the unique challenges posed by our VHs benchmark.
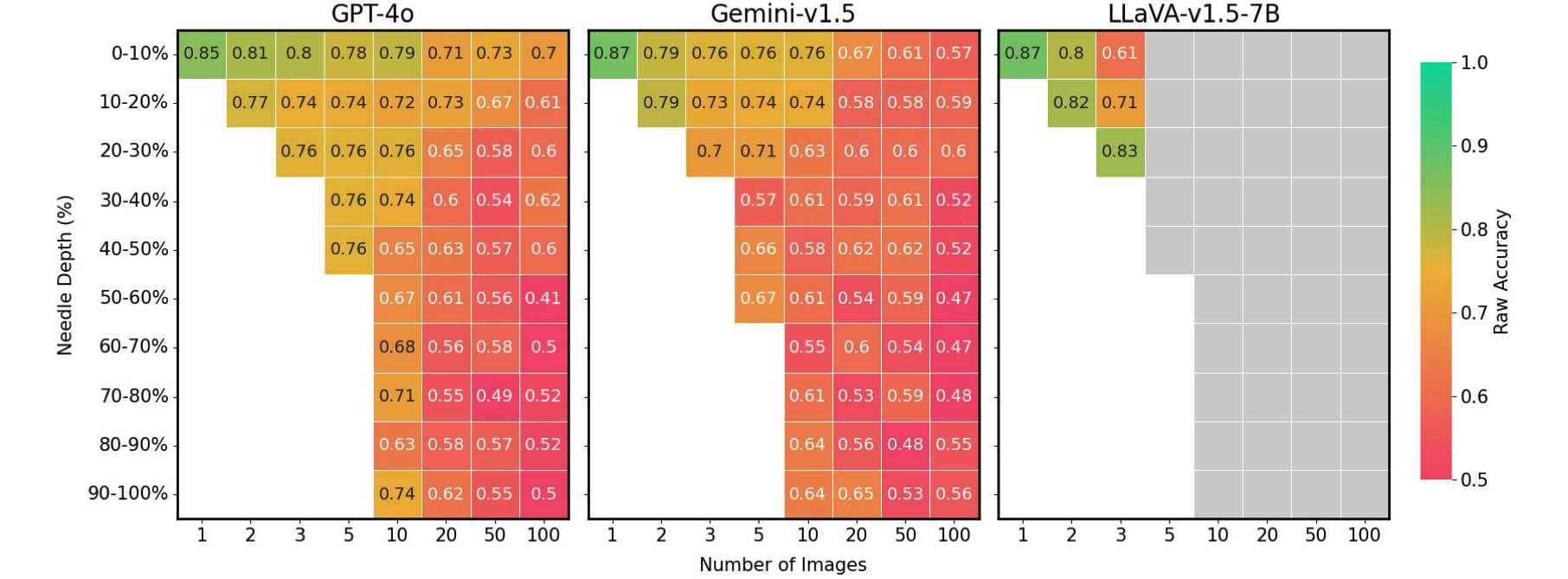
Needle position vs. performance on VHs for various image settings. Existing LMMs show up to 41% performance drop when the needle is not ideally placed. Gray boxes: Exceeds context length.
MIRAGE: A RAG-based Solution for Improved VHs Performance
Based on the experimental results above, it is clear that the core challenges of existing solutions in MIQA lie in the ability to (1) accurately retrieve relevant images from a vast pool of potentially unrelated images without positional biases and (2) integrate relevant visual information from these images to correctly answer the question. To address these issues, we introduce an open-source and simple single-stage training paradigm, “MIRAGE” (Multi-Image Retrieval Augmented Generation), which extends the LLaVA model to handle MIQA tasks. The image below shows our model architecture.
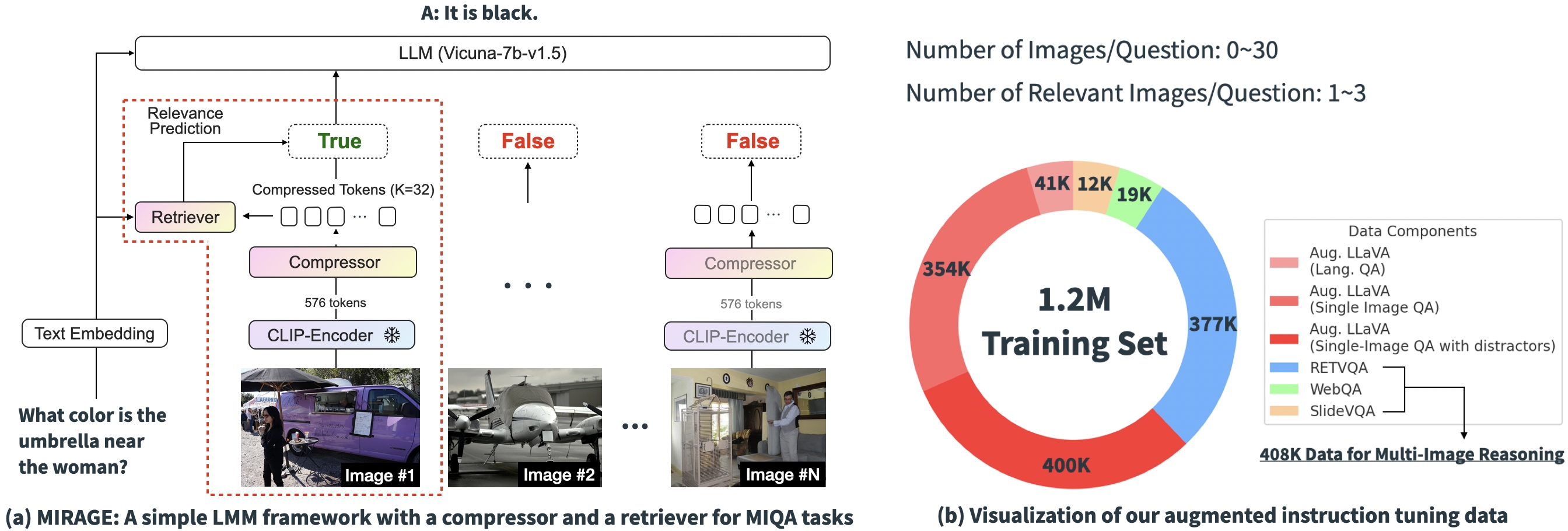
Our proposed paradigm consists of several components, each designed to alleviate key issues in the MIQA task:
-
Compress existing encodings: The MIRAGE paradigm leverages a query-aware compression model to reduce the visual encoder tokens to a smaller subset (10x smaller), allowing for more images in the same context length.
-
Employ retriever to filter out irrelevant message: MIRAGE uses a retriever trained in-line with the LLM fine-tuning, to predict if an image will be relevant, and dynamically drop irrelevant images.
-
Multi-Image Training Data: MIRAGE augments existing single-image instruction fine-tuning data with multi-image reasoning data, and synthetic multi-image reasoning data.
Results
We revisit the VHs benchmark with MIRAGE. In addition to being capable of handling 1K or 10K images, MIRAGE achieves state-of-the-art performance on most single-needle tasks, despite having a weaker single-image QA backbone with only 32 tokens per image!
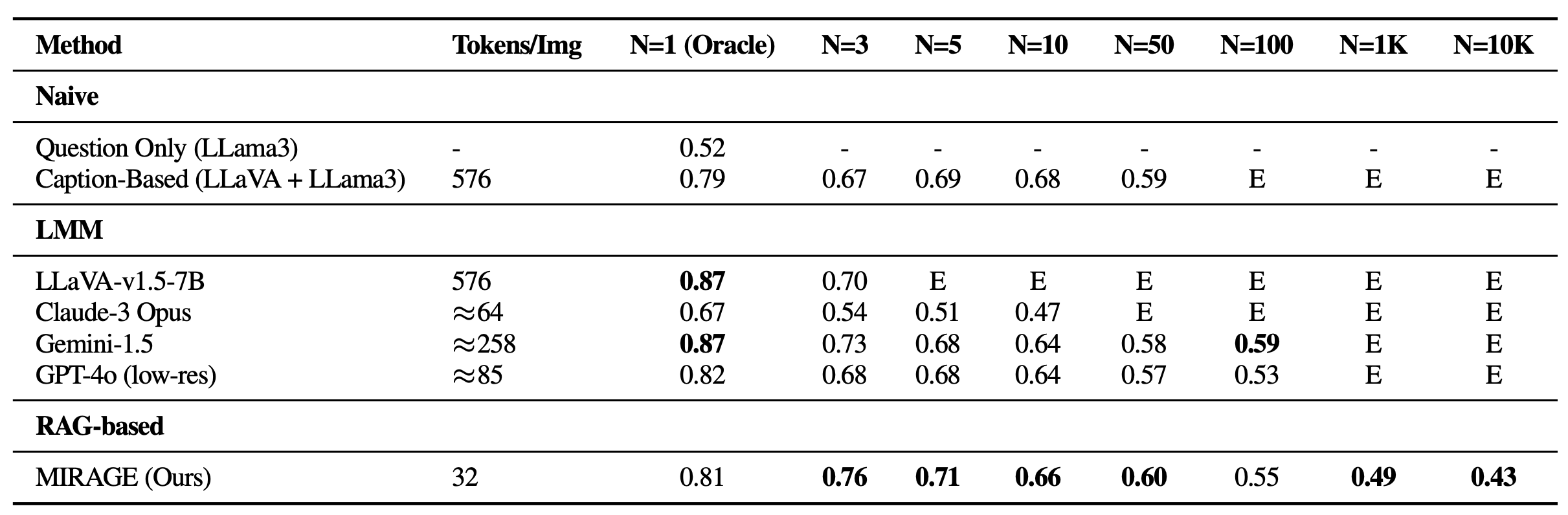
We also benchmark MIRAGE and other LMM-based models on a variety of VQA tasks. On multi-image tasks, MIRAGE demonstrates strong recall and precision capabilities, significantly outperforming strong competitors like GPT-4, Gemini-v1.5, and the Large World Model (LWM). Additionally, it shows competitive single-image QA performance.
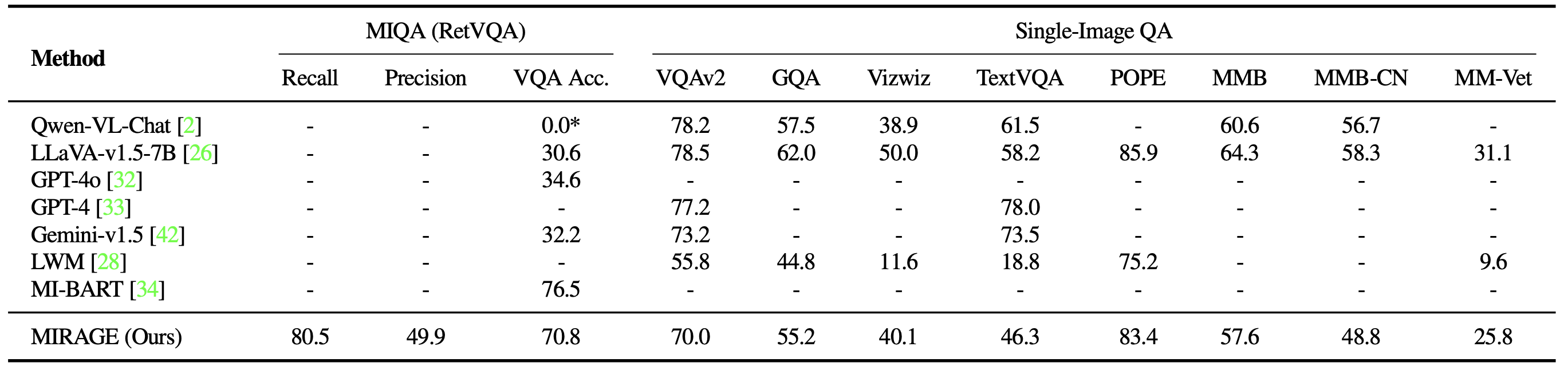
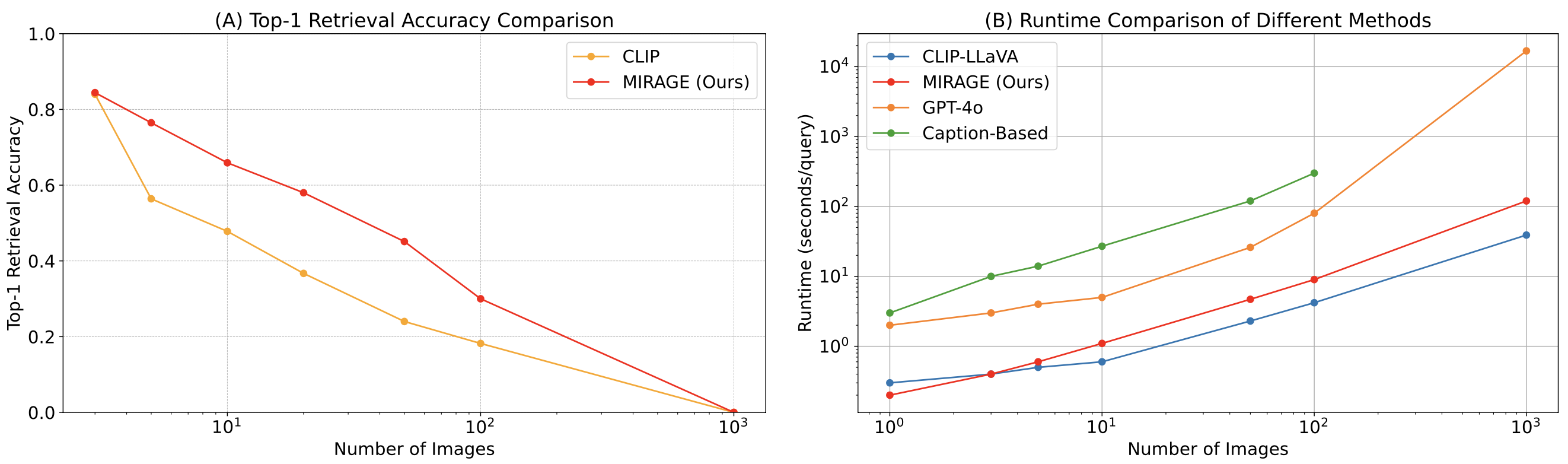
Finally, we compare MIRAGE’s co-trained retriever with CLIP. Our retriever performs significantly better than CLIP without losing efficiency. This shows that while CLIP models can be good retrievers for open-vocabulary image retrieval, they may not work well when dealing with question-like texts!
Final Remarks
In this work, we develop the Visual Haystacks (VHs) benchmark and identified three prevalent deficiencies in existing Large Multimodal Models (LMMs):
-
Struggles with Visual Distractors: In single-needle tasks, LMMs exhibit a sharp performance decline as the number of images increases, indicating a significant challenge in filtering out irrelevant visual information.
-
Difficulty Reasoning Across Multiple Images: In multi-needle settings, simplistic approaches like captioning followed by language-based QA outperform all existing LMMs, highlighting LMMs’ inadequate ability to process information across multiple images.
-
Phenomena in Visual Domain: Both proprietary and open-source models display sensitivity to the position of the needle information within image sequences, exhibiting a “loss-in-the-middle” phenomenon in the visual domain.
In response, we propose MIRAGE, a pioneering visual Retriever-Augmented Generator (visual-RAG) framework. MIRAGE addresses these challenges with an innovative visual token compressor, a co-trained retriever, and augmented multi-image instruction tuning data.
After exploring this blog post, we encourage all future LMM projects to benchmark their models using the Visual Haystacks framework to identify and rectify potential deficiencies before deployment. We also urge the community to explore multi-image question answering as a means to advance the frontiers of true Artificial General Intelligence (AGI).
Last but not least, please check out our project page, and arxiv paper, and click the star button in our github repo!
@article{wu2024visual,
title={Visual Haystacks: Answering Harder Questions About Sets of Images},
author={Wu, Tsung-Han and Biamby, Giscard and and Quenum, Jerome and Gupta, Ritwik and Gonzalez, Joseph E and Darrell, Trevor and Chan, David M},
journal={arXiv preprint arXiv:2407.13766},
year={2024}
}