



Top left: image of a 3D cube. Top right: example depth image, with darker points
representing areas closer to the camera (source: Wikipedia). Next two
rows: examples of depth and RGB image pairs for grasping objects in a bin. Last
two rows: similar examples for bed-making.
This post explores two independent innovations and the potential for combining them in robotics. Two years before the AlexNet results on ImageNet were released in 2012, Microsoft rolled out the Kinect for the X-Box. This class of low-cost depth sensors emerged just as Deep Learning boosted Artificial Intelligence by accelerating performance of hyper-parametric function approximators leading to surprising advances in image classification, speech recognition, and language translation. Today, Deep Learning is also showing promise for end-to-end learning of playing video games and performing robotic manipulation tasks.
For robot perception, convolutional neural networks (CNNs), such as VGG or ResNet, with three RGB color channels have become standard. For robotics and computer vision tasks, it is common to borrow one of these architectures (along with pre-trained weights) and then to perform transfer learning or fine-tuning on task-specific data. But in some tasks, knowing the colors in an image may provide only limited benefits. Consider training a robot to grasp novel, previously unseen objects. It may be more important to understand the geometry of the environment rather than colors and textures. The physical process of manipulation — controlling one or more objects by applying forces through contact — depends on object geometry, pose, and other factors which are largely color-invariant. When you manipulate a pen with your hand, for instance, you can often move it seamlessly without looking at the actual pen, so long as you have a good understanding of the location and orientation of contact points. Thus, before proceeding, one might ask: does it makes sense to use color images?
There is an alternative: depth images. These are single-channel grayscale images that measure depth values from the camera, and give us invariance to the colors of objects within an image. We can also use depth to “filter” points beyond a certain distance which can remove background noise, as we demonstrate later with robot bed-making. Examples of paired depth and real images are shown above.
In this post, we consider the potential for combining depth images and deep learning in the context of three ongoing projects in the UC Berkeley AUTOLab: Dex-Net for robot grasping, segmenting objects in heaps, and robot bed-making.
Sensing Depth
Depth images encode distance (e.g., in millimeters) of surfaces in a scene relative to a particular viewpoint. We provide an example in the image at the top of this post. On the top left is an RGB image of a 3D cube structure, which has points located at a variety of distances from the camera. To the top right is one representation of a depth image, with darker points representing closer surfaces, though it is also valid to use other representations, such as using darker points for farther areas, or to use depth with respect to a different origin. For additional background on how depth images can be created, check out this blog post by the Comet Labs Research Team.
Recent Advancements in Depth Sensing
Recently, there have been a number of advancements in depth sensing which have occurred in parallel with improvements in computer vision and deep learning.
Classically, depth sensing involved matching pairs of points between aligned RGB images from two different cameras, and then using the resulting disparity map to obtain the depth of objects in the environment.
The depth sensors we commonly use today are structured light sensors, which project a known pattern into the scene using a non-visible wavelength. The Kinect innovation in particular was to project a known pattern from an infrared (IR) projector and image that pattern with a single IR camera. Since light travels in straight lines, a virtual IR camera placed at the projector would always capture the same image of the pattern. Therefore, the image pattern from the real IR camera can be matched against a pre-saved “template” image to find correspondences. This can be done quickly on embedded hardware.
Another approach to depth sensing is LIDAR, an older technique which is commonly used for surveying land and terrain, and has recently been applied for some self-driving cars. LIDAR, while generally providing higher-quality depth maps than Kinect, is slower and more expensive due to the need to scan lasers.
In sum, the Kinect is a consumer-grade RGB-D system that captures RGB images along with per-pixel depth values directly with the hardware, and is faster and cheaper (without sacrificing too much accuracy) than prior solutions. Nowadays, many robots available today for research and industrial purposes, such as the Fetch Robot and the Toyota Human Support Robot, come equipped with similar built-in depth sensing cameras. Future advancements in depth sensing for robots may come from improvements in existing cameras such as Intel’s RealSense, or from newer technologies introduced by companies such as Photoneo.
Prior Research Using Depth Images
The availability of depth sensing in robotics hardware has allowed depth images to be used for real-time navigation (Maier et al., 2012), for real-time mapping and tracking (Newcombe et al., 2011), and for modeling indoor environments (Henry et al., 2012). Since depth allows robots to understand how far they are from obstacles, it enables them to locate and avoid them during navigation.
Depth images have additionally been used to detect, identify and localize body parts of humans in real time (Plagemann*, Ganapathi*, et al., 2010) with high reliability on real gaming systems (e.g., the Xbox One). Depth could remove or mitigate sources of ambiguity, such as lighting and the wide variety of human appearances and clothing. Other recent work uses simulated depth images to develop closed-loop policies to guide a robot arm towards an object (Viereck et al., 2017). In their case, the advantage of depth images was that large datasets could be rapidly generated in simulation, and the depth images were simulated relatively accurately using ray tracing.
These results suggest that for some tasks, depth images can encode a sufficient amount of useful information and color invariance can be beneficial. We describe three such cases below.
Example 1: Robot Grasping
Universal picking – grasping a large variety of previously unseen objects – remains a Grand Challenge for robotics. Although many researchers (e.g., Pinto and Gupta, 2016) use RGB images, their systems need many months of training time with robots physically executing grasps. A key advantage of using 3D object meshes is that one can synthesize accurate depth images via rendering techniques, which use geometry and camera projection (Johns et al., 2016, Viereck et al., 2017).
Our Dexterity Network (Dex-Net) is an ongoing research project in the AUTOLab that encompasses algorithms, code, and datasets for training robot grasping policies using a combination of large synthetic datasets, analytic robustness models, stochastic sampling, and deep learning techniques. Dex-Net introduced domain randomization in the context of grasping, focusing on grasping complex objects with a simple gripper in contrast to recent work from OpenAI showing the value of domain randomization for grasping simple objects with a complex gripper. In a prior BAIR Blog post, we presented a dataset with 6.7 million samples in it, which was used to train a grasp quality model. Here, we expand the discussion with a focus on depth images.
Dataset and Depth Images
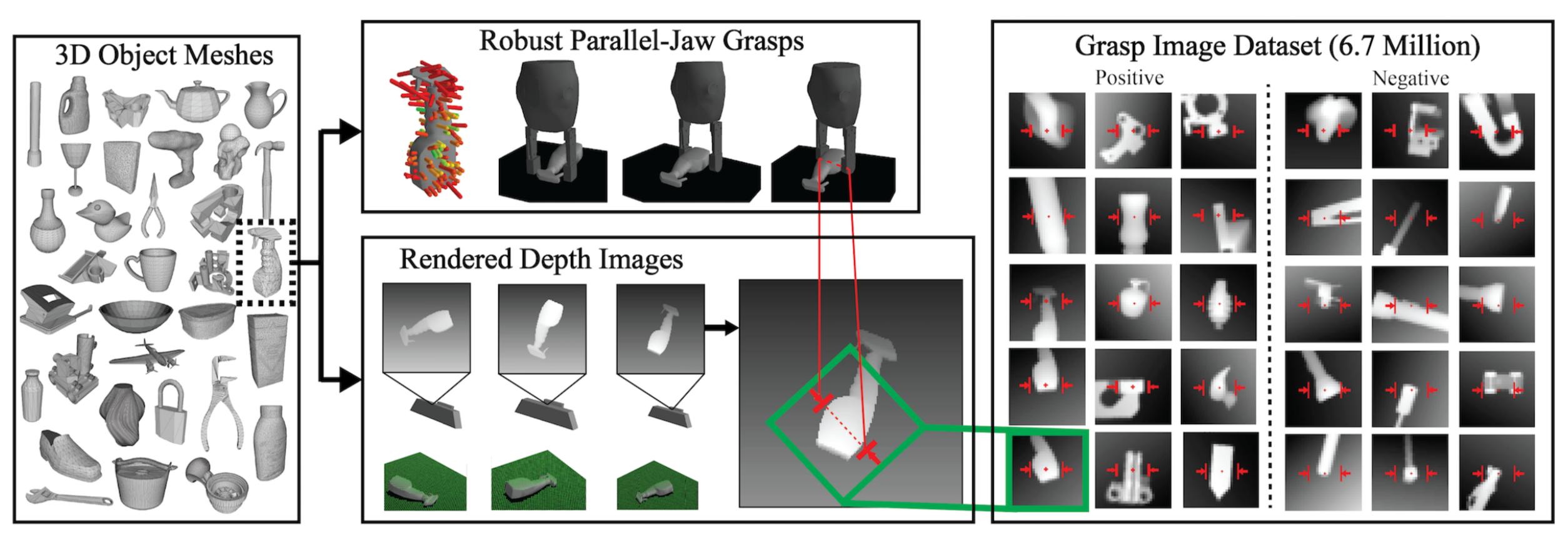
The dataset generation process for Dex-Net. First, a large number of object mesh
models are generated and augmented from a variety of sources. For each model,
multiple parallel-jaw grasps are sampled for it. For each object and grasp
combination, we compute the robustness and generate a simulated depth image.
Robustness is computed by estimating the probability of grasp success over a
stochastic distribution on pose, friction, mass, and external forces (e.g.,
gravity direction) with Monte-Carlo Integration. To the right, we show samples
of positive and negative (success vs failure) grasp attempts, and show the
images that the network sees; the red grasp overlays are only for visualization
purposes. (Open in a new window to enlarge.)
We recently extended Dex-Net to automatically generate a modified synthetic dataset of grasps on object meshes. Grasps are specified as the planar position, angle, and depth of a gripper relative to an RGB-D sensor. We present an overview of the data formation process in the figure above. Our overall goal is to train a deep network that can detect whether a grasp attempt on some (singulated) object, represented in a depth image, will succeed.
Training a GQ-CNN
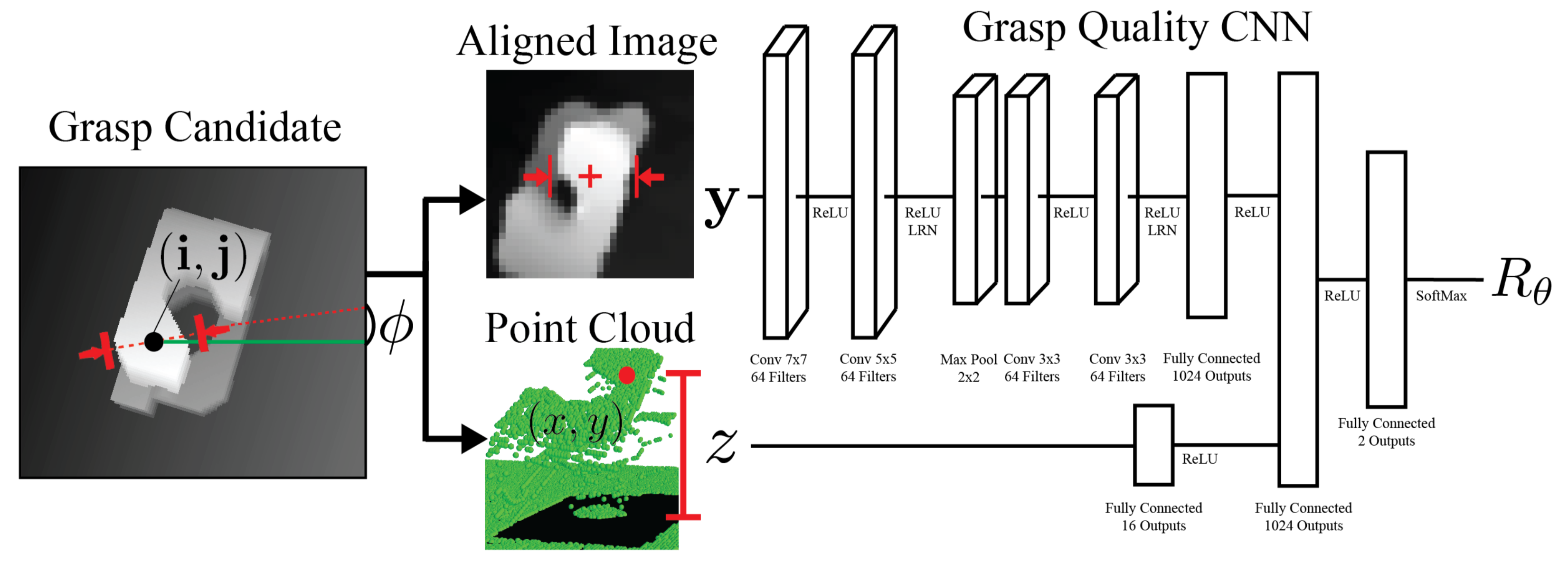
The Grasp Quality CNN architecture. A grasp candidate image (shown to the left)
is processed and aligned based on the angle and center of the grasp, and a
corresponding 96x96 depth image (labeled "Aligned Image") is passed as input,
along with the height $z$, to predict grasp robustness.
The simulated dataset is used to train a Grasp Quality Convolutional Neural Network (GQ-CNN) to determine how likely a grasp attempt will succeed. One can use this GQ-CNN in a policy. For example, a policy could sample various grasps and feed each through the GQ-CNN, pick the one with the highest grasp success probability, and then execute its corresponding open-loop trajectory. For an overview of our results, please see our prior BAIR Blog post.
In 2017, Dex-Net was extended to bin-picking, which involves iteratively grasping objects from heaps. We modeled bin-picking as a Partially Observed Markov Decision Process, and generated object heaps via simulation. Due to the simulation, we were able to obtain full knowledge of the object poses, and used an algorithmic supervisor to perform demonstrations of the task. We then fine-tuned a GQ-CNN and performed imitation learning on the supervisor’s policy. Using the resulting learned policy on a physical ABB YuMi robot, we were able to clear heaps of 10 objects in under three minutes using only information from the depth cameras.
Below, we show examples of real and simulated depth images which show grasps from the Dex-Net system in a setup with multiple objects in a bin.

Top row: real depth images taken from the camera mounted over our ABB YuMi
robot. Bottom row: simulated depth images from Dex-Net. The red overlays
indicate the grasp attempt.
Example 2: Segmenting Objects in Bins
Instance segmentation is the task of determining which pixels in an image belong to which object, while also separating instances of the same class. Instance segmentation is widely used for robot perception; for example, as the initial step in a robotic perception pipeline for grasping objects cluttered in a bin, where the robot first segments the image to localize the target object to grasp before executing a grasping policy.
Prior research in computer vision has demonstrated that Mask R-CNN can be trained to segment objects in RGB images, but this training requires massive hand-labeled datasets of real RGB images. In addition, images used for training Mask R-CNN tend to represent natural scenes with limited numbers of object classes. Thus, pretrained Mask R-CNN networks may not perform well on a task such as segmenting arbitrary objects in a warehouse bin, and fine-tuning would require knowledge and hand-labeled examples of each object. If we relax our requirement that we predict each object’s class in addition to its mask, we can predict masks for a larger set of object classes, and object geometries become more influential than object identities.
Dataset and Depth Images

Our dataset formation process. Left: we sample 3D object models similar to those
used in Dex-Net. These are shuffled and dropped into an object heap, either
through simulation or through physical experiments. The corresponding depth
images are created, along with object masks for training and ground-truth
evaluation.
For geometry-based segmentation, we can use simulation and rendering techniques to automate the process of collecting large and diverse training datasets of labeled depth images, as shown in the figure above. We hypothesize that these depth images may contain enough information about segmentation cues, since discontinuities are indicative of the “pixel borders” of objects. Our simulated dataset of 50K depth images was generated by sampling several 3D objects out of 1600 models, and dropping them into a bin via PyBullet simulation. Since the object models are known, we can automatically generate accurate depth images along with ground-truth masks. Using this dataset, we trained a version of Mask R-CNN, which we call SD Mask R-CNN, only on synthetic depth data.
Segmentation Results on Real Images

The results suggest that our SD Mask R-CNN can accurately segment despite not
being trained on any real images. We show an example bin picking setup, the
depth image, the ground truth segmentation, two baselines, and our method. The
two rows represent the same bin-picking setup, but with two sensors: high
resolution (top) and low resolution (bottom). (Open in a new window to enlarge.)
Our proposed SD Mask R-CNN outperforms point cloud segmentation and fine-tuned Mask R-CNN on a dataset of real images despite not being trained on any real images. An example of segmentation results and other related images are shown above. Importantly, the objects used in creating the hand-labeled dataset of real images were not chosen from the training distribution of SD Mask R-CNN; in fact, they were common household items for which we do not have 3D models. Thus, SD Mask R-CNN can predict masks for previously unseen objects. Moreover, we find that we can reduce the size of the backbone network of Mask R-CNN (e.g., from ResNet-101 to ResNet-35) for depth images as compared to training with color images.
Segmenting objects as “object” or “background” allows for decoupling of the classification and segmentation stages; we found that for a set of ten objects, we could train a VGG classifier in less than ten minutes that could achieve over 95% classification accuracy. These results suggest that SD Mask R-CNN could be used in tandem with a classification network, which could easily be retrained for each set of objects used.
Overall, our segmentation results suggest three main benefits of using depth over RGB images:
- depth information may encode the geometric cues necessary to separate object instances both from each other and the background of the image,
- synthetic depth images can be easily and rapidly generated, and training on them can effectively transfer to real images,
- a network trained using depth images can potentially generalize better to previously unseen objects, as geometric cues can be more consistent across objects.
Example 3: Robot Bed-Making
Bed-Making is a task we believe could be well-suited for home robotics since it is tolerant to error, not time critical, and rarely enjoyed by humans. We introduced the bed-making task in an earlier blog post and explored it with RGB images as a sequential decision problem with noise injection applied for better imitation learning. In our recent preprint, we used depth sensing to extend this project to explore transfer between blankets of different colors and textures and between robots.
Dataset and Depth Images

Examples of initial states for the bed-making task. The first four columns show
samples in the training data. The last two demonstrate the Cal and Teal blankets
that we used to test generalization to different blankets. (Open in a new window
to enlarge.)
We framed the bed-making task as one of detecting corners of a blanket, so that a mobile home robot such as the Fetch or the HSR, can grasp and pull the blanket to a corner of the bed frame to maximize blanket coverage. Our starting hypothesis was that depth images contained enough information about the geometry of blanket corners to allow for reliable bed-making.
To collect training data, we use white blankets with marked red corners, as shown in the above image, so that we can automatically detect a corner and thus a grasping target. We repeatedly toss blankets on the bed surface and collect RGB and depth images from the robot’s onboard RGB-D sensors.
We next train a deep convolutional neural network to detect corners from depth images only, with the hope that the network will generalize to detecting corners from depth images of different blankets. Our deep network utilizes pre-trained weights from YOLO, a fast real-time object detector, because the task of finding a grasping point is similar to detection. We then add several layers after this, which we train with our dataset of 2018 depth images (and yes, 2018 is just a coincidence). Our results indicate that using pre-trained weights is beneficial despite the depth versus RGB mismatch; the pre-trained weights from YOLO were obtained by training on RGB images.
Another advantage of depth images is that it lets us remove sources of distraction. For example, we want the robots to grasp blanket corners. These are not located in areas far beyond the top surface of the bed. Thus, we can “black out” regions beyond a validation-tuned depth value (we used 1.4 meters as the cutoff) before scaling pixels within $[0,255]$. We provide a simple script here that one can use for processing depth images.
Corner Detection Results

Visualization of a bed-making rollout with an emphasis on corner detection. In
the first row, the robot's trained grasp policy correctly identifies the corner
(top left) and the resulting situation after the grasp and pull is in the top
right. On the other side, the policy again detects the corner well (bottom left)
and the resulting grasp and pull is shown in the bottom right.
We deployed our trained grasping policy and found that in terms of blanket coverage, it significantly outperformed a non-learning baseline policy, and was nearly as good as a human supervisor. While our metric here is blanket coverage rather than detecting corners, accurate detection is strongly correlated with higher coverage.
In the above image, we show the corner predictions on a teal blanket with the red cross hair. The grasping network was not trained on teal blankets, and only saw the depth images, but nonetheless is able to detect corners accurately since the test-time depth images look similar to depth images from training. After the robot moves to the other side of the bed to attempt another grasp, it again does an excellent job in detecting the nearest corner. We tried using RGB-trained grasping policies, but these did not perform well since the original RGB trained policy was only on white blankets, and we would need far more blankets and training data to generalize across blanket colors.
Depth Matters
Our results in these projects suggest that depth maps contain sufficient clues for the tasks of determining grasp points, segmenting images, and detecting corners of deformable objects. We conjecture that, as the quality of depth cameras improves in tandem with reduction in costs, depth images will be an increasingly important modality for robotics. It is far easier to synthesize training examples with depth images, color-invariance results naturally, and background noise can be easily filtered (as we demonstrate in robot bed-making). Depth images are lower dimensional than RGB (one vs three 8-bit channels) and CNNs appear to learn filters for edges and spatial patterns in both.
Paper References
We encourage readers to check out the following papers and project websites for more details.
-
Dex-Net 2.0: Deep Learning to Plan Robust Grasps with Synthetic Point Clouds and Analytic Grasp Metrics.
Jeffrey Mahler, Jacky Liang, Sherdil Niyaz, Michael Laskey, Richard Doan, Xinyu Liu, Juan Aparicio Ojea, Ken Goldberg.
Robotics: Science and Systems (RSS), 2017.
Project Website -
Learning Deep Policies for Robot Bin Picking by Simulating Robust Grasping Sequences.
Jeffrey Mahler and Ken Goldberg.
Conference on Robot Learning (CoRL), 2017.
Project Website -
Segmenting Unknown 3D Objects from Real Depth Images using Mask R-CNN Trained on Synthetic Point Clouds.
Michael Danielczuk, Matthew Matl, Saurabh Gupta, Andrew Lee, Andrew Li, Jeffrey Mahler, Ken Goldberg.
arXiv preprint, arXiv:1809.05825
Project Website -
Robot Bed-Making: Deep Transfer Learning Using Depth Sensing of Deformable Fabric.
Daniel Seita*, Nawid Jamali*, Michael Laskey*, Ron Berenstein, Ajay Kumar Tanwani, Prakash Baskaran, Soshi Iba, John Canny, Ken Goldberg.
arXiv preprint, arXiv:1809.09810
Project Website
Additional papers and projects can be found at the AUTOLab website.