We want to build agents that can accomplish arbitrary goals in unstructured complex environments, such as a personal robot that can perform household chores. A promising approach is to use deep reinforcement learning, which is a powerful framework for teaching agents to maximize a reward function. However, the typical reinforcement learning paradigm involves training an agent to solve an individual task with a manually designed reward. For example, you might train a robot to set a dinner table by designing a reward function based on the distance between each plate or utensil and its goal location. This setup requires a person to design the reward function for each task, as well as extra systems like object detectors, which can be expensive and brittle. Moreover, if we want machines that can perform a large repertoire of chores, we would have to repeat this RL training procedure on each new task.
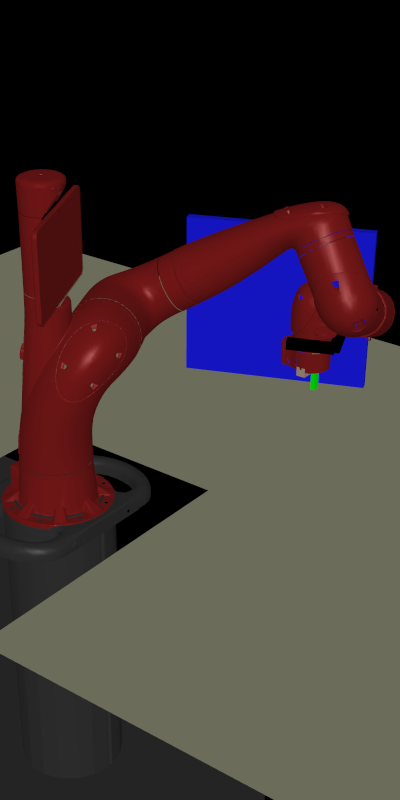



While designing reward functions and setting up sensors
(door angle measurement, object detectors, etc.) may be
easy in simulation, it quickly becomes impractical in
the real world (right image).

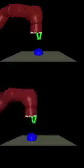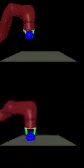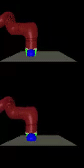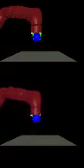


We train agents to solve various tasks from
vision without extra instrumentation. The top row shows goal images and the
bottom row shows our policies reaching those goals.
In this post, we discuss reinforcement learning algorithms that can be used to learn multiple different tasks simultaneously, without additional human supervision. For an agent to acquire skills without human intervention, it must be able to set goals for itself, interact with the environment, and evaluate whether it has achieved its goals to improve its behavior, all from raw observations such as images without manually engineering extra components like object detectors. We introduce a system that sets abstract goals and autonomously learns to achieve those goals. We then show that we can use these autonomously learned skills to perform a variety of user-specified goals, such as pushing objects, grasping objects, and opening doors, without any additional learning. Lastly, we demonstrate that our method is efficient enough to work in the real world on a Sawyer robot. The robot learns to set and achieve goals involving pushing an object to a specific location, with only images as the input to the system.
Goal-Conditioned Reinforcement Learning
How can we represent the state of the world and the goal? In a multi-task setting, enumerating all of the objects that the robot might need to pay attention to can become impractical: the number and types of objects might vary, and detecting them requires a dedicated vision pipeline. Instead, we can operate directly on the robot's sensors, representing the state as the image from the robot's camera and the goal as an image of the world as we would like it to be. To specify a new task, a user simply provides a goal image. We note that one could extend this work to more complex ways of specifying goals, such as through language or demonstrations, or by optimizing over goals as in this previous blog post.
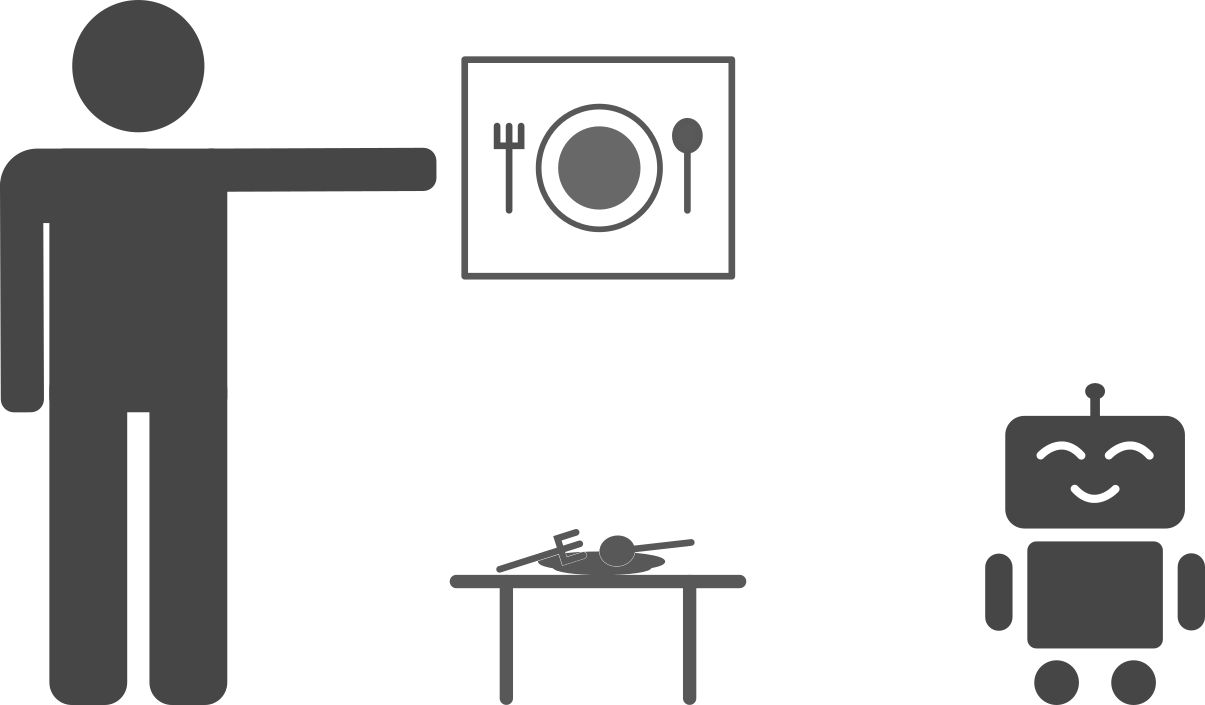
The task: Make the world look like this image.
Reinforcement learning is a formalism for training agents to maximize the sum of rewards. For goal-conditioned reinforcement learning, one choice for the reward is the negative distance between the current state and the goal state, so that maximizing the reward corresponds to minimizing the distance to a goal state.
We can train a single policy to maximize rewards and therefore reach goal states by first learning a goal-conditioned Q function. A goal-conditioned Q function $Q(s, a, g)$ tells us how good an action $a$ is, given the current state $s$ and goal $g$. For example, a Q function tells us, “How good is it to move my hand up (action $a$), if I’m holding a plate (state $s$) and want to put the plate on the table (goal $g$)?” Once this Q function is trained, you can extract a goal-conditioned policy by performing the following optimization
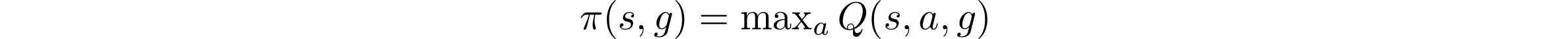
which effectively says, “choose the best action according to this Q function.” By using this procedure, we obtain a policy that maximizes the sum of rewards, i.e. reaches various goals.
One reason that Q learning is popular is that in can be done in an off-policy manner, meaning that the only things we need to train our Q function are samples of state, action, next state, goal, and reward: $(s, a, s’, g, r)$. This data can be collected by any policy and can be reused across multiples tasks. So a simple goal-conditioned Q-learning algorithm looks like this:

The main bottleneck in this training procedure is collecting data. If we could artificially generate more data, we could in theory learn to solve various tasks without even interacting with the world. Unfortunately, learning an accurate model of the world is difficult, so we usually have to rely on sampling to get state-action-next-state data, $(s, a, s’)$. However, if we have access to the reward function $r(s, g)$, we can retroactively relabeled goals and recompute rewards, allowing us to artificially generate more data given a single $(s, a, s')$ tuple. So, we can modify this training procedure like so:

The nice thing about this goal resampling is that we can simultaneously learn how to reach multiple goals at once without needing more data from the environment. Overall, this simple modification can result in substantially faster learning.
The method outlined above makes two major assumptions: (1) you have access to a reward function and (2) you have access to a goal sampling distribution $p(g)$. Prior works that use this goal relabeling strategy ( Kaelbling ‘93 , Andrychowicz ‘17 , Pong ‘18 ) operate on ground truth state information (e.g., the Cartesian position of an object), where it is easy to manually design both the goal distribution $p(g)$ and reward function. However, when moving to vision-based tasks where goals are images, both of these assumptions introduce practical concerns. For one, it is not clear which reward function we should use, as pixel-wise distance to a goal image may not be semantically meaningful. Second, because our goals are images, we need a goal image distribution $p(g)$ from which we can sample goal images. Manually designing a distribution over goal images is a non-trivial task and image generation is still an active field of research. Instead, we would like our agent to autonomously imagine its own goals and learn how to reach them.
Reinforcement Learning with Imagined Goals
We can mitigate the challenges associated with goal-image conditioned Q learning by learning a representation for images and using this representation, rather than the images themselves, for RL. The key question becomes: what properties should our representation satisfy? To compute semantically meaningful rewards, we need a representation that captures the underlying factors of variations of images. Furthermore, we need a way to easily generate new goals.
We achieve these objectives by first training a generative latent variable model, which in our case is a variational autoencoder (VAE). This generative model converts high-dimensional observations $x$, like images, into low-dimensional latent variables $z$, and vice versa. The model is trained so that the latent variables capture the underlying factors of variation in an image, similar to the abstract representations a human may use to interpret the world and goals. Given a current image $x$ and goal image $x_g$, we convert them into latent variables $z$ and $z_g$ respectively. We then use these latent variables to representation the state and goal for our reinforcement learning algorithm. Learning Q functions and policies on top of this low-dimensional latent space rather than directly on images results in faster learning.
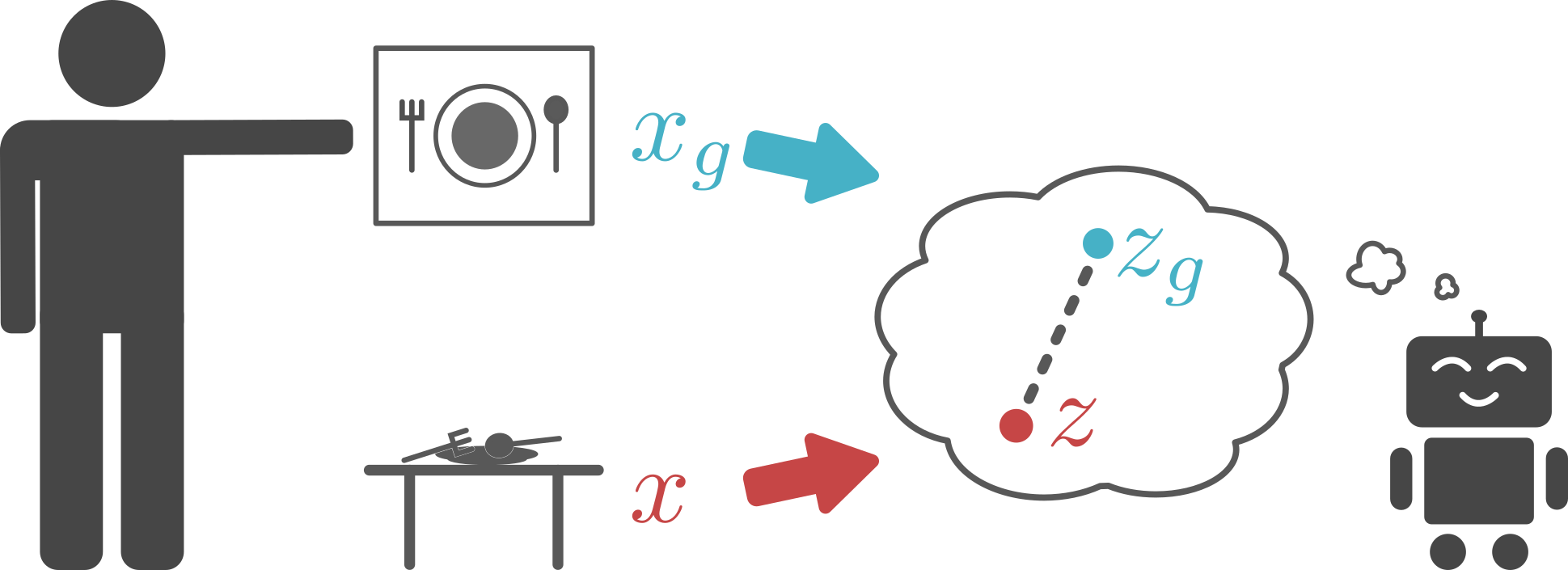
The agent encodes the current image ($x$) and goal
image ($x_g$) into a latent space and use distances in
that latent space for reward.
Using the latent variable representations for the images and goals also solves another problem: how to compute rewards. Rather than using pixel-wise error as our reward, we use the distance in the latent space for the reward to train our agent to reach a goal. In the full research paper describing our method, we show that this corresponds to maximizing the probability of reaching the goal and provides a much more effective learning signal.
This generative model is also important because it allows an agent to easily generate goals in the latent space. In particular, our generative model is designed so that sampling latent variables is trivial: we just sample latents from the VAE prior. We use this sampling mechanism for two reasons: First, it provides a mechanism for an agent set its own goals. The agent simply samples a value for the latent variable from our generative model, and tries to reach that latent goal. Second, this resampling mechanism is also used to relabel goals as mentioned above. Because our generative model is trained to encode real images into the prior, the samples from our latent variable prior correspond to meaningful latent goals.
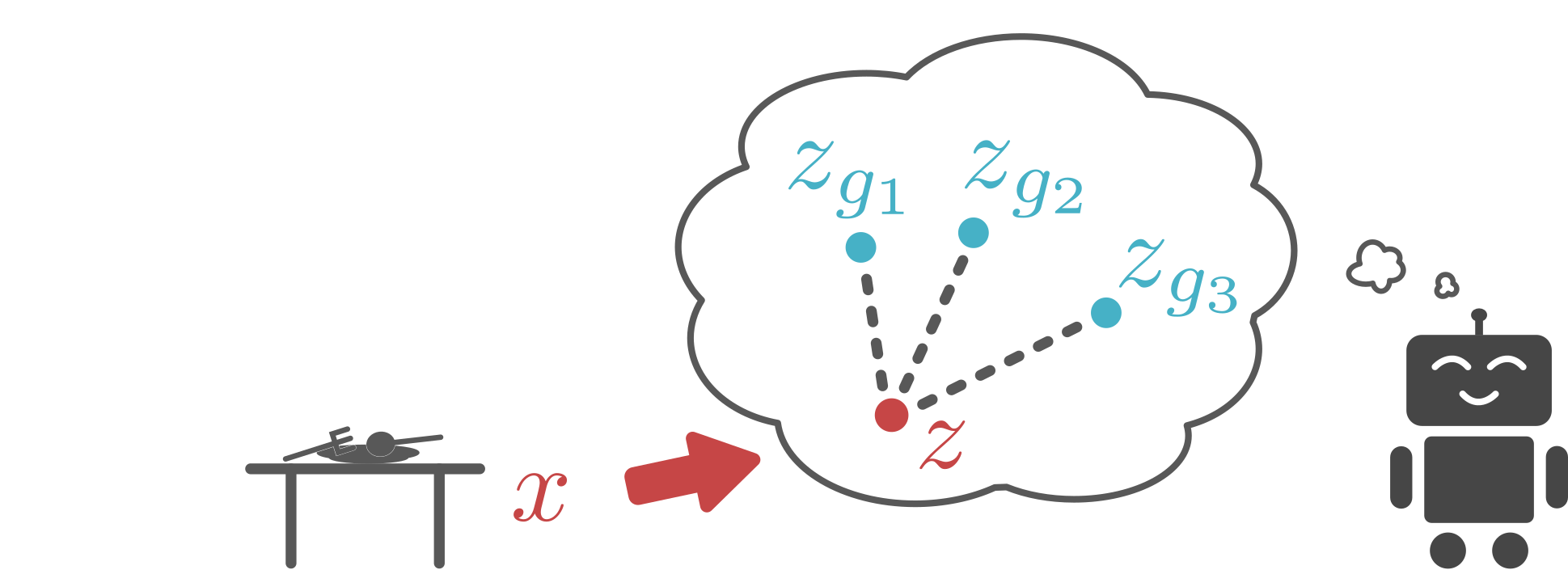
Even without a human providing a goal, our agent can still generate its own
goals, both for exploration and for goal relabeling.
All together, the latent variable representation of images (1) captures the underlying factors of a scene, (2) provides meaningful distances to optimize, and (3) provides an efficient goal sampling mechanism, allowing us to efficiently train a goal-conditioned reinforcement learning agent that operates directly on pixels. We call the overall method reinforcement learning with imagined goals (RIG).
Experiments
We conducted experiments to test if we RIG would be sample-efficient enough to train a real world robot policy in a reasonable amount of time. We tested the robot’s ability to reach user-specified positions and push objects to desired locations, as indicated by a goal image. The robot is trained with access only to 84x84 RGB images and without access to joint angles or object positions. The robot first learns by settings its own goals in the latent space. We can use the decoder to visualize the goals that the robot imagines for itself. In the GIF below, the top frame shows the decoded “imagined” goals, while the bottom frame shows the rollout of the actual policy.

The robot sets its own goals (top) and practices reaching them (bottom).
By setting its own goals, the robot can autonomously practice reaching different positions without human involvement. The only human involvement is when a person wants the robot to perform a specific task. At this point, the robot is given a goal image. Because the robot has practiced reaching so many goals, we see that it is able to reach this goal without additional training:

The human gives a goal image (top) and the robot reaches it (bottom).
We also used RIG to train a policy to push objects to target locations:
Left: The Sawyer robot setup. Right: The human gives a goal image (top) and the
robot reaches it (bottom).
Training a policy directly from images makes it easy to change tasks from reaching to object pushing. We simply added an object, added a table, and adjusted the camera. Lastly, despite working directly from pixels, these experiments did not take long to run. The reaching results took about an hour, while the pushing results took about 4.5 hours of real-robot interaction time. Many real-world robot reinforcement learning results use ground-truth state information like the position of an object. However, this usually requires additional machinery, like purchasing and setting up extra sensors or training an object-detection system. In contrast, our method only requires an RGB camera and works directly from the images.
For more results, including ablations and comparisons to baselines, we encourage readers to read the paper.
Future Directions
We’ve shown that we can train a real-world robot policy directly from images to achieve a variety of tasks in a sample-efficient way. There are a number of exciting next steps for this project. It might not be possible to represent all tasks with a goal image, and one could instead use other modalities, such as language and demonstrations, to represent goals. Also, while we provide a mechanism to sample goals for autonomous exploration, can we choose these goals in a more principled way to perform even better exploration? Incorporating ideas from intrinsic motivation would allow our policy to actively choose goals that will inform the policy to learn more quickly about what it can and cannot reach. Another future direction is to train our generative model so that it is aware of the dynamics. Encoding information about the environment dynamics could make the latent space even better suited for reinforcement learning, resulting in faster learning. Lastly, there are a variety of robot tasks whose state representation would be difficult to capture with sensors, such as manipulating deformable objects or handling scenes with variable number of objects. Scaling up RIG to solve these tasks would be an exciting next step.
The environment code is available here, and the algorithm code is available here.
This blog post is based on the following paper that was presented at Neural Information Processing Systems 2018 as a spotlight talk:
Visual Reinforcement Learning with Imagined Goals
Nair A.
, Pong V.
, Dalal M., Bahl S., Lin S., Levine S. NIPS 2018
paper,
videos
We would like to thank Sergey Levine for his valuable feedback when preparing this blog post, as well as Deirdre Quillen and Kyle Hsu for feedback on later drafts of this post.
$^*$ denotes equal contribution.