When learning to follow natural language instructions, neural networks tend to be very data hungry – they require a huge number of examples pairing language with actions in order to learn effectively. This post is about reducing those heavy data requirements by first watching actions in the environment before moving on to learning from language data. Inspired by the idea that it is easier to map language to meanings that have already been formed, we introduce a semi-supervised approach that aims to separate the formation of abstractions from the learning of language. Empirically, we find that pre-learning of patterns in the environment can help us learn grounded language with much less data.
Before we dive into the details, let’s look at an example to see why neural networks struggle to learn from smaller amounts of data. For now, we’ll use examples from the SHRDLURN block stacking task, but later we’ll look at results on another environment.
Let’s put ourselves in the shoes of a model that is learning to follow instructions. Suppose we are given the single training example below, which pairs a language command with an action in the environment:

This example tells us that if we are in state (a) and are trying to follow the instruction (b), the correct output for our model is the state (c). Before learning, the model doesn’t know anything about language, so we must rely on examples like the one shown to figure out the meaning of the words. After learning, we will be given new environment states and new instructions, and the model’s job is to choose the correct output states from executing the instructions. First let’s consider a simple case where we get the exact same language, but the environment state is different, like the one shown here:

On this new state, the model has many different possible outputs that it could consider. Here are just a few:

Some of these outputs seem reasonable to a human, like stacking red blocks on orange blocks or stacking red blocks on the left, but others are kind of strange, like generating a completely unrelated configuration of blocks. To a neural network with no prior knowledge, however, all of these options look plausible.
A human learning a new language might approach this task by reasoning about possible meanings of the language that are consistent with the given example and choosing states that correspond to those meanings. The set of possible meanings to consider comes from prior knowledge about what types of things might happen in an environment and how we can talk about them. In this context, a meaning is an abstract transformation that we can apply to states to get new states. For example, if someone saw the training instance above paired with language they didn’t understand, they might focus on two possible meanings for the instruction: it could be telling us to stack red blocks on orange blocks, or it could be telling us to stack a red block on the leftmost position.

Although we don’t know which of these two options is correct – both are plausible given the evidence – we now have many fewer options and might easily distinguish between them with just one or two more related examples. Having a set of pre-formed meanings makes learning easier because the meanings constrain the space of possible outputs that must be considered.
In fact, pre-formed meanings do even more than just restricting the number of choices, because once we have chosen a meaning to pair with the language, it specifies the correct way to generalize across a wide variety of different initial environment states. For example, consider the following transitions:

If we know in advance that all of these transitions belong together in a single semantic group (adding a red block on the left), learning language becomes easier because we can map to the group instead of the individual transitions. An end-to-end network that doesn’t start with any grouping of transitions has a much harder time because it has to learn the correct way to generalize across initial states. One approach used by a long line of past work has been to provide the learner with a manually defined set of abstractions called logical forms. In contrast, we take a more data-driven approach where we learn abstractions from unsupervised (language-free) data instead.
In this work, we help a neural network learn language with fewer examples by first learning abstractions from language-free observations of actions in an environment. The idea here is that if the model sees lots of actions happening in an environment, perhaps it can pick up on patterns in what tends to be done, and these patterns might give hints at what abstractions are useful. Our pre-learned abstractions can make language learning easier by constraining the space of outputs we need to consider and guiding generalization across different environment states.
We break up learning into two phases: an environment learning phase where our agent builds abstractions from language-free observation of the environment, and a language learning phase where natural language instructions are mapped to the pre-learned abstractions. The motivation for this setup is that language-free observations of the environment are often easier to get than interactions paired with language, so we should use the cheaper unlabeled data to help us learn with less language data. For example, a virtual assistant could learn with data from regular smartphone use, or in the longer term robots might be able to learn by watching humans naturally interact with the world. In the environments we are using in this post, we don’t have a natural source of unlabeled observations, so we generate the environment data synthetically.
Method
Now we’re ready to dive into our method. We’ll start with the environment learning phase, where we will learn abstractions by observing an agent, such as a human, acting in the environment. Our approach during this phase will be to create a type of autoencoder of the state transitions (actions) that we see, shown below:
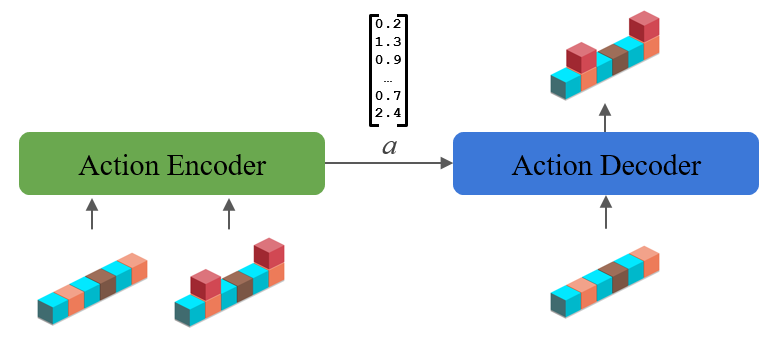
The encoder takes in the states before and after the transition and computes a representation of the transition itself. The decoder takes that transition representation from the encoder and must use it to recreate the final state from the initial one. The encoder and decoder architectures will be task specific, but use generic components such as convolutions or LSTMs. For example, in the block stacking task states are represented as a grid and we use a convolutional architecture. We train using a standard cross-entropy loss on the decoder’s output state, and after training we will use the representation passed between the encoder and decoder as our learned abstraction.
One thing that this autoencoder will learn is which type of transitions tend to happen, because the model will learn to only output transitions like the ones it sees during training. In addition, this model will learn to group different transitions. This grouping happens because the representation between the encoder and decoder acts as an information bottleneck, and its limited capacity forces the model to reuse the same representation vector for multiple different transitions. We find that often the groupings it chooses tend to be semantically meaningful because representations that align with the semantics of the environment tend to be the most compact.
After environment learning pre-training, we are ready to move on to learning language. For the language learning phase, we will start with the decoder that we pre-trained during environment learning (“action decoder” in the figures above and below). The decoder maps from our learned representation space to particular state outputs. To learn language, we now just need to introduce a language encoder module that maps from language into the representation space and train it by backpropagating through the decoder. The model structure is shown in the figure below.
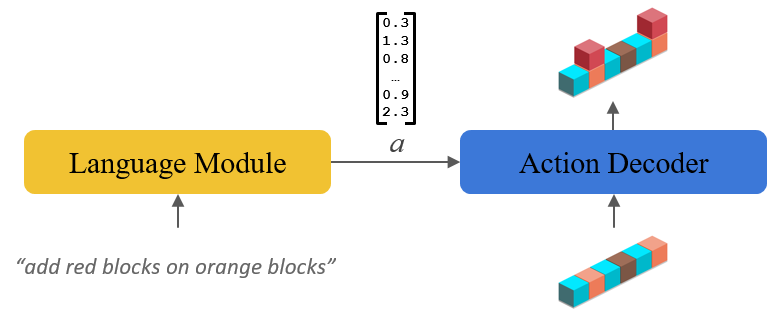
The model in this phase looks a lot like other encoder-decoder models used previously for instruction following tasks, but now the pre-trained decoder can constrain the output and help control generalization.
Results
Now let’s look at some results. We’ll compare our method to an end-to-end neural model, which has an identical neural architecture to our ultimate language learning model but without any environment learning pre-training of the decoder. First we test on the SHURDLURN block stacking task, a task that is especially challenging for neural models because it requires learning with just tens of examples. A baseline neural model gets an accuracy of 18% on the task, but with our environment learning pre-training, the model reaches 28%, an improvement of ten absolute percentage points.
We also tested our method on a string manipulation task where we learn to execute instructions like “insert the letters vw after every vowel” on a string of characters. The chart below shows accuracy as we vary the amount of data for both the baseline end-to-end model and the model with our pre-training procedure.
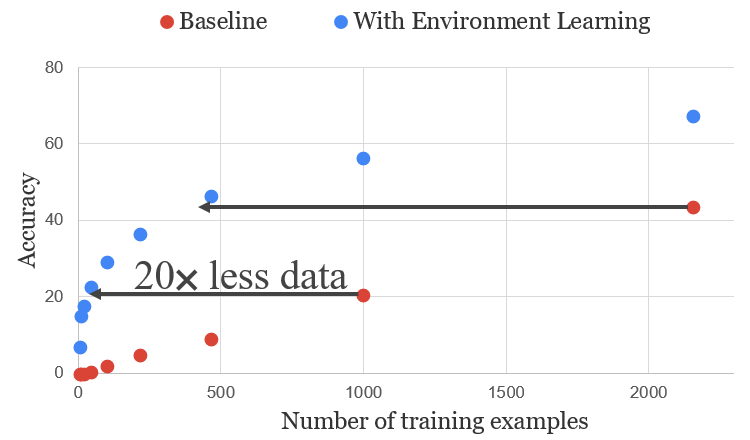
As shown above, using our pre-training method leads to much more data-efficient language learning compared to learning from scratch. By pre-learning abstractions from the environment, our method increases data efficiency by more than an order of magnitude. To learn more about our method, including some additional performance-improving tricks and an analysis of what pre-training learns, check out our paper from ACL 2019: https://arxiv.org/abs/1907.09671.