In many tasks in machine learning, it is common to want to answer questions given fixed, pre-collected datasets. In some applications, however, we are not given data a priori; instead, we must collect the data we require to answer the questions of interest. This situation arises, for example, in environmental contaminant monitoring and census-style surveys. Collecting the data ourselves allows us to focus our attention on just the most relevant sources of information. However, determining which of these sources of information will yield useful measurements can be difficult. Furthermore, when data is collected by a physical agent (e.g. robot, satellite, human, etc.) we must plan our measurements so as to reduce costs associated with the motion of the agent over time. We call this abstract problem embodied adaptive sensing.
We introduce a new approach to the embodied adaptive sensing problem, in which a robot must traverse its environment to identify locations or items of interest. Adaptive sensing encompasses many well-studied problems in robotics, including the rapid identification of accidental contamination leaks and radioactive sources, and finding individuals in search and rescue missions. In such settings, it is often critical to devise a sensing trajectory that returns a correct solution as quickly as possible.
We focus on the problem of radioactive source-seeking (RSS), in which a UAV must identify the $k$-largest radioactive emitters in its environment, where $k$ is a user-defined parameter. RSS is a particularly interesting instance of the adaptive sensing problem, due both to the challenges posed by the highly heterogeneous background noise, as well as to the existence of a well-characterized sensor model amenable to the construction of statistical confidence intervals.

We introduce AdaSearch, a successive-elimination framework for general adaptive sensing problems, and demonstrate it within the context of radioactive source seeking. AdaSearch explicitly maintains confidence intervals over the emissions rate at each point in the environment. Using these confidence intervals, the algorithm iteratively identifies a set of candidate points likely to be among the top emitters, and eliminates other points.
Embodied Search as a Multiple Hypothesis Testing Scenario
Traditionally, the robotics community has conceived of embodied search as a continuous motion planning problem, where the robot must balance exploring its environment with selecting efficient trajectories. This has motivated approaches where both trajectory optimization and exploration are combined into a single objective, which can be optimized using receding horizon control (Hoffman and Tomlin, Bai et al., Marchant and Ramos). Instead, we consider an alternate approach in which we formulate the problem as one of sequential best-action identification via hypothesis testing.
In sequential hypothesis testing, the goal is to reach conclusions on many separate questions, by iteratively collecting data. An agent is given a set of $N$ measurement actions, each of which yields observations according to a distinct, fixed distribution.
The agent’s goal is to learn some prespecified property of these $N$ observation distributions. For example, in a statistical “A/B test,” a measurement action corresponds to showing a new customer either product A or product B, and recording their assessment of that product. Here, $N=2$ because there are just two actions, showing product A and showing product B. The property of interest is which product is preferred on average (B in the illustration below). As we collect measurements on preferences, we keep track of sample averages, as well as confidence intervals around them, described by a lower confidence bound (LCB) and an upper confidence bound (UCB) for each product. As we collect more measurements, we become more confident in our estimate of preference for each individual product, and therefore our ranking between products. This suggests a condition for concluding that product B is preferred to product A: If the LCB for product B is greater than the UCB for product A, then we can conclude that with high probability, B is prefered to A, on average.
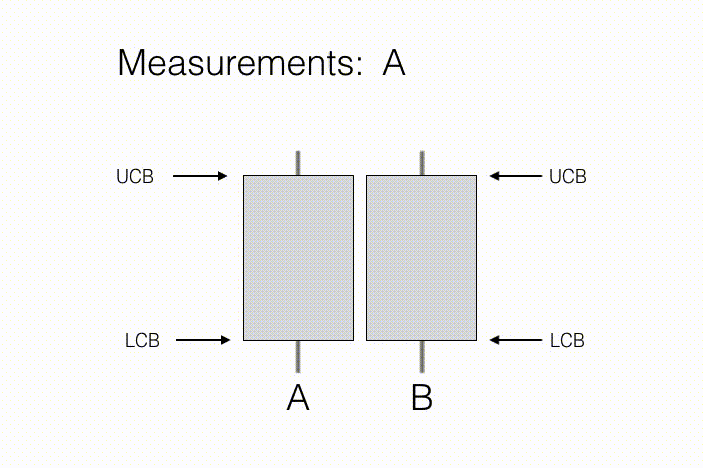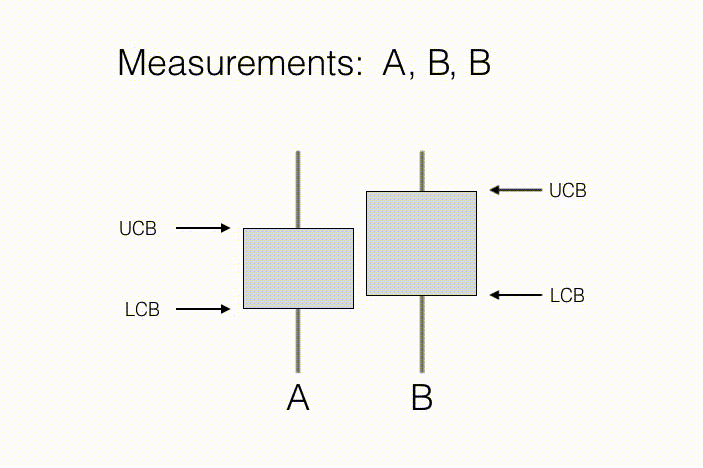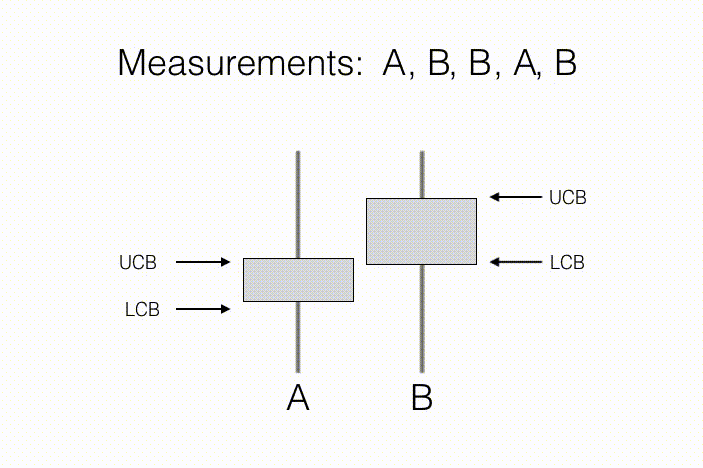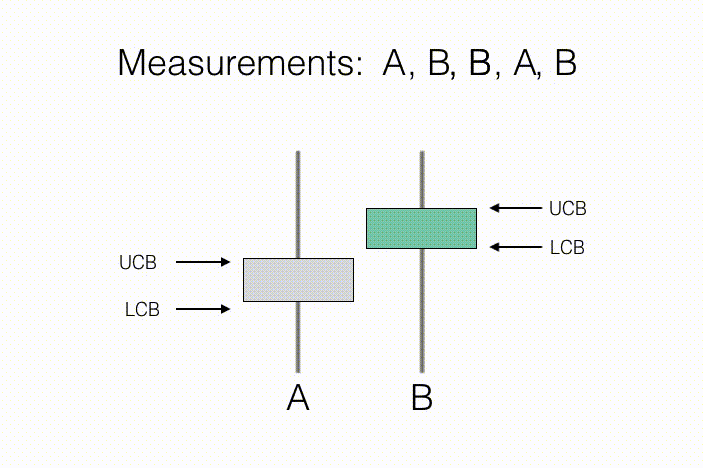
In the context of environmental sensing, each action may correspond to taking a sensor reading from a given position and orientation. Typically, the agent wishes to know which single measurement action yields observations with the greatest mean observed signal, or which set of $k$ actions together have the greatest mean observations. To do so, the agent may choose actions sequentially, using previously measured observations to favor future actions which are most informative for discerning the actions with largest mean observations.
At first glance, sequential best-action identification may seem like too abstract a framework to be useful in mobile, embodied sensing agents. Indeed, the agent can choose any arbitrary sequence of measurement actions, without considering the potential costs—such as movement time—associated with changing actions. However, the abstract nature of sequential best-action identification is also its most formidable strength. By formulating the embodied search problem in precise statistical language, we develop actionable confidence intervals about the observation means associated with each sensing action, and determine the set of all actions which still need to be taken before the points of interest can confidently determined.
Our proposed approach to embodied search, AdaSearch, uses confidence intervals from sequential best-action identification and a global trajectory planning heuristic to both achieve asymptotically optimal measurement complexity, and effectively amortize movement costs.
Radioactive Source Seeking
For concreteness, we will present AdaSearch in the context of the radioactive source seeking problem with a single source. We model the environment as a planar grid, as in the depiction below. There is exactly one high-intensity radioactive point source (red dot). However, locating this source is difficult because sensor measurements are corrupted by the background radiation (pink dots). Sensor measurements are obtained by flying a quadrotor equipped with a radiation sensor above the grid. The goal is to devise a sequence of trajectories so that the measurements obtained from the onboard sensor allow us to disambiguate the radioactive point source from the background radiation sources, as quickly as possible.

AdaSearch
Our algorithm, AdaSearch, combines a global-coverage planning approach with an adaptive sensing rule based on hypothesis testing to define these trajectories. In the first pass through the grid, we sample uniformly over the environment.
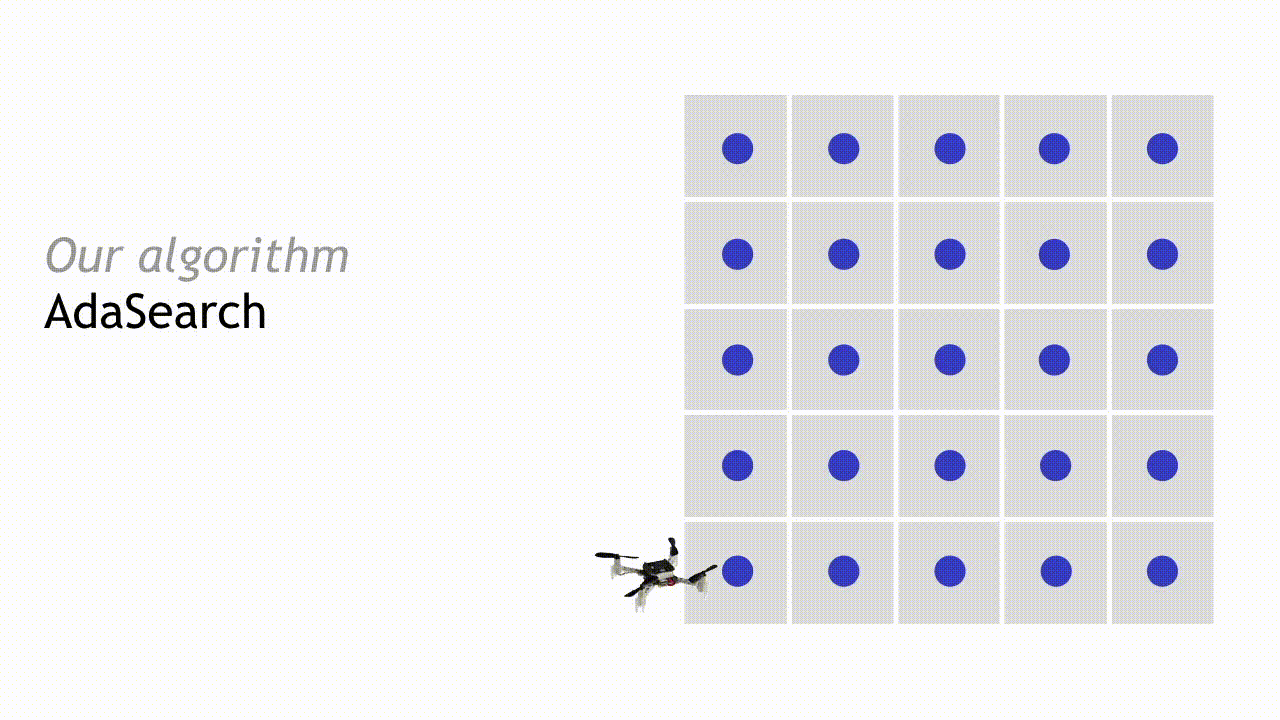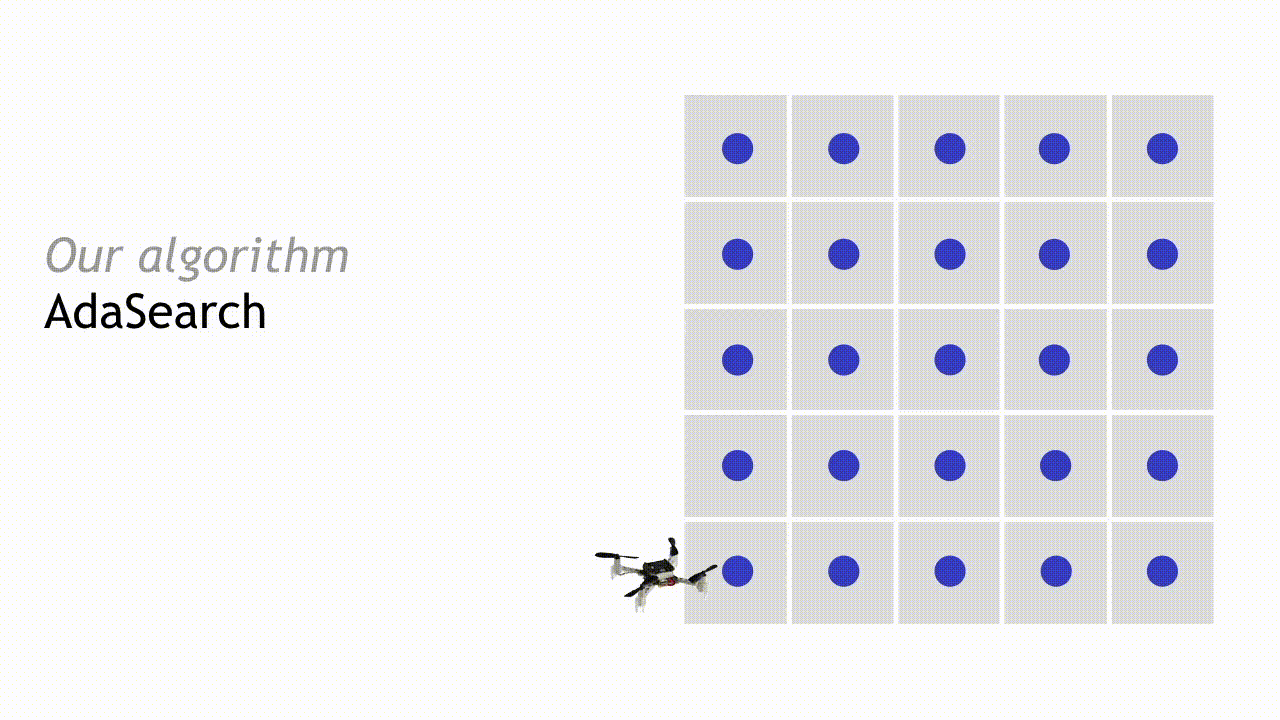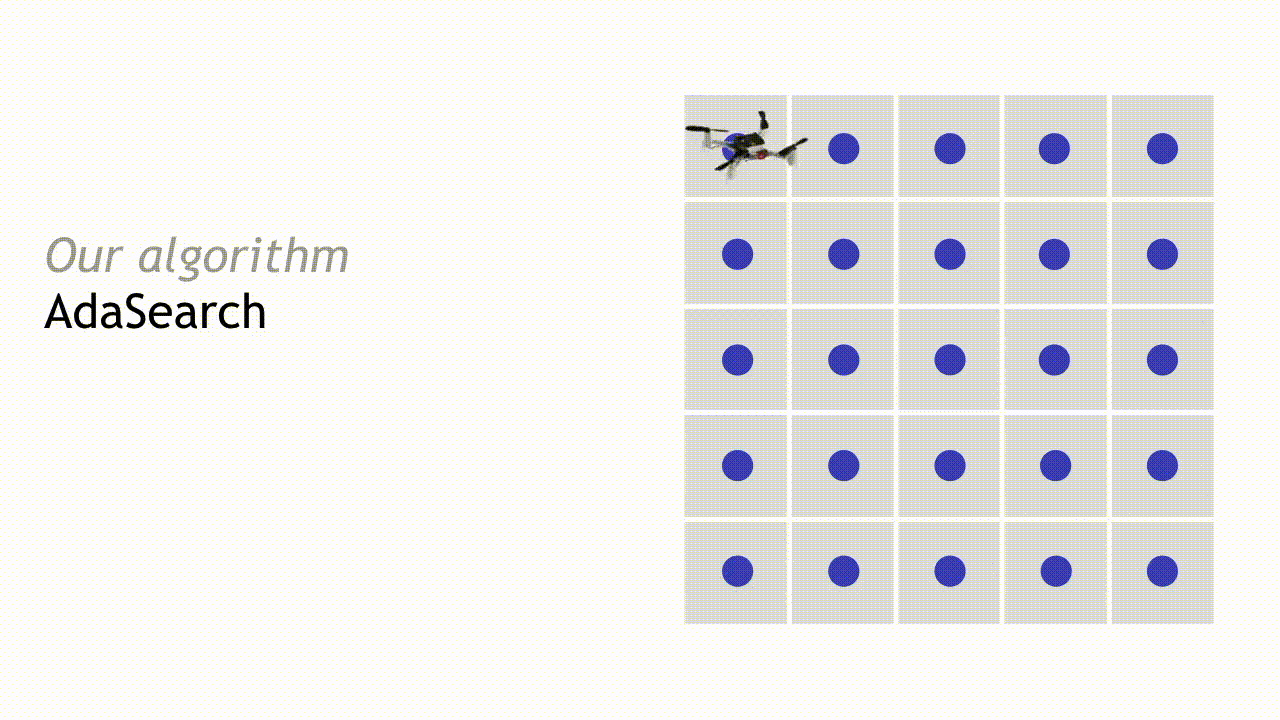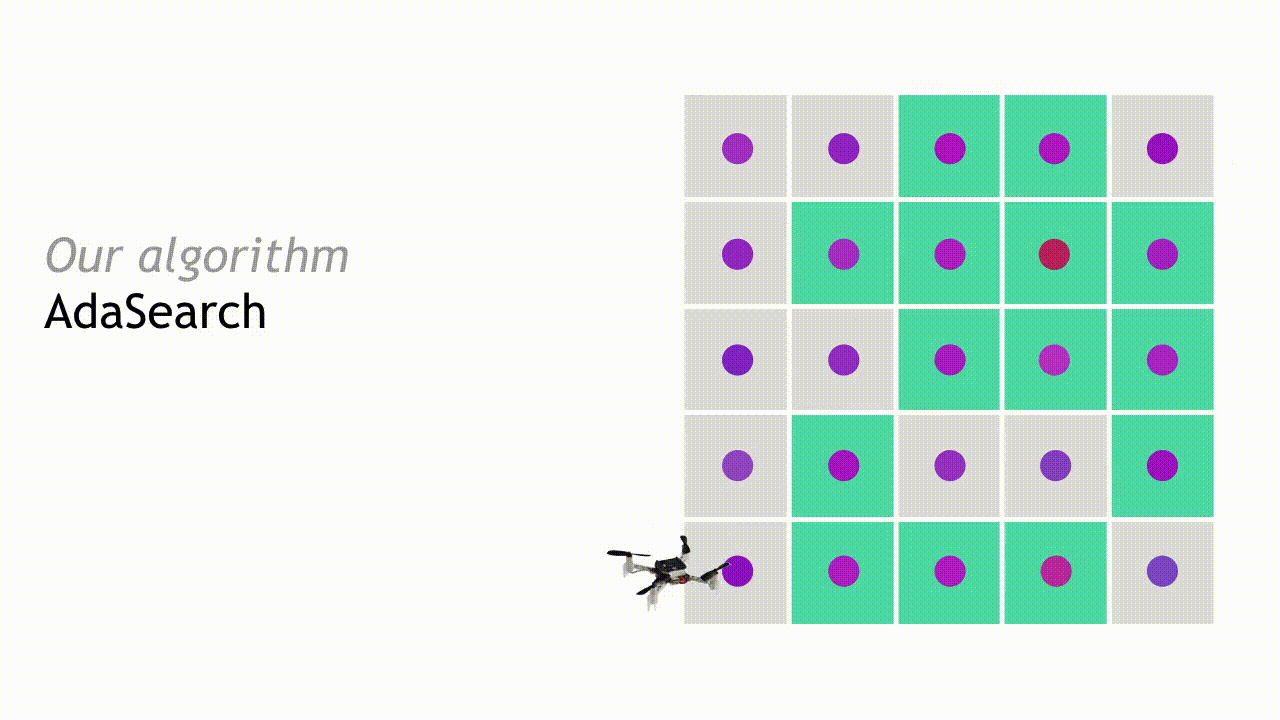
After observing the measurements during the first pass, we can eliminate some regions from consideration. Points are eliminated if the upper bound of our estimated confidence interval around their mean is smaller than the largest lower bound of any interval. This means that with high probability, they are not the source that we’re looking for.
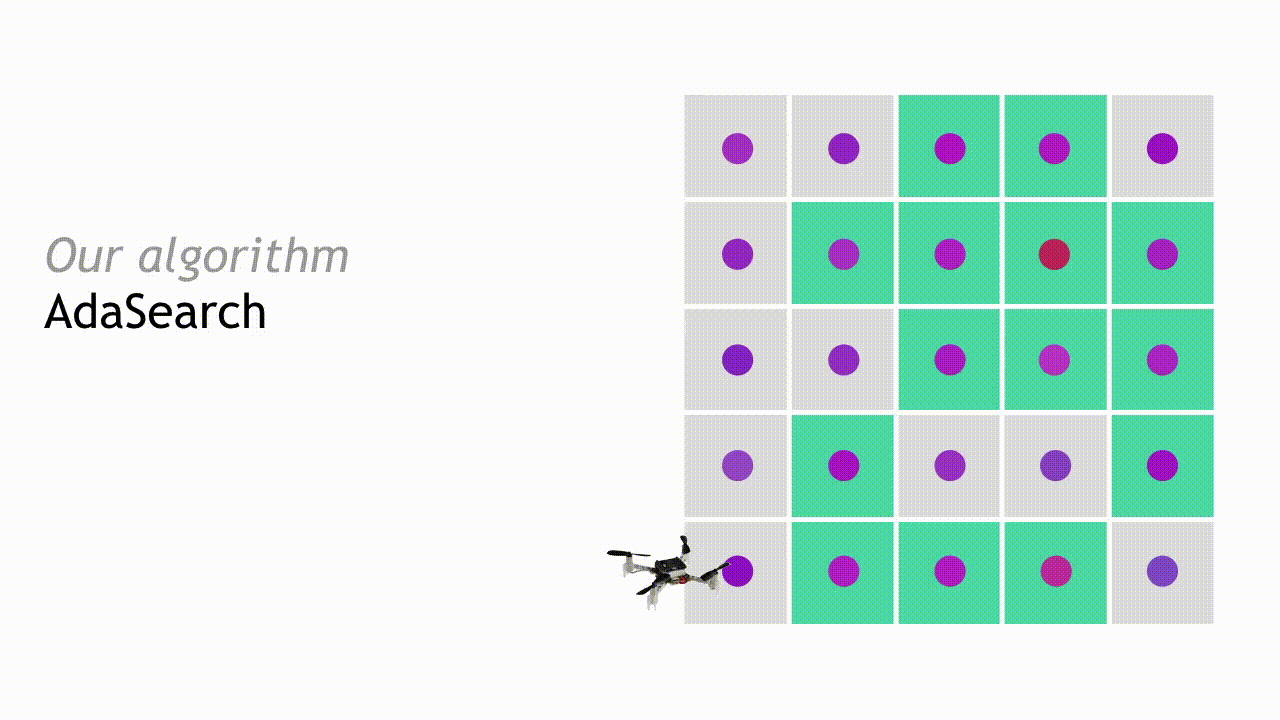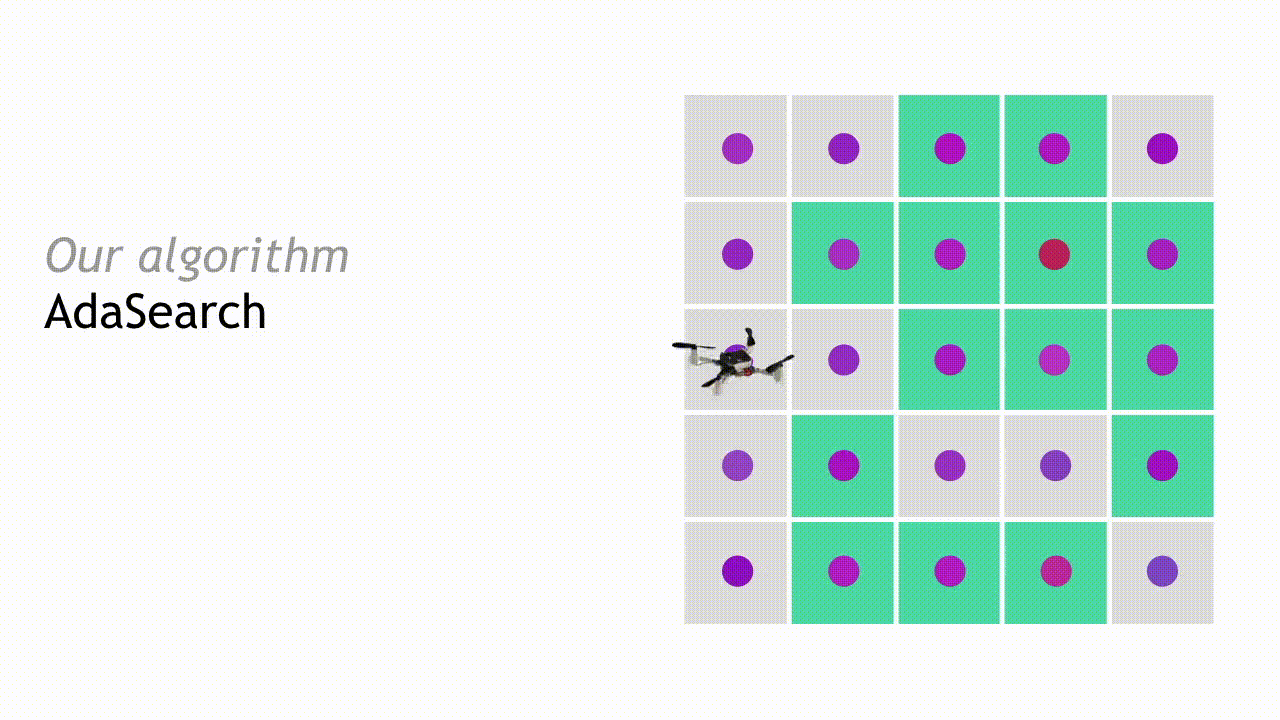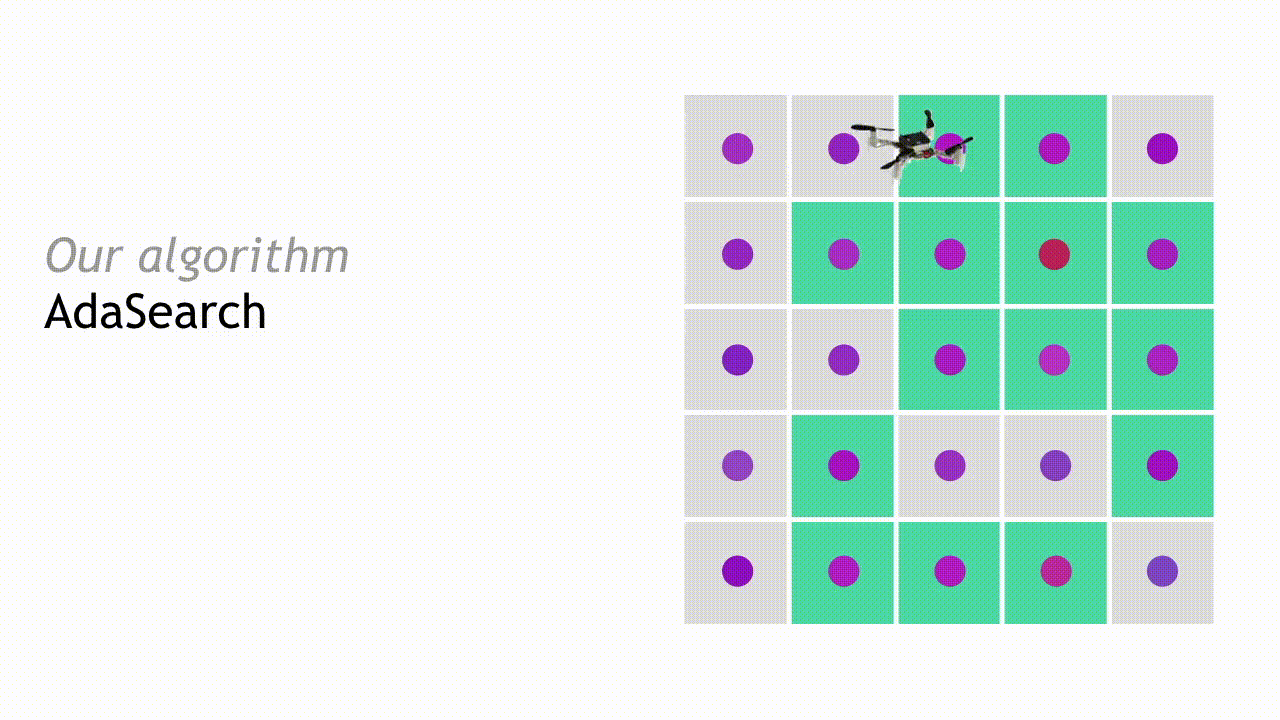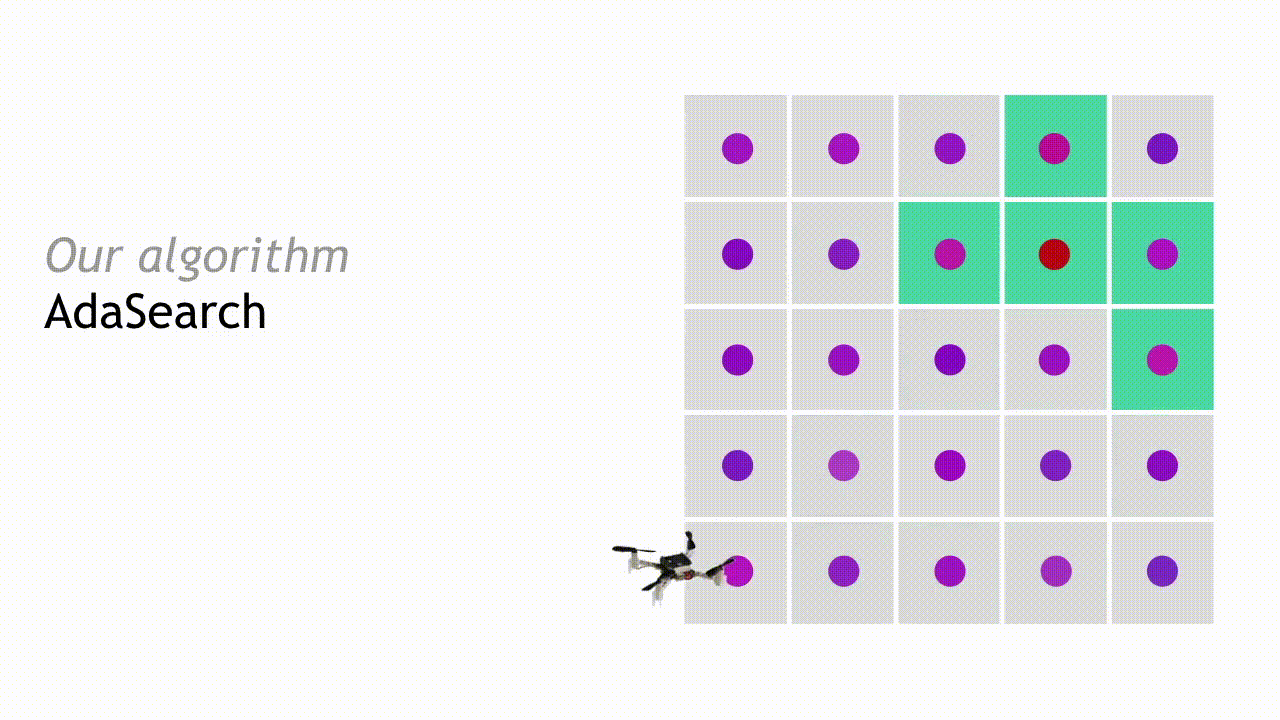
In the next round, AdaSearch focuses on sampling the remaining points (teal squares) more carefully, because they are still potential source locations.
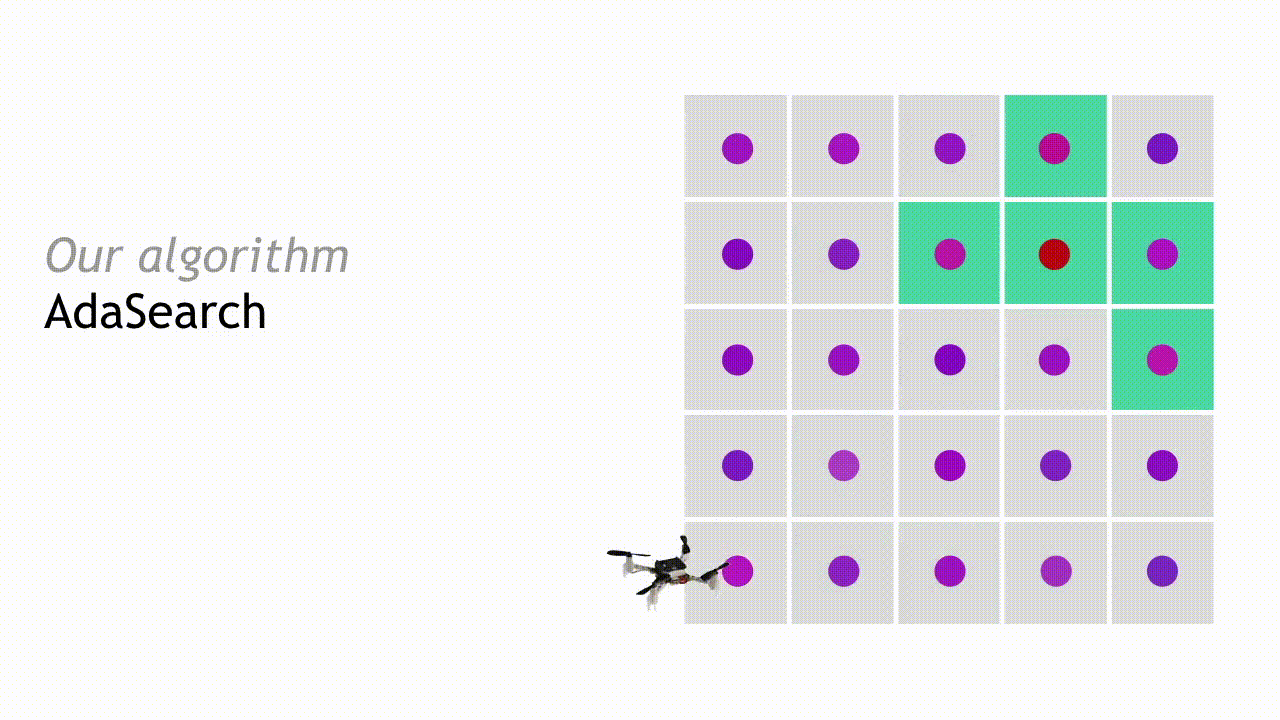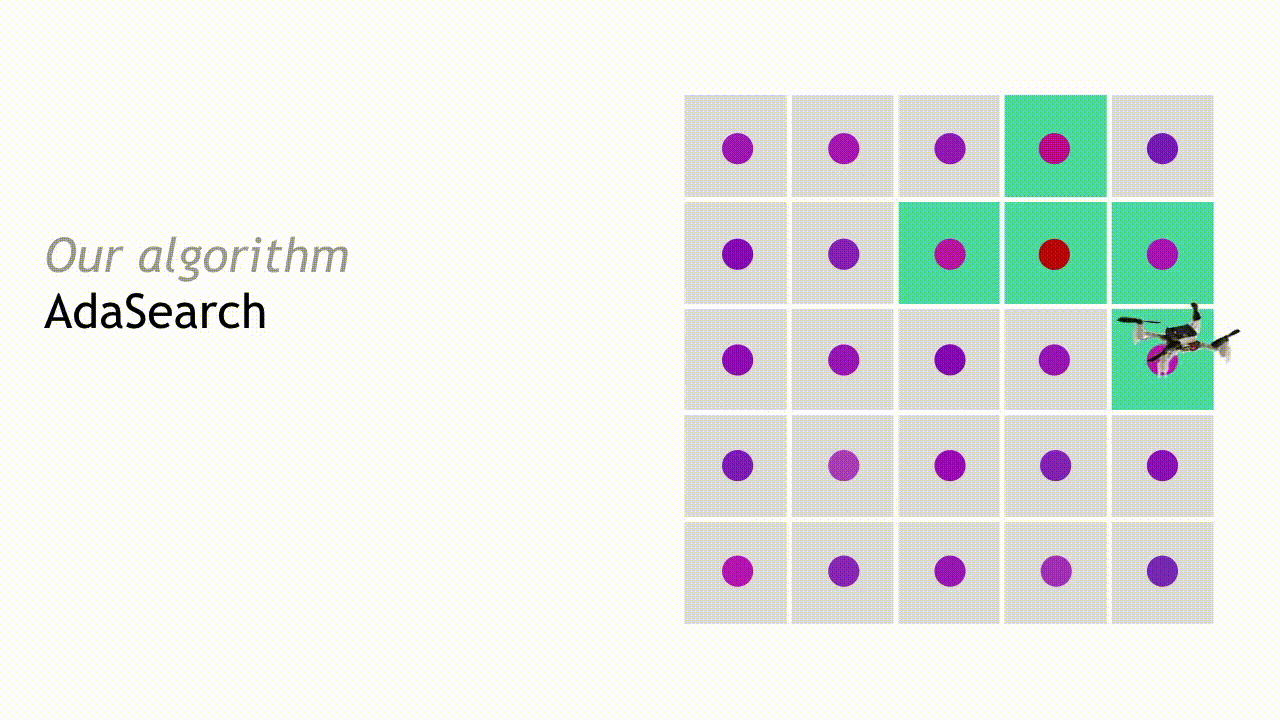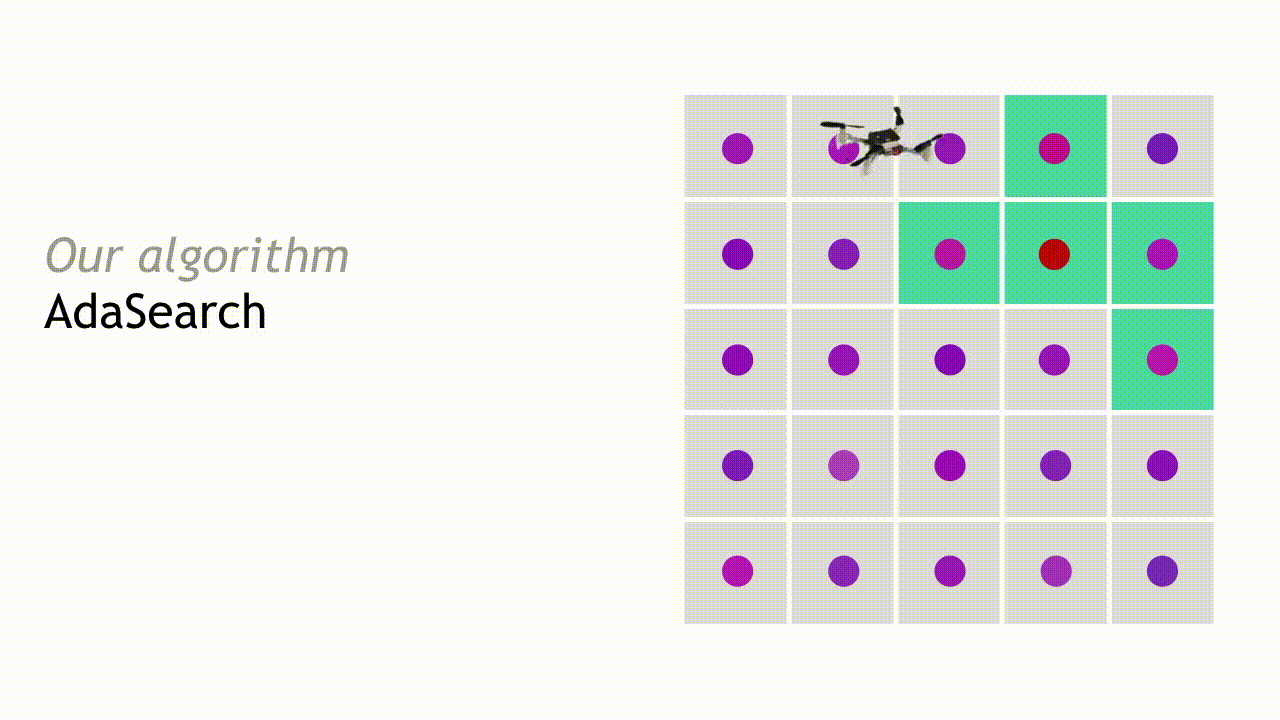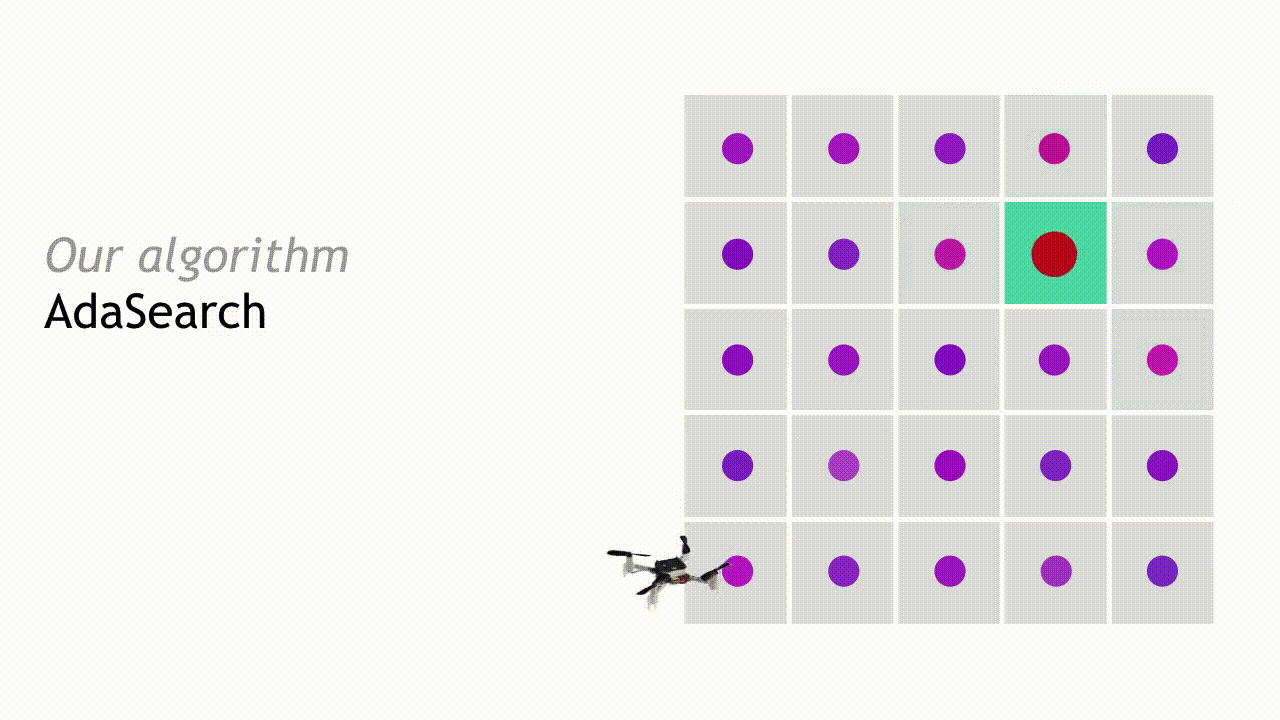
This process continues, and with each round the set of candidate source locations shrinks until only a single point remains. AdaSearch returns this point (enlarged red point) as the radioactive point source we were searching for.
Due to the crisp statistical formulation of confidence, we can be sure that under known sensing models, AdaSearch returns the correct source with high probability. We ensure a certain level of confidence in this probabilistic guarantee by fixing the width (in standard deviations) of the confidence bounds around each individual region, throughout the course of the algorithm. Furthermore, AdaSearch comes with environment-specific runtime guarantees, as we describe in detail in our paper.
Baselines
Perhaps the most popular approach for general adaptive search problems is information maximization (Bourgault et al.). Information maximization methods collect measurements in locations deemed promising according to an information theoretic criterion, and follow a receding horizon strategy to plan trajectories. We compare AdaSearch to a version of information maximization tailored to radiation detection: InfoMax.
Unfortunately, for large search spaces, the real-time computational constraints of this approach necessitate approximations such as limits on planning horizon and trajectory parameterization. These approximations may cause the algorithm to be excessively greedy and spend too much time tracking down false leads.
To disambiguate between the effects of our statistical confidence intervals and global planning heuristic (vs. InfoMax’s information metric and receding horizon planning), we implement as a simple global planning approach, NaiveSearch, as a second baseline. This approach samples the grid uniformly, spending an equal amount of time at each grid cell.
Results
We implemented all three algorithms and simulated their performance on ten randomized instantiations of the problem on a 64 by 64 meter grid, at 4 meter resolution, using realistic quadrotor dynamics and simulated radiation sensor readings.
In our experiments, we observe that AdaSearch usually finishes faster than NaiveSearch and InfoMax. As we increase the maximum background radiation level, the ratio of AdaSearch’s run time to NaiveSearch’s runtime continues to improve, which matches the theoretical bounds given in the full paper.
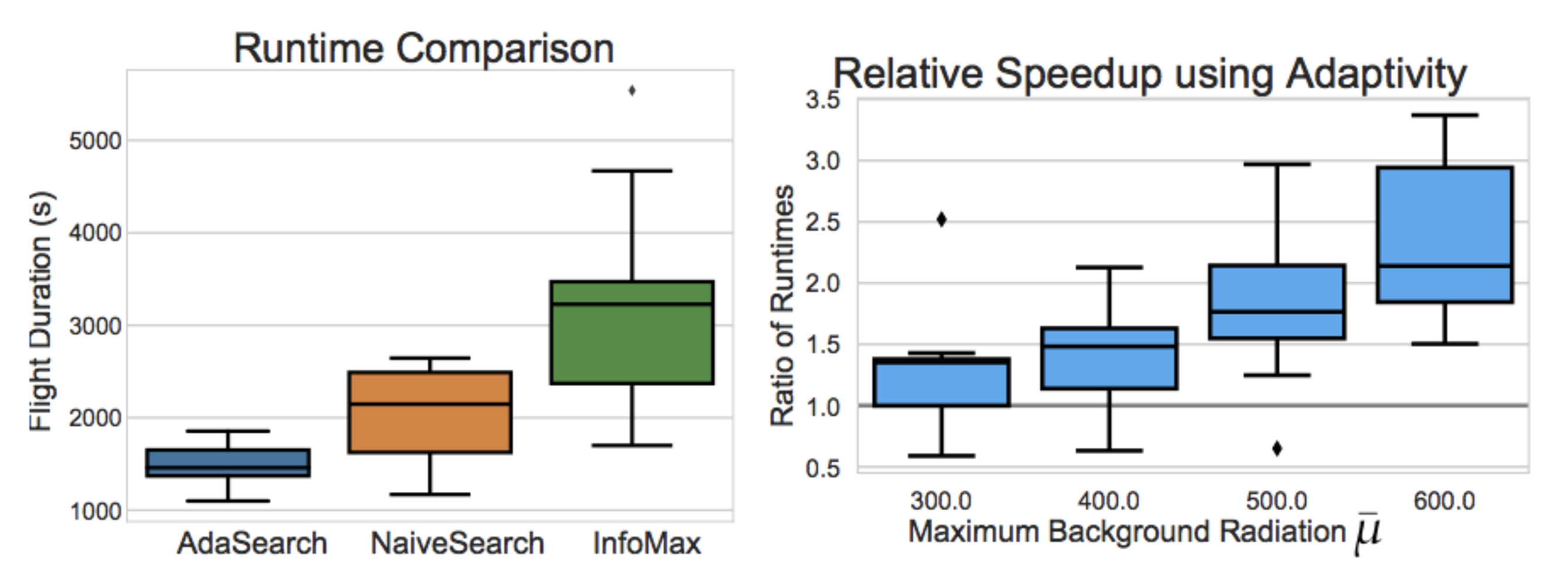
The increase in performance between AdaSearch and NaiveSearch suggests that adaptivity does confer advantages over non-adaptive methods. Even more strikingly, and somewhat unexpectedly, even NaiveSearch tends to outperform InfoMax in this problem setting. This suggests that the locally greedy nature of receding horizon control in InfoMax is indeed hurting its performance. AdaSearch, by contrast, gracefully blends adaptive strategies with global coverage guarantees.
AdaSearch more generally
The successful demonstration of AdaSearch operating onboard a UAV in the context of finding radioactive sources prompts us to ask, in what more general problem settings will AdaSearch also perform well? As it turns out, the core algorithm applies more broadly, even to non-robotic embodied sensing problems.
For example, consider the problem of planning a pilot program at 10 out of 100 medical clinics spread across a region. We might wish to establish these programs in the locations with the highest rates of a particular rare disease by conducting surveys across potential clinic locations to assess rates of illness in each region. This is an embodied sensing problem, as diagnoses are made in person. Resources are limited in terms of the number of human surveyors, and there are physical constraints both on the time required to survey a group of people, and on the travel time between towns.
A survey planner could use AdaSearch to guide the decisions of how long to spend in each potential clinic location counting new cases of the disease before moving on to the next, and to trade-off the travel time of returning to collect more data from a certain town with spending extra time at the town in the first place.
In general, AdaSearch is expected to perform well when we think that measurements are noisy enough to warrant multiple passes through space when collecting data. Radioactive gamma ray emissions, as well as occurances of a rare disease, can be modeled as Poisson distributed random variables, where the variance scales with the mean. AdaSearch easily adapts to different noise models (e.g. Gaussian), which might arise with different applications. So long as we can calculate or bound the appropriate confidence intervals, AdaSearch guarantees an efficient traversal of the region to find the points of interest.
For more information about AdaSearch, please see full video at the top of the page, and the full text of the paper at: https://arxiv.org/abs/1809.10611.