TLDR: We propose the asymmetric certified robustness problem, which requires certified robustness for only one class and reflects real-world adversarial scenarios. This focused setting allows us to introduce feature-convex classifiers, which produce closed-form and deterministic certified radii on the order of milliseconds.

Figure 1. Illustration of feature-convex classifiers and their certification for sensitive-class inputs. This architecture composes a Lipschitz-continuous feature map $\varphi$ with a learned convex function $g$. Since $g$ is convex, it is globally underapproximated by its tangent plane at $\varphi(x)$, yielding certified norm balls in the feature space. Lipschitzness of $\varphi$ then yields appropriately scaled certificates in the original input space.
Despite their widespread usage, deep learning classifiers are acutely vulnerable to adversarial examples: small, human-imperceptible image perturbations that fool machine learning models into misclassifying the modified input. This weakness severely undermines the reliability of safety-critical processes that incorporate machine learning. Many empirical defenses against adversarial perturbations have been proposed—often only to be later defeated by stronger attack strategies. We therefore focus on certifiably robust classifiers, which provide a mathematical guarantee that their prediction will remain constant for an $\ell_p$-norm ball around an input.
Conventional certified robustness methods incur a range of drawbacks, including nondeterminism, slow execution, poor scaling, and certification against only one attack norm. We argue that these issues can be addressed by refining the certified robustness problem to be more aligned with practical adversarial settings.
The Asymmetric Certified Robustness Problem
Current certifiably robust classifiers produce certificates for inputs belonging to any class. For many real-world adversarial applications, this is unnecessarily broad. Consider the illustrative case of someone composing a phishing scam email while trying to avoid spam filters. This adversary will always attempt to fool the spam filter into thinking that their spam email is benign—never conversely. In other words, the attacker is solely attempting to induce false negatives from the classifier. Similar settings include malware detection, fake news flagging, social media bot detection, medical insurance claims filtering, financial fraud detection, phishing website detection, and many more.
Figure 2. Asymmetric robustness in email filtering. Practical adversarial settings often require certified robustness for only one class.
These applications all involve a binary classification setting with one sensitive class that an adversary is attempting to avoid (e.g., the “spam email” class). This motivates the problem of asymmetric certified robustness, which aims to provide certifiably robust predictions for inputs in the sensitive class while maintaining a high clean accuracy for all other inputs. We provide a more formal problem statement in the main text.
Feature-convex classifiers
We propose feature-convex neural networks to address the asymmetric robustness problem. This architecture composes a simple Lipschitz-continuous feature map ${\varphi: \mathbb{R}^d \to \mathbb{R}^q}$ with a learned Input-Convex Neural Network (ICNN) ${g: \mathbb{R}^q \to \mathbb{R}}$ (Figure 1). ICNNs enforce convexity from the input to the output logit by composing ReLU nonlinearities with nonnegative weight matrices. Since a binary ICNN decision region consists of a convex set and its complement, we add the precomposed feature map $\varphi$ to permit nonconvex decision regions.
Feature-convex classifiers enable the fast computation of sensitive-class certified radii for all $\ell_p$-norms. Using the fact that convex functions are globally underapproximated by any tangent plane, we can obtain a certified radius in the intermediate feature space. This radius is then propagated to the input space by Lipschitzness. The asymmetric setting here is critical, as this architecture only produces certificates for the positive-logit class $g(\varphi(x)) > 0$.
The resulting $\ell_p$-norm certified radius formula is particularly elegant:
\[r_p(x) = \frac{ \color{blue}{g(\varphi(x))} } { \mathrm{Lip}_p(\varphi) \color{red}{\| \nabla g(\varphi(x)) \| _{p,*}}}.\]The non-constant terms are easily interpretable: the radius scales proportionally to the classifier confidence and inversely to the classifier sensitivity. We evaluate these certificates across a range of datasets, achieving competitive $\ell_1$ certificates and comparable $\ell_2$ and $\ell_{\infty}$ certificates—despite other methods generally tailoring for a specific norm and requiring orders of magnitude more runtime.
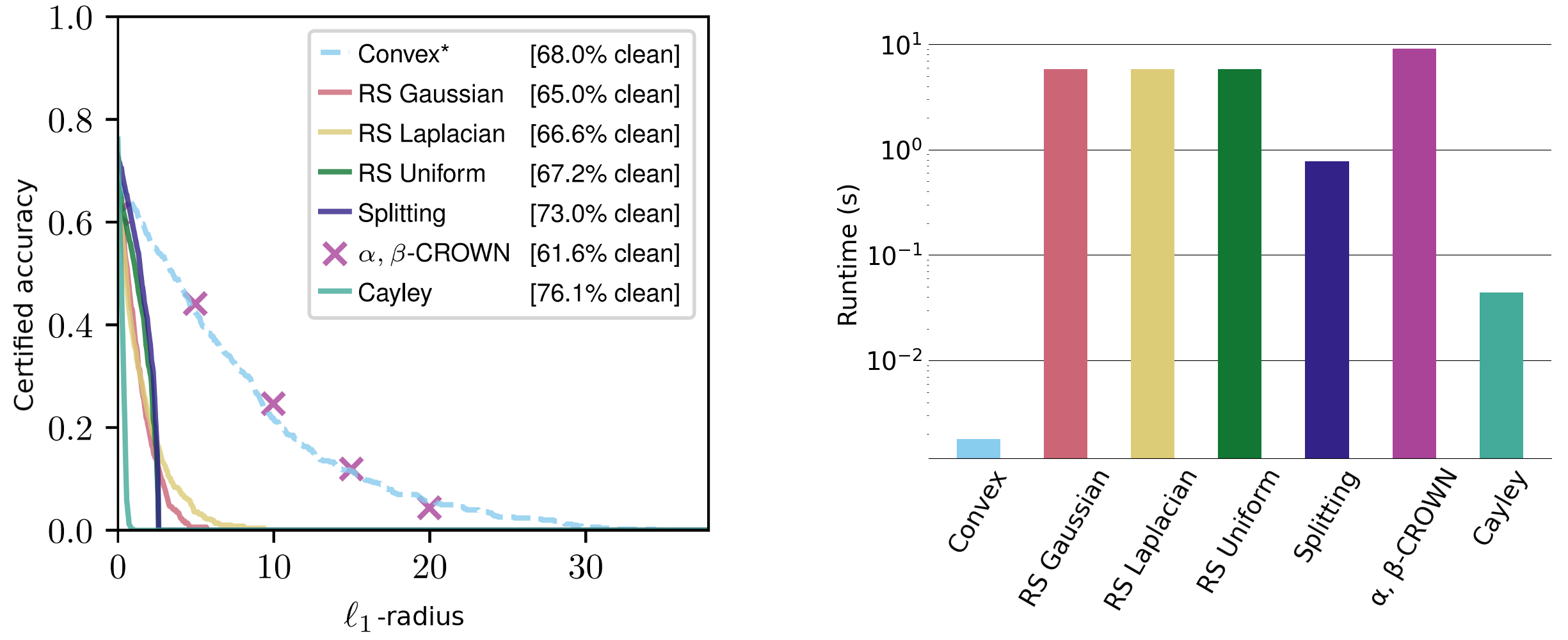
Figure 3. Sensitive class certified radii on the CIFAR-10 cats vs dogs dataset for the $\ell_1$-norm. Runtimes on the right are averaged over $\ell_1$, $\ell_2$, and $\ell_{\infty}$-radii (note the log scaling).
Our certificates hold for any $\ell_p$-norm and are closed form and deterministic, requiring just one forwards and backwards pass per input. These are computable on the order of milliseconds and scale well with network size. For comparison, current state-of-the-art methods such as randomized smoothing and interval bound propagation typically take several seconds to certify even small networks. Randomized smoothing methods are also inherently nondeterministic, with certificates that just hold with high probability.
Theoretical promise
While initial results are promising, our theoretical work suggests that there is significant untapped potential in ICNNs, even without a feature map. Despite binary ICNNs being restricted to learning convex decision regions, we prove that there exists an ICNN that achieves perfect training accuracy on the CIFAR-10 cats-vs-dogs dataset.
Fact. There exists an input-convex classifier which achieves perfect training accuracy for the CIFAR-10 cats-versus-dogs dataset.
However, our architecture achieves just $73.4\%$ training accuracy without a feature map. While training performance does not imply test set generalization, this result suggests that ICNNs are at least theoretically capable of attaining the modern machine learning paradigm of overfitting to the training dataset. We thus pose the following open problem for the field.
Open problem. Learn an input-convex classifier which achieves perfect training accuracy for the CIFAR-10 cats-versus-dogs dataset.
Conclusion
We hope that the asymmetric robustness framework will inspire novel architectures which are certifiable in this more focused setting. Our feature-convex classifier is one such architecture and provides fast, deterministic certified radii for any $\ell_p$-norm. We also pose the open problem of overfitting the CIFAR-10 cats vs dogs training dataset with an ICNN, which we show is theoretically possible.
This post is based on the following paper:
Asymmetric Certified Robustness via Feature-Convex Neural Networks
Samuel Pfrommer,
Brendon G. Anderson,
Julien Piet,
Somayeh Sojoudi,
37th Conference on Neural Information Processing Systems (NeurIPS 2023).
Further details are available on arXiv and GitHub. If our paper inspires your work, please consider citing it with:
@inproceedings{
pfrommer2023asymmetric,
title={Asymmetric Certified Robustness via Feature-Convex Neural Networks},
author={Samuel Pfrommer and Brendon G. Anderson and Julien Piet and Somayeh Sojoudi},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023}
}