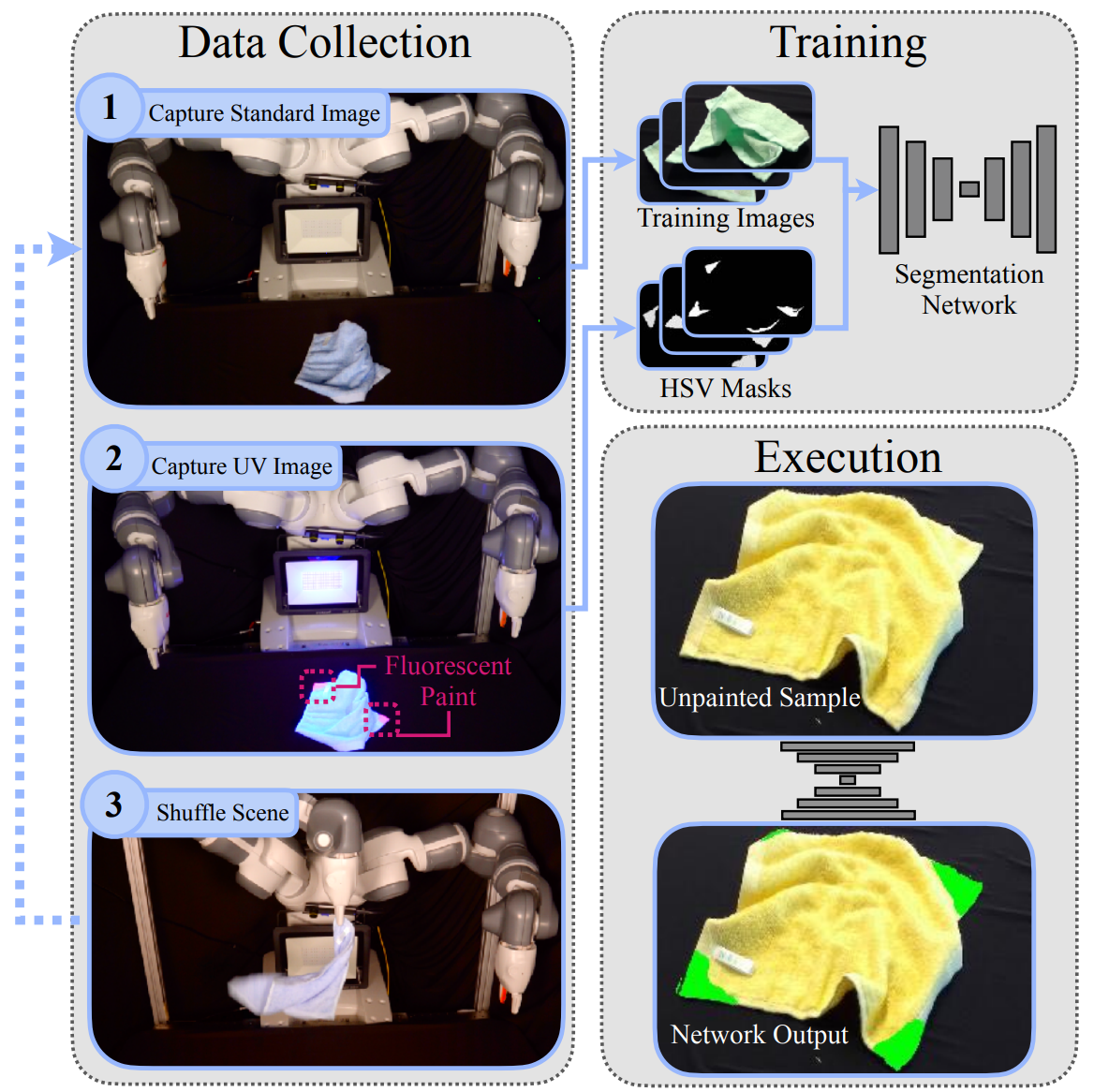
Large-scale semantic image annotation is a significant challenge for learning-based perception systems in robotics. Supervised learning requires labeled data, and a common approach is for humans to hand-label images with segmentation masks, keypoints, and class labels. However this is time-consuming, error-prone, and expensive, especially when dense or 3-D annotations are required. An alternative approach is to use simulated data, where data annotation can be densely and procedurally generated at scale at relatively low cost. However, simulation data can visually or physically differ from real data. In this blog post, we present Labels from UltraViolet (LUV), a novel framework that enables rapid, labeled data collection in real manipulation environments without human labeling.
LUV uses an array of ultraviolet lights placed around a manipulation workspace that can be switched automatically. We mark objects or keypoints in the scene with transparent, ultraviolet fluorescent paints that are nearly invisible in visible light but highly visible under ultraviolet radiation. For each physical configuration, LUV takes two images: one with standard lighting and one with the ultraviolet lights turned on. LUV provides precise labels for the standard image by performing color segmentation on the paired ultraviolet image. LUV trains a network on the resulting dataset to make predictions on subsequent scenes under standard lighting.
UV-Fluorescent Paint and Lighting
LUV relies on paint that is nearly transparent under visible light, but fluoresces under ultraviolet radiation. We leverage this property by painting relevant objects and keypoints. For example, in a cable segmentation perception task, we paint the entire cable with UV-fluorescent paint. In a towel corner detection task, we paint the corners of each towel with UV-fluorescent paint.

We observe that different types of paints have better transparency properties on different materials. Further discussion on different types of paints and their interaction with different material types can be found at https://sites.google.com/berkeley.edu/luv.

Mask Generation
To generate masks, the UV lights are turned on, and if available the ambient white lights turned off. The camera exposure for each sample is found by manually sweeping exposures and selecting the exposure yielding clearest label colors. For scenes with both dark and light painted materials, multiple exposures can be captured and post-processed with HDR to retrieve well exposed labels for all colors. We perform HSV color filtering on the UV images to extract the training labels.
Benefits of UV Labels
Here, we discuss the benefits of the training labels generated by LUV.
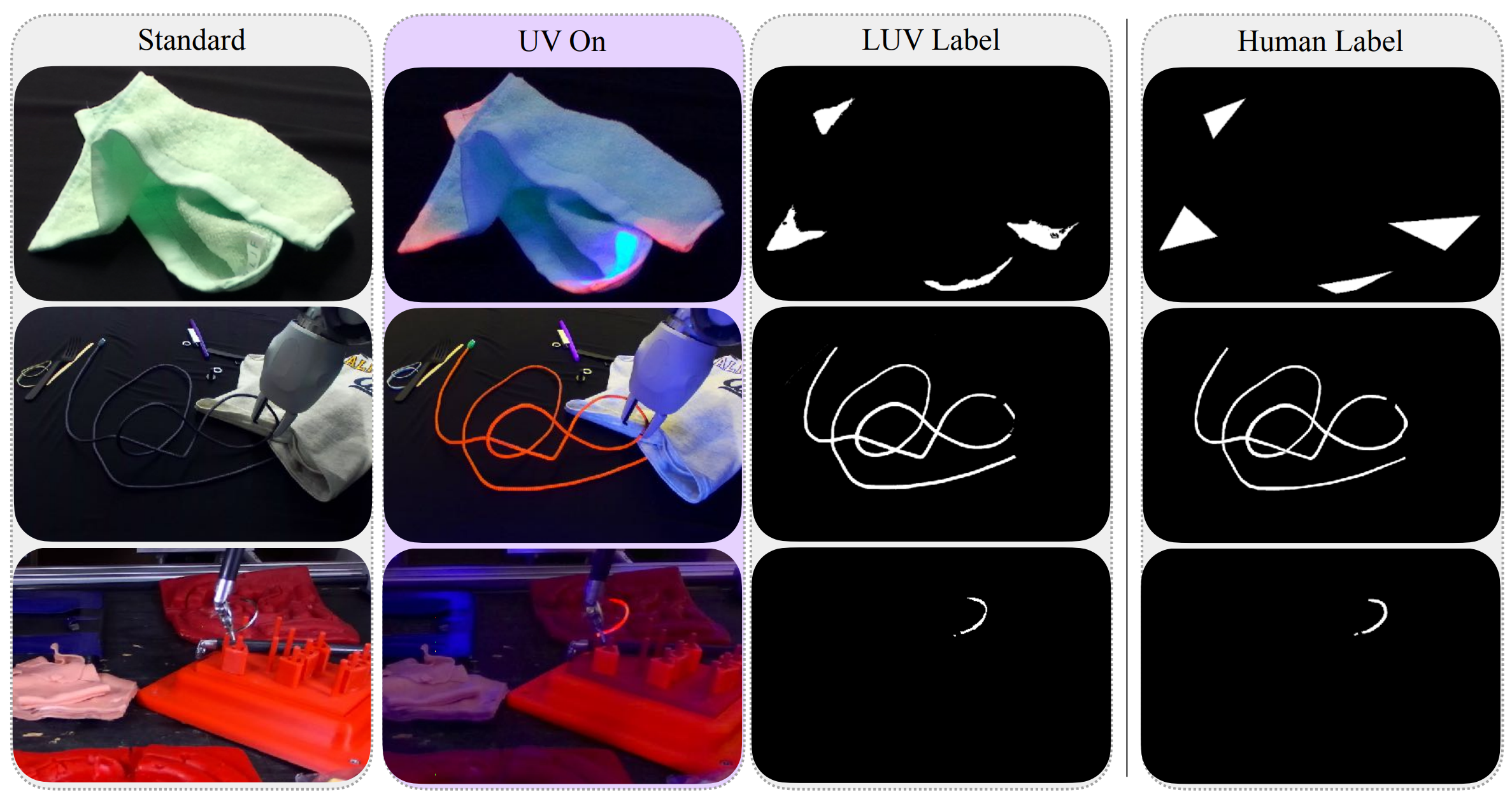
Accurate Labels
A key benefit of LUV is that the ultraviolet fluorescence can improve the quality of labels, especially in visually challenging scenes. For example, labeling the below images manually with towel corners is challenging for human labelers.

However, UV fluorescence can accurately identify all of the corners in the image (below).

Faster Labels
LUV generates each UV label in less than 200ms on commodity desktop hardware, even when the labels are complex. The cable segmentation task is particularly challenging for human labelers, because the ground-truth cable masks are very complex. We find that the cable images in our cable segmentation dataset take an average of 446 seconds for humans to label, over 2500 times longer. Labeling our entire dataset of 486 training images takes less than two minutes in a single-threaded program, but would take over 60 hours for a human.
Lower Cost Labels
Data annotation services are a popular solution for labeling images. The total one-time cost of our setup is 282 dollars. Based on Amazon’s recommended price of 0.82 dollars per semantic segmentation label on Amazon Mechanical Turk, and using 2 labels per image based on their recommendation for quality, this breaks even with Turk at 167 labeled images.
Network Training Results
We train a fully-convolutional neural network that predicts the training labels from only the standard images. We present results from three tasks commonly considered in robot learning literature: towel corner detection, cable segmentation, and needle segmentation. We observe that the networks are able to accurately predict these segmentation masks and keypoints on test images.

Links
Paper: All You Need is LUV: Unsupervised Collection of Labeled Images Using UV-Fluorescent Markings Brijen Thananjeyan*, Justin Kerr*, Huang Huang, Kishore Srinivas, Joseph E. Gonzalez, Ken Goldberg.
*these authors contributed equally
Supplementary Material: https://sites.google.com/berkeley.edu/luv