
Robots have been useful in environments that can be carefully controlled, such as those commonly found in industrial settings (e.g. assembly lines). However, in unstructured settings like the home, we need robotic systems that are adaptive to the diversity of the real world.
Why reinforcement learning for robotics?
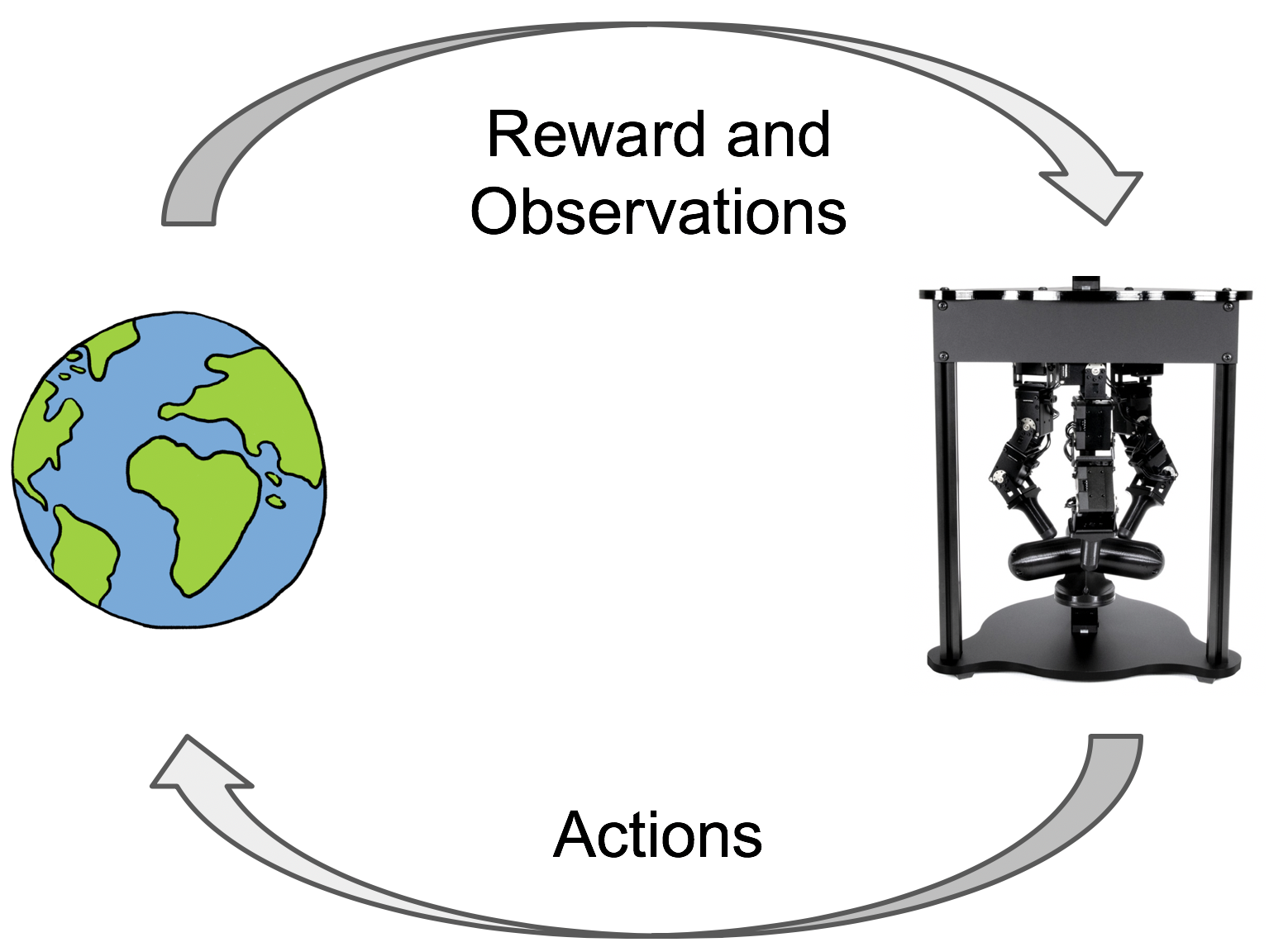
Learning-based algorithms have the potential to enable robots to acquire complex behaviors adaptively in unstructured environments, by leveraging data collected from the environment. In particular, with reinforcement learning, robots learn novel behaviors through trial and error interactions. This unburdens the human operator from having to pre-program accurate behaviors. This is particularly important as we deploy robots in scenarios where the environment may not be known.
Why perform reinforcement learning in the real world?
A robot which learns directly in the real world can continuously get better at its task as it collects more and more data from the real world, without substantial human intervention or engineering.
An alternative paradigm for robotic learning is simulation to real-world transfer where first, a simulation of the robot and its environment is constructed, then the robot learns the desired behaviors in simulation, and finally the learned behaviors are transferred to the real world (Sadeghi et al., 2016, Tobin et al., 2017).
However, this approach has some fundamental drawbacks. The simulation will never exactly match the real world, which means that improvements in simulation performance may not translate to improvements in the real world. Additionally, if a new simulation needs to be created for every new task and environment, content creation can become prohibitively expensive.
Training robots with reinforcement learning directly in the real world eliminates these problems. However, training robots in the real world with reinforcement learning has proven challenging, due to certain constraints.
What makes real world robotic reinforcement learning so challenging?

Prior works which utilized RL in the real world instrumented the environment to
do resets and get state + reward information. Real world environments typically
look more like the setup on the right, where the environment can not reset
itself and the robot can only count on its own sensor information.
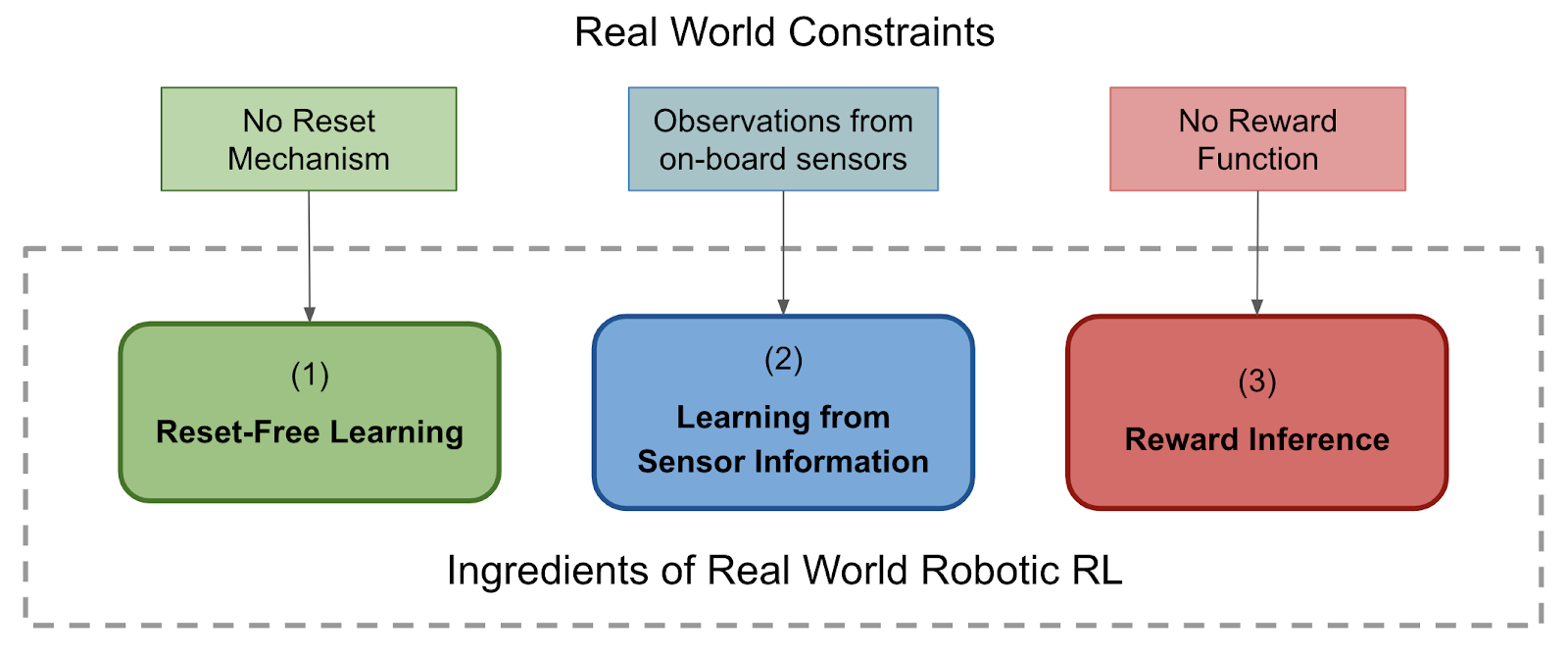
The reinforcement learning problem is classically defined in the framework of a Markov decision processes (MDPs). However, core pieces of information that are taken for granted in a simulator or idealized MDP are not easily available to the learning algorithm in a real world environment:
No Reset Mechanism: In the MDP framework, RL algorithms almost always assume access to an episodic reset mechanism, which resets the state of the world to a static distribution over initial states. This allows the agent to attempt the same task many times starting from the same place. However, in natural real world environments this reset mechanism does not usually exist.
Observations from On-Board Sensors: Since most environments aren’t equipped with instruments such as motion capture or vision-based tracking systems, the low-dimensional Markovian state of the world is not available, and we only have access to potentially high-dimensional on-board sensors, such as RGB cameras.
No Reward Function: It is usually assumed that the reward is either provided by some external mechanism (e.g. a human supervisor) or can be predefined as a function of state (e.g. distance to the goal state). However, this can be impractical and an effective, scalable real world RL system must be able to infer rewards from its own sensory input.
A robotic system that can learn in natural environments needs to effectively deal with all three of these problems – the absence of reset mechanisms, state estimation, and reward specification – in order to be practical in and scalable to natural environments.
How can we build systems for real world robotic RL?
To deal with the constraints of real world environments, a real world robotic RL system should have three “ingredients”: (1) learn in the absence of resets, (2) learn directly from the robot’s own sensor information, and (3) learn from rewards inferred by the robot itself.
 In the following sections, we describe our instantiation of a real world RL
system which contains all of the mentioned ingredients, and demonstrate that it
can successfully learn a task without instrumentation in the real world. For
the sake of explanation we consider an bead manipulation task (shown on the
right), where the task is to split the four beads to either side.
In the following sections, we describe our instantiation of a real world RL
system which contains all of the mentioned ingredients, and demonstrate that it
can successfully learn a task without instrumentation in the real world. For
the sake of explanation we consider an bead manipulation task (shown on the
right), where the task is to split the four beads to either side.
(1) Reset Free Learning: Learned Perturbation Controller
We observed that the problem of reset free learning is challenging for two major reasons:
-
While learning, the agent can spend long amounts of time in certain states, effectively getting stuck. The typical episodic reset frees the agent from these states, but robots don’t have this luxury in the real world.
-
Once the task is completed once, the optimal behavior is to stay at the goal. However, if the agent learns to stay still, the agent won’t visit a variety of states and the learned policy is not very successful.
We can address these challenges by noting that the agent can get “stuck” in certain states, including the goal, in the reset-free regime. Thus we could try to perturb the state by ensuring that the agent is never able to stay in the same state for too long. To perturb the state as described, we propose learning a perturbation controller, which is trained with the goal of taking the agent to less explored states of the world. During training of the actual policy to perform the task, we alternate between running episodes of the perturbation controller and the policy, and train both the policy and the perturbation controller simultaneously.
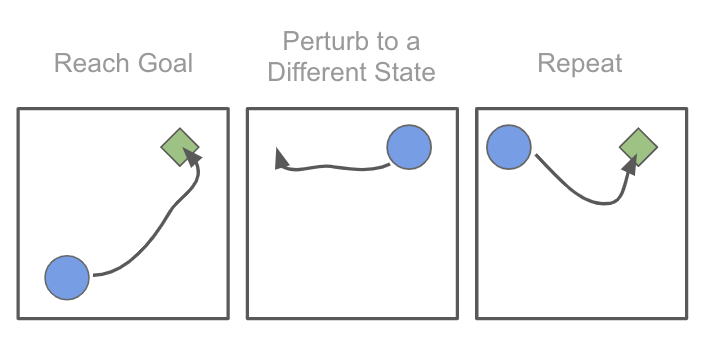
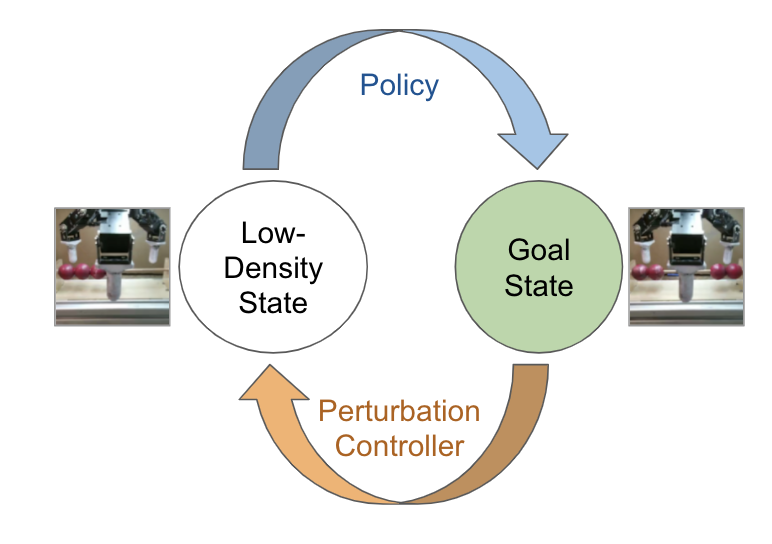
We can think of the perturbation controller as a simpler learned substitute for a reset mechanism: it pushes the robot to a variety of rarely visited states, allowing the robot to practice performing the task from a variety of configurations.
(2) State Estimation: Unsupervised Representation Learning
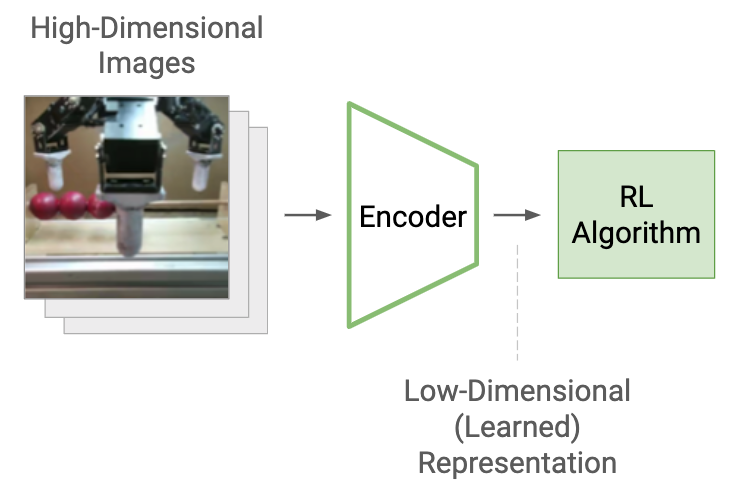
Observations of the environment taken from on-board sensors, for example an RGB camera, are often high-dimensional, which can make reinforcement learning difficult and slow. To address this, we utilize unsupervised representation learning techniques to condense images into latent features. Ideally, the latent features contain key information, while making the learning problem much easier. While many representation learning methods could be used, we explored the use of a variational encoder (Kingma et al., 2013) for feature learning.
(3) Reward Inference: Classifier Based Rewards
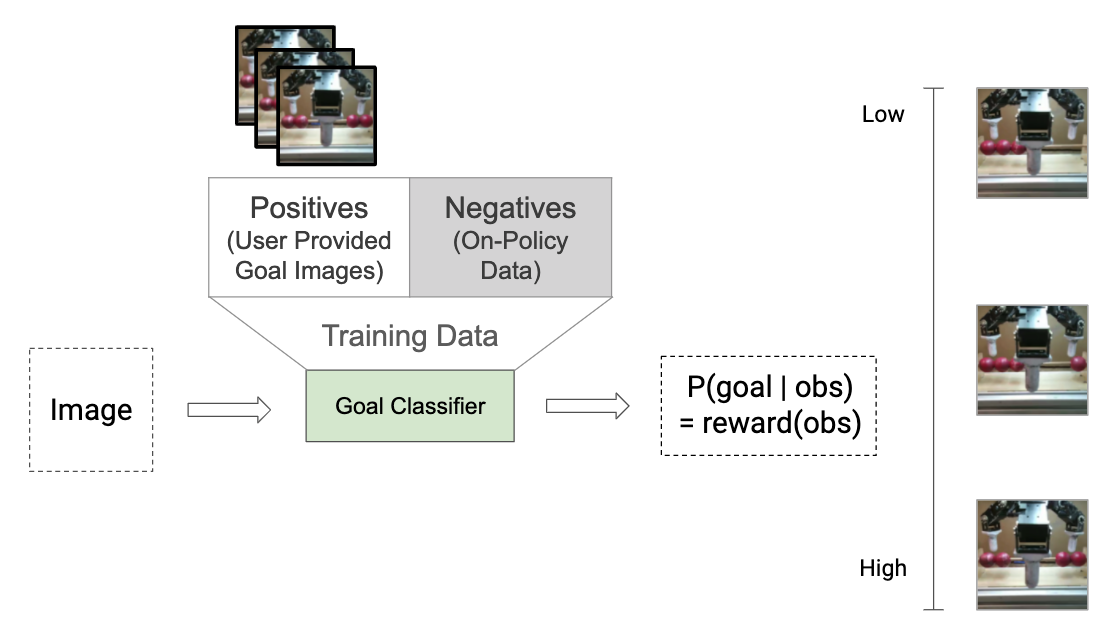
To learn tasks with minimal human instrumentation in the learning process, we allow our learning system to assign itself reward based on a simple pre-provided specification of the desired task by a human operator. We allow the human operator to provide images that depict successful outcomes, as a means to specify the desired task. Given these images, we learn a success classifier and use the likelihood of this classifier to self-assign reward through the learning process. To train the classifier, the human provided examples of success are treated as positive examples and the policy data is treated as negative examples.
With the ingredients described above put together, we have a real world robotic RL (R3L) system which can learn tasks in environments without instrumentation or intervention. To train this system, the user just has to (1) provide success images of the task to be completed (2) leave the system to train unattended. Finally, (3), the learned policy is able to successfully perform the task from any start state.

How well does this work?
The system instantiated as described above is able to learn a number of tasks in the real world, without the need for any instrumentation. In fact, we run our experiments overnight with no human involvement during the learning process! We show effective uninstrumented real world learning on two dexterous manipulation tasks with a 3 fingered robotic hand. As opposed to prior work on dexterous manipulation, we note that we did not need any special mechanisms for resetting the environment or providing reward and state estimates to the agent.
The time-lapses for the bead manipulation and valve rotation tasks show the three steps of (1) goal image collection, (2) unattended training for several hours, and (3) evaluation from a variety of initial states. We see that the robot is able to complete the task in all or most initial positions by the end of training.
What does this mean for reinforcement learning research in robotics?
While our proposed system is able to learn several real world tasks without instrumentation, it is far from a perfect solution. It is still largely limited to a small workspace and somewhat simplistic tasks. However, we believe that the ingredients of real world RL that we have proposed should endure as principles of design for real world RL systems.
While we have outlined some ingredients here, several others are crucial to address. Here are a few that we think are important:
-
Safe uninterrupted operation: As robots have to deal with more real world human environments, the safety - of the robot, human collaborators, and environment - are going to become increasingly important. Developing methods for safe long-term operation and exploration will become crucial.
-
Sample efficient off-policy learning: As we solve more and more tasks in the real world, it will become important to amortize the cost of learning and be able to effectively share knowledge across a variety of tasks and robots. A shift to more data-driven reinforcement learning methods would make RL more economically practical.
This blog post is based on our paper:
- The Ingredients of Real World Robotic Reinforcement Learning
Henry Zhu*, Justin Yu*, Abhishek Gupta*, Dhruv Shah, Kristian Hartikainen, Avi Singh, Vikash Kumar, Sergey Levine
ICLR 2020 https://openreview.net/forum?id=rJe2syrtvS¬eId=rJe2syrtvS