Reinforcement learning provides a conceptual framework for autonomous agents to learn from experience, analogously to how one might train a pet with treats. But practical applications of reinforcement learning are often far from natural: instead of using RL to learn through trial and error by actually attempting the desired task, typical RL applications use a separate (usually simulated) training phase. For example, AlphaGo did not learn to play Go by competing against thousands of humans, but rather by playing against itself in simulation. While this kind of simulated training is appealing for games where the rules are perfectly known, applying this to real world domains such as robotics can require a range of complex approaches, such as the use of simulated data, or instrumenting real-world environments in various ways to make training feasible under laboratory conditions. Can we instead devise reinforcement learning systems for robots that allow them to learn directly “on-the-job”, while performing the task that they are required to do? In this blog post, we will discuss ReLMM, a system that we developed that learns to clean up a room directly with a real robot via continual learning.




We evaluate our method on different tasks that range in difficulty. The top-left task has uniform white blobs to pickup with no obstacles, while other rooms have objects of diverse shapes and colors, obstacles that increase navigation difficulty and obscure the objects and patterned rugs that make it difficult to see the objects against the ground.
To enable “on-the-job” training in the real world, the difficulty of collecting more experience is prohibitive. If we can make training in the real world easier, by making the data gathering process more autonomous without requiring human monitoring or intervention, we can further benefit from the simplicity of agents that learn from experience. In this work, we design an “on-the-job” mobile robot training system for cleaning by learning to grasp objects throughout different rooms.
Lesson 1: The Benefits of Modular Policies for Robots.
People are not born one day and performing job interviews the next. There are many levels of tasks people learn before they apply for a job as we start with the easier ones and build on them. In ReLMM, we make use of this concept by allowing robots to train common-reusable skills, such as grasping, by first encouraging the robot to prioritize training these skills before learning later skills, such as navigation. Learning in this fashion has two advantages for robotics. The first advantage is that when an agent focuses on learning a skill, it is more efficient at collecting data around the local state distribution for that skill.
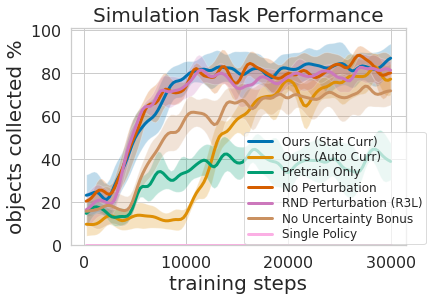
That is shown in the figure above, where we evaluated the amount of prioritized grasping experience needed to result in efficient mobile manipulation training. The second advantage to a multi-level learning approach is that we can inspect the models trained for different tasks and ask them questions, such as, “can you grasp anything right now” which is helpful for navigation training that we describe next.
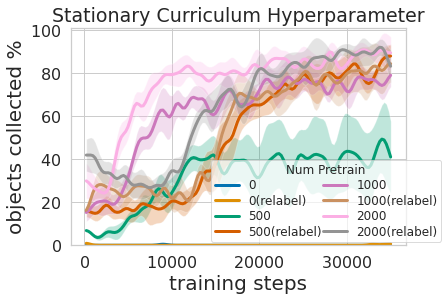
Training this multi-level policy was not only more efficient than learning both skills at the same time but it allowed for the grasping controller to inform the navigation policy. Having a model that estimates the uncertainty in its grasp success (Ours above) can be used to improve navigation exploration by skipping areas without graspable objects, in contrast to No Uncertainty Bonus which does not use this information. The model can also be used to relabel data during training so that in the unlucky case when the grasping model was unsuccessful trying to grasp an object within its reach, the grasping policy can still provide some signal by indicating that an object was there but the grasping policy has not yet learned how to grasp it. Moreover, learning modular models has engineering benefits. Modular training allows for reusing skills that are easier to learn and can enable building intelligent systems one piece at a time. This is beneficial for many reasons, including safety evaluation and understanding.
Lesson 2: Learning systems beat hand-coded systems, given time
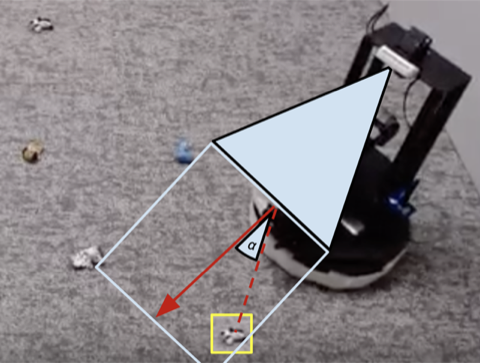
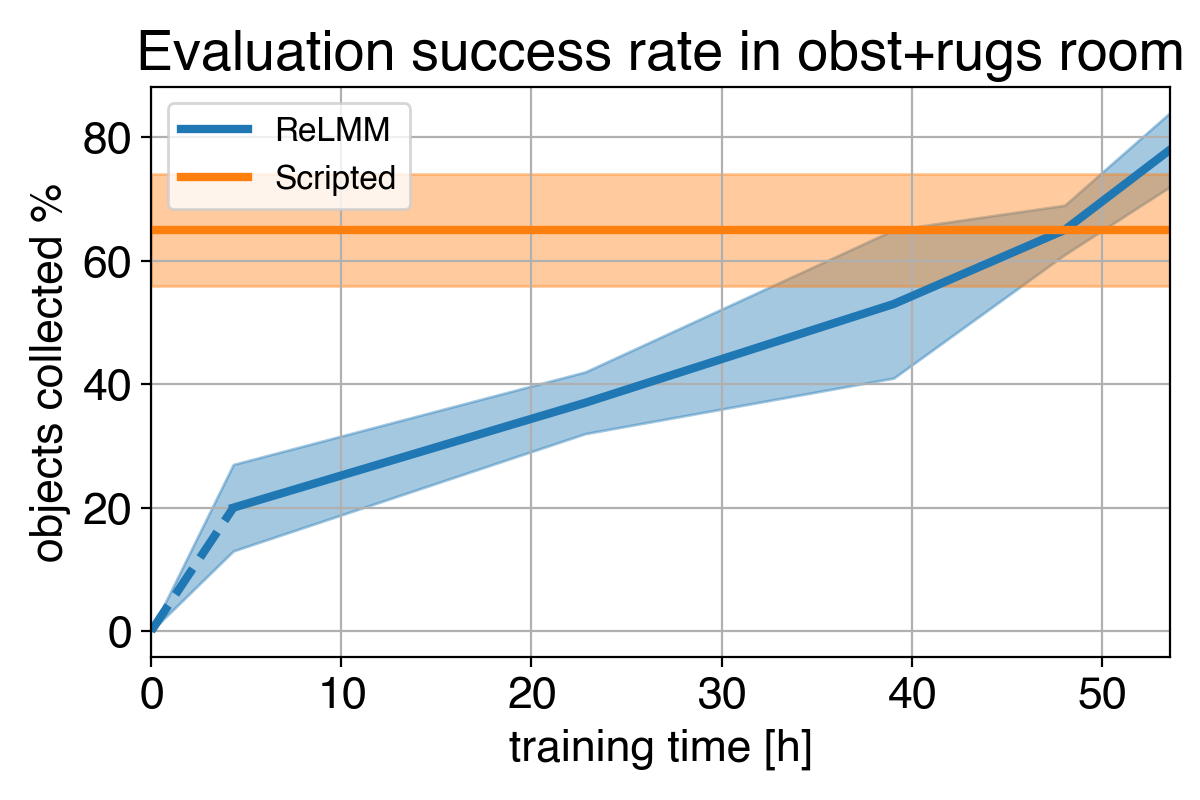
Many robotics tasks that we see today can be solved to varying levels of success using hand-engineered controllers. For our room cleaning task, we designed a hand-engineered controller that locates objects using image clustering and turns towards the nearest detected object at each step. This expertly designed controller performs very well on the visually salient balled socks and takes reasonable paths around the obstacles but it can not learn an optimal path to collect the objects quickly, and it struggles with visually diverse rooms. As shown in video 3 below, the scripted policy gets distracted by the white patterned carpet while trying to locate more white objects to grasp.
1)  2)
2) 
3)  4)
4) 
We show a comparison between (1) our policy at the beginning of training (2) our policy at the end of training (3) the scripted policy. In (4) we can see the robot's performance improve over time, and eventually exceed the scripted policy at quickly collecting the objects in the room.
Given we can use experts to code this hand-engineered controller, what is the purpose of learning? An important limitation of hand-engineered controllers is that they are tuned for a particular task, for example, grasping white objects. When diverse objects are introduced, which differ in color and shape, the original tuning may no longer be optimal. Rather than requiring further hand-engineering, our learning-based method is able to adapt itself to various tasks by collecting its own experience.
However, the most important lesson is that even if the hand-engineered controller is capable, the learning agent eventually surpasses it given enough time. This learning process is itself autonomous and takes place while the robot is performing its job, making it comparatively inexpensive. This shows the capability of learning agents, which can also be thought of as working out a general way to perform an “expert manual tuning” process for any kind of task. Learning systems have the ability to create the entire control algorithm for the robot, and are not limited to tuning a few parameters in a script. The key step in this work allows these real-world learning systems to autonomously collect the data needed to enable the success of learning methods.
This post is based on the paper “Fully Autonomous Real-World Reinforcement Learning with Applications to Mobile Manipulation”, presented at CoRL 2021. You can find more details in our paper, on our website and the on the video. We provide code to reproduce our experiments. We thank Sergey Levine for his valuable feedback on this blog post.