
Simulated characters imitating skills from YouTube videos.
Whether it’s everyday tasks like washing our hands or stunning feats of acrobatic prowess, humans are able to learn an incredible array of skills by watching other humans. With the proliferation of publicly available video data from sources like YouTube, it is now easier than ever to find video clips of whatever skills we are interested in. A staggering 300 hours of videos are uploaded to YouTube every minute. Unfortunately, it is still very challenging for our machines to learn skills from this vast volume of visual data. Most imitation learning approaches require concise representations, such as those recorded from motion capture (mocap). But getting mocap data can be quite a hassle, often requiring heavy instrumentation. Mocap systems also tend to be restricted to indoor environments with minimal occlusion, which can limit the types of skills that can be recorded. So wouldn’t it be nice if our agents can also learn skills by watching video clips?
In this work, we present a framework for learning skills from videos (SFV). By combining state-of-the-art techniques in computer vision and reinforcement learning, our system enables simulated characters to learn a diverse repertoire of skills from video clips. Given a single monocular video of an actor performing some skill, such as a cartwheel or a backflip, our characters are able to learn policies that reproduce that skill in a physics simulation, without requiring any manual pose annotations.
The problem of learning full-body motion skills from videos has received some attention in computer graphics. Previous techniques often rely on manually-crafted control structures that impose strong restrictions on the behaviours that can be produced. Therefore, these methods tend to be limited in the types of skills that can be learned, and the resulting motions can look fairly unnatural. More recently, deep learning techniques have demonstrated promising results for visual imitation on domains such as Atari and fairly simple robotics tasks. But these tasks often only have modest domain shifts between the demonstrations and the agent’s environment, and results on continuous control have largely been on tasks with relatively simple dynamics.
Framework
Our framework is structured as a pipeline, consisting of three stages: pose estimation, motion reconstruction, and motion imitation. The input video is first processed by the pose estimation stage, which predicts the pose of the actor in each frame. Next, the motion reconstruction stage consolidates the pose predictions into a reference motion and fixes artifacts that might have been introduced by the pose predictions. Finally, the reference motion is passed to the motion imitation stage, where a simulated character is trained to imitate the motion using reinforcement learning.
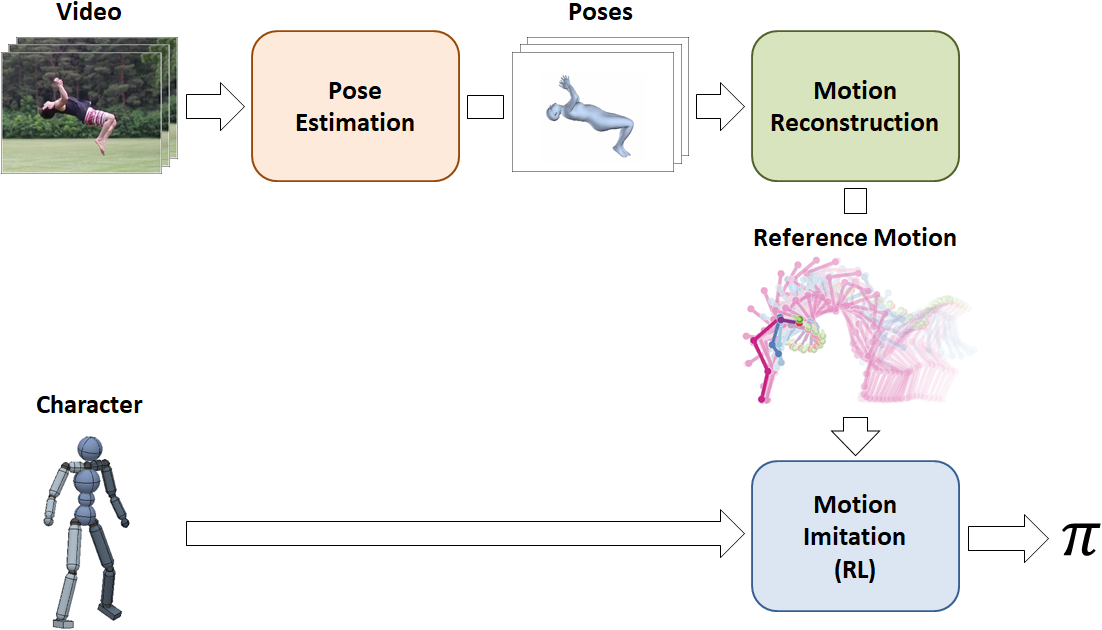
The pipeline consists of three stages: pose estimation, motion reconstruction,
and motion imitation. It receives as input, a video clip of an actor performing
a particular skill and a simulated character model, and learns a control policy
that enables the character to reproduce the skill in a physics simulation.
Pose Estimation
Given a video clip, we use a vision-based pose estimator to predict the actor’s pose $\hat{q}_t$ in each frame. The pose estimator is built on the work from human mesh recovery, which uses a weakly-supervised adversarial approach to train a pose estimator to predict poses from monocular images. While pose annotations are required to train the pose estimator, once trained, the pose estimator can be applied to new images without any annotations.


A vision-based pose estimator is used to predict the pose of the actor in each video frame.
Motion Reconstruction
Since the pose estimator predicts the pose of the actor independently for each video frame, the predictions between frames can be inconsistent, resulting in jittery artifacts. Furthermore, while vision-based pose estimators have improved substantially in recent years, they can still occasionally make some pretty big mistakes, which can result in peculiar poses popping up every now and then. These artifacts can produce motions that are physically impossible to imitate. Therefore, the role of the motion reconstruction stage is to mitigate these artifacts in order to produce a more physically-plausible reference motion that will be easier for the simulated character to imitate. To do this, we optimize a new reference motion \(\hat{Q} = \{ \hat{q}_0, \hat{q}_1, \ldots, \hat{q}_t \}\) to satisfy the following objective:
\[\min_{\hat{Q}} \; \; w_p l_p(\hat{Q}) + w_{sm} l_{sm}(\hat{Q})\]where $l_p(\hat{Q})$ encourages the reference motion to be similar to the original pose predictions, and $l_{sm}(\hat{Q})$ encourages the poses in adjacent frames to be similar in order to produce a smoother motion. In addition, $w_p$ and $w_{sm}$ are the weights for the different losses.
This procedure can substantially improve the quality of the reference motion, and can fix a lot of the artifacts from the original pose predictions.
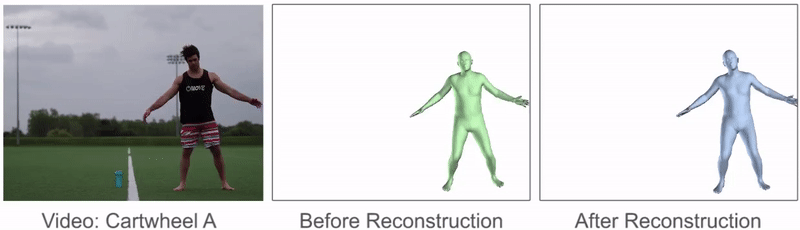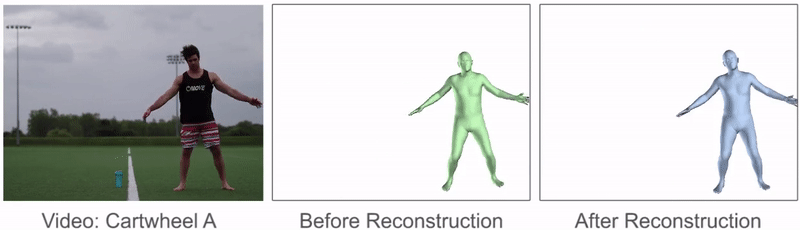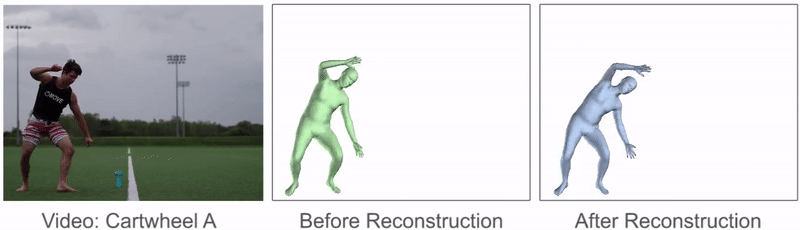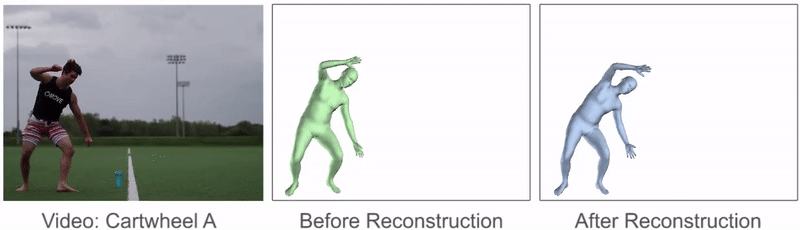
Comparison of reference motions before and after motion reconstruction. Motion
reconstruction mitigates many of the artifacts and produces a smoother reference
motion.
Motion Imitation
Once we have the reference motion \(\{\hat{q}_0, \hat{q}_1, \ldots, \hat{q}_T\}\), we can then proceed to training a simulated character to imitate the skill. The motion imitation stage uses a similar RL approach to the one we previously proposed for imitating mocap data. The reward function simply encourage the policy to minimize the difference between the pose of the simulated character and the pose of the reconstructed reference motion $\hat{q}_t$ at each frame $t$,
\[r_t = \exp \Big(-2 \|\hat{q}_t-q_t\|^2 \Big).\]Again, this simple approach ends up working surprisingly well, and our characters are able to learn a diverse repertoire of challenging acrobatic skills, where each skill is learned from a single video demonstration.




Simulated humanoids learn to perform a diverse array of skills by imitating video clips.
Results
In total, our characters are able to learn over 20 different skills from various video clips collected from YouTube.

Our framework can learn a large repertoire of skills from video demonstrations.
Even though the morphology of our characters are often quite different from the actors in the videos, the policies are still able to closely reproduce many of the skills. As an example of more extreme morphological differences, we can also train a simulated Atlas robot to imitate video clips of humans.



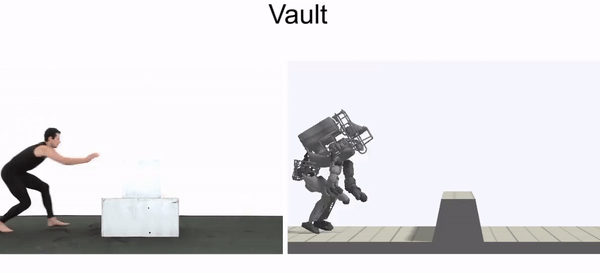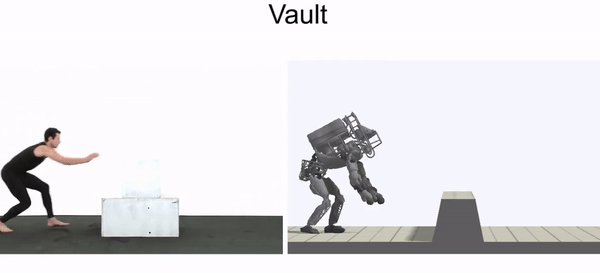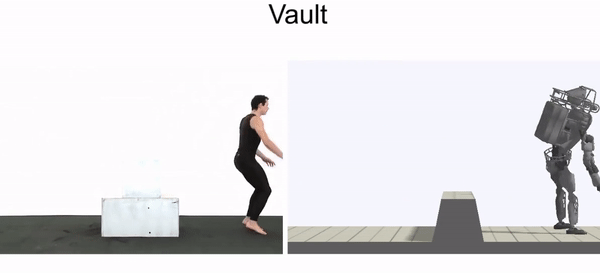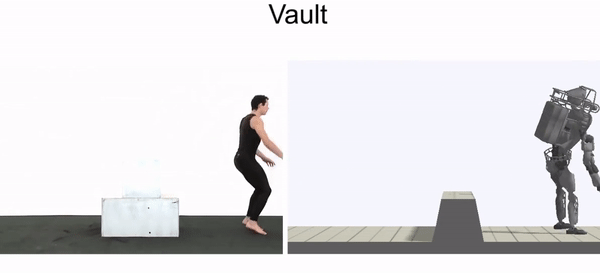
Simulated humanoid learns to perform a diverse array of skills by imitating video clips.
One of the advantages of having a simulated character is that we can leverage the simulation to generalize the behaviours to new environments. Here we have simulated characters that learn to adapt motions to irregular terrain, where the original video clips were recorded from actors on flat ground.


Motions can be adapted to irregular environments.
Even though the environments are quite different from those in the original videos, the learning algorithm still develops fairly plausible strategies for handling these new environments.
All in all, our framework is really just taking the most obvious approach that anyone can think of when tackling the problem of video imitation. The key is in decomposing the problem into more manageable components, picking the right methods for those components, and integrating them together effectively. However, imitating skills from videos is still an extremely challenging problem, and there are plenty of video clips that we are not yet able to reproduce:
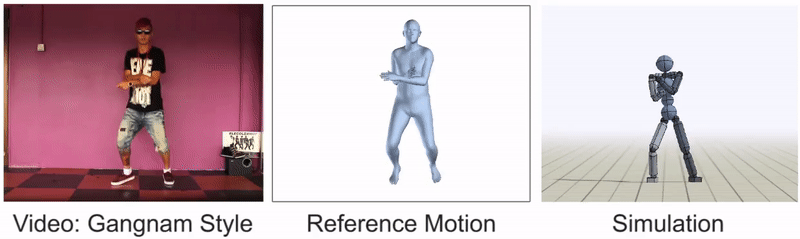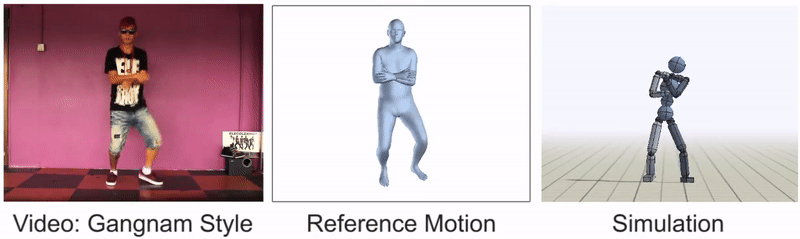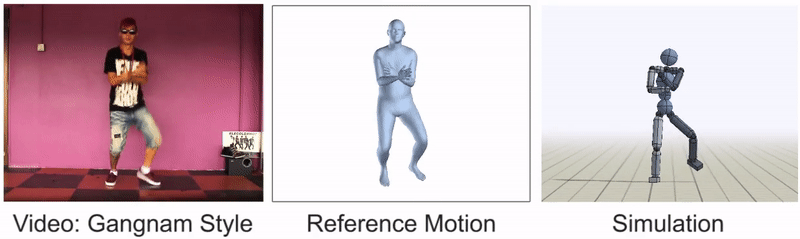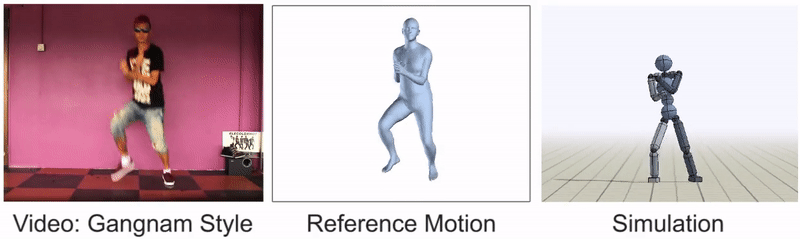
Nimble dance steps, such as this Gangnam style clip, can still be difficult to imitate.
But it is encouraging to see that just by integrating together existing techniques, we can already get pretty far on this challenging problem. We still have all of our work ahead of us, and we hope that this work will help inspire future techniques that will enable agents to take advantage of the massive volume of publicly available video data to acquire a truly staggering array of skills.
To learn more, check out our paper and the project webpage.
We would like to thank the co-authors of this work, without whom none of this would have been possible: Jitendra Malik, Pieter Abbeel, and Sergey Levine. This research was funded by NSERC, UC Berkeley, BAIR, and AWS.