
Simulated humanoid performing a variety of highly dynamic and acrobatic skills.
Motion control problems have become standard benchmarks for reinforcement learning, and deep RL methods have been shown to be effective for a diverse suite of tasks ranging from manipulation to locomotion. However, characters trained with deep RL often exhibit unnatural behaviours, bearing artifacts such as jittering, asymmetric gaits, and excessive movement of limbs. Can we train our characters to produce more natural behaviours?
A wealth of inspiration can be drawn from computer graphics, where the physics-based simulation of natural movements have been a subject of intense study for decades. The greater emphasis placed on motion quality is often motivated by applications in film, visual effects, and games. Over the years, a rich body of work in physics-based character animation have developed controllers to produce robust and natural motions for a large corpus of tasks and characters. These methods often leverage human insight to incorporate task-specific control structures that provide strong inductive biases on the motions that can be achieved by the characters (e.g. finite-state machines, reduced models, and inverse dynamics). But as a result of these design decisions, the controllers are often specific to a particular character or task, and controllers developed for walking may not extend to more dynamic skills, where human insight becomes scarce.
In this work, we will draw inspiration from the two fields to take advantage of the generality afforded by deep learning models while also producing naturalistic behaviours that rival the state-of-the-art in full body motion simulation in computer graphics. We present a conceptually simple RL framework that enables simulated characters to learn highly dynamic and acrobatic skills from reference motion clips, which can be provided in the form of mocap data recorded from human subjects. Given a single demonstration of a skill, such as a spin-kick or a backflip, our character is able to learn a robust policy to imitate the skill in simulation. Our policies produce motions that are nearly indistinguishable from mocap.
Motion Imitation
In most RL benchmarks, simulated characters are represented using simple models that provide only a crude approximation of real world dynamics. Characters are therefore prone to exploiting idiosyncrasies of the simulation to develop unnatural behaviours that are infeasible in the real world. Incorporating more realistic biomechanical models can lead to more natural behaviours. But constructing high-fidelity models can be extremely challenging, and the resulting motions may nonetheless be unnatural.
An alternative is to take a data-driven approach, where reference motion capture of humans provides examples of natural motions. The character can then be trained to produce more natural behaviours by imitating the reference motions. Imitating motion data in simulation has a long history in computer animation and has seen some recent demonstrations with deep RL. While the results do appear more natural, they are still far from being able to faithfully reproduce a wide variety of motions.
In this work, our policies will be trained through a motion imitation task, where the goal of the character is to reproduce a given kinematic reference motion. Each reference motion is represented by a sequence of target poses ${\hat{q}_0, \hat{q}_1,\ldots,\hat{q}_T}$, where $\hat{q}_t$ is the target pose at timestep $t$. The reward function is to minimize the least squares pose error between the target pose $\hat{q}_t$ and the pose of the simulated character $q_t$,
\[r_t = {\rm exp}\Big[-2 \|\hat{q}_t - q_t \|^2 \Big]\]While more sophisticated methods have been applied for motion imitation, we found that simply minimizing the tracking error (along with a couple of additional insights) works surprisingly well. The policies are trained by optimizing this objective using PPO.
With this framework, we are able to develop policies for a rich repertoire of challenging skills ranging from locomotion to acrobatics, martial arts to dancing.


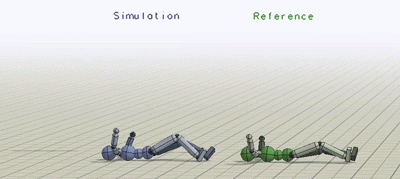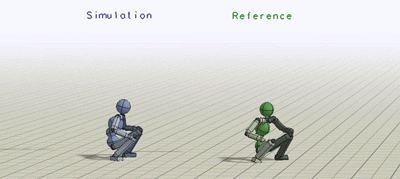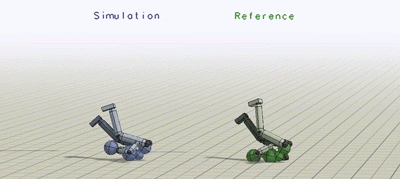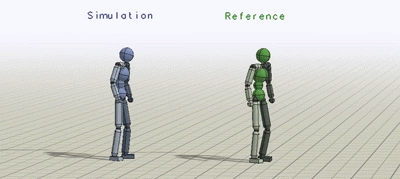

The humanoid learns to imitate various skills. The blue character is the
simulated character, and the green character is replaying the respective mocap
clip. Top left: sideflip. Top right: cartwheel. Bottom left: kip-up. Bottom
right: speed vault.
Next, we compare our method with previous results that used (e.g. generative adversarial imitation learning (GAIL)) to imitate mocap clips. Our method is substantially simpler than GAIL and it is able to better reproduce the reference motions. The resulting policy avoids many of the artifacts commonly exhibited by deep RL methods, and enables the character to produce a fluid life-like running gait.


Comparison of our method (left) and work from Merel et al. [2017] using GAIL to
imitate mocap data. Our motions appear significantly more natural than previous
work using deep RL.
Insights
Reference State Initialization (RSI)
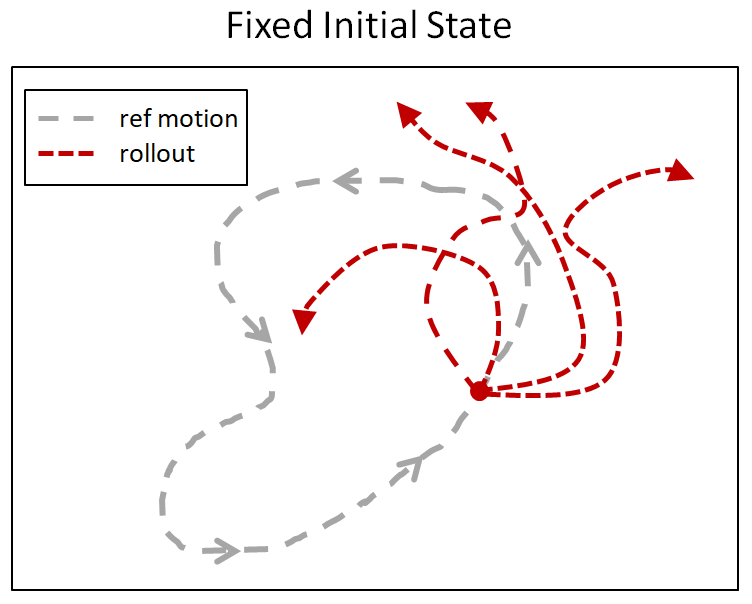
Suppose the character is trying to imitate a backflip. How would it know that doing a full rotation midair will result in high rewards? Since most RL algorithms are retrospective, they only observe rewards for states they have visited. In the case of a backflip, the character will have to observe successful trajectories of a backflip before it learns that those states will yield high rewards. But since a backflip can be very sensitive to the initial conditions at takeoff and landing, the character is unlikely to accidentally execute a successful trajectory through random exploration. To give the character a hint, at the start of each episode, we will initialize the character to a state sampled randomly along the reference motion. So sometimes the character will start on the ground, and sometimes it will start in the middle of the flip. This allows the character to learn which states will result in high rewards even before it has acquired the proficiency to reach those states.
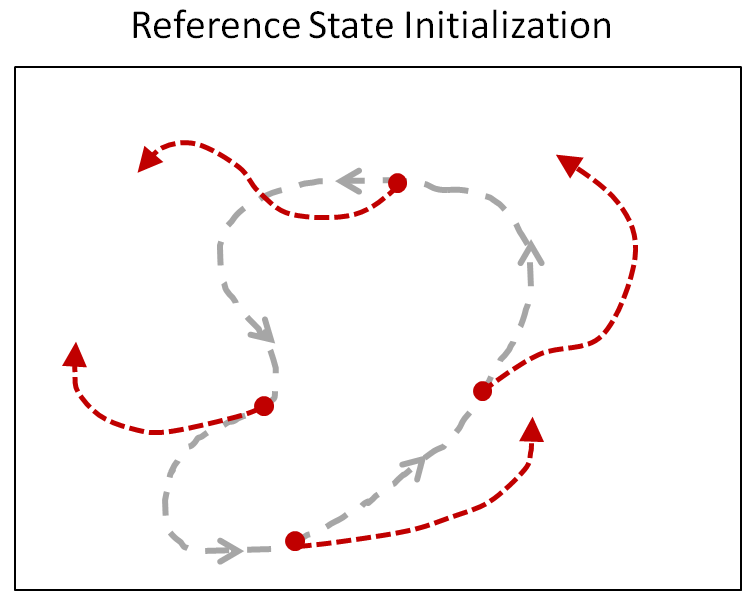
RSI provides the character with a richer initial state distribution by
initializing it to random point along the reference motion.
Below is a comparison of the backflip policy trained with RSI and without RSI, where the character is always initialized to a fixed initial state at the start of the motion. Without RSI, instead of learning a flip, the policy just cheats by hopping backwards.

Comparison of policies trained without RSI or ET. RSI and ET can be crucial for
learning more dynamics motions. Left: RSI+ET. Middle: No RSI. Right: No ET.
Early Termination (ET)
Early termination is a staple for RL practitioners, and it is often used to improve simulation efficiency. If the character gets stuck in a state from which there is no chance of success, then the episode is terminated early, to avoid simulating the rest. Here we show that early termination can in fact have a significant impact on the results. Again, let’s consider a backflip. During the early stages of training, the policy is terrible and the character will spend most of its time falling. Once the character has fallen, it can be extremely difficult for it to recover. So the rollouts will be dominated by samples where the character is just struggling in vain on the ground. This is analogous to the class imbalance problem encountered by other methodologies such as supervised learning. This issue can be mitigated by terminating an episode as soon as the character enters such a futile state (e.g. falling). Coupled with RSI, ET helps to ensure that a larger portion of the dataset consists of samples close to the reference trajectory. Without ET the character never learns to perform a flip. Instead, it just falls and then tries to mime the motion on the ground.
More Results
In total, we have been able to learn over 24 skills for the humanoid just by providing it with different reference motions.
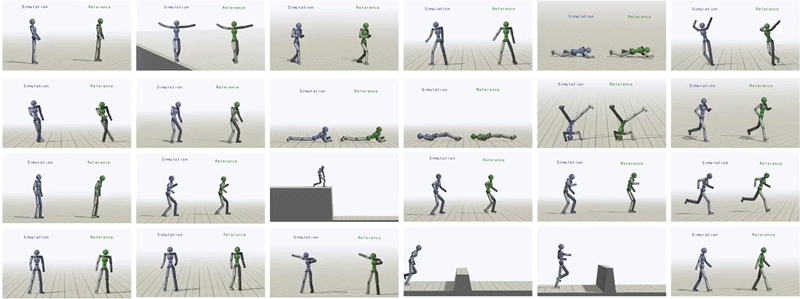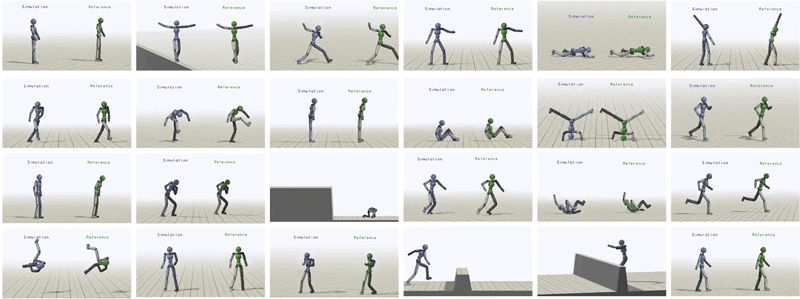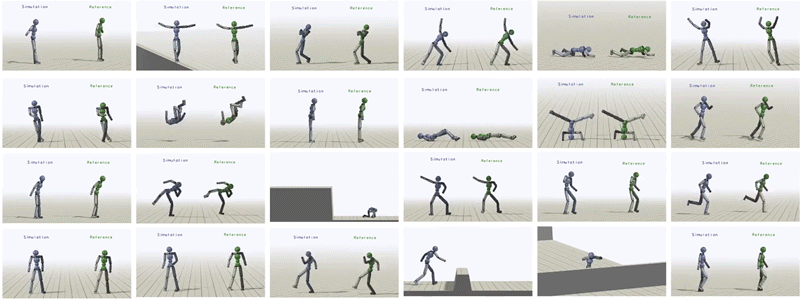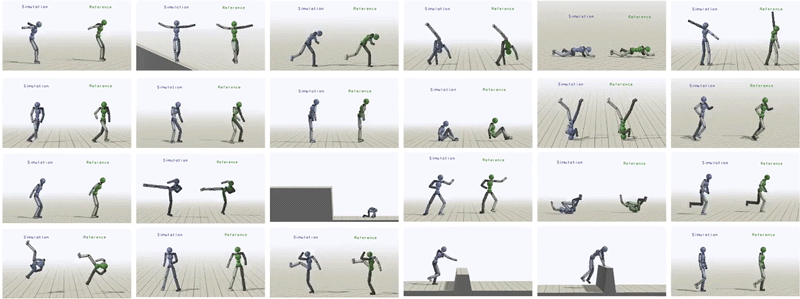
Humanoid trained to imitate a rich repertoire of skills.
In addition to imitating mocap clips, we can also train the humanoid to perform some additional tasks like kicking a randomly placed target, or throwing a ball to a target.
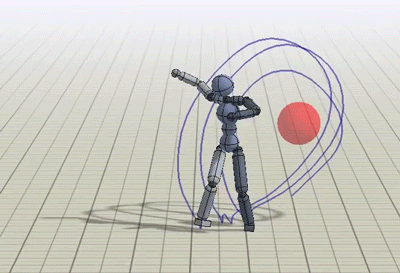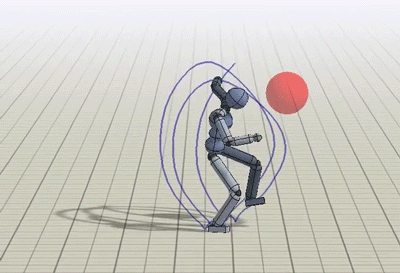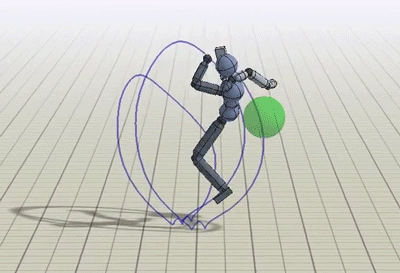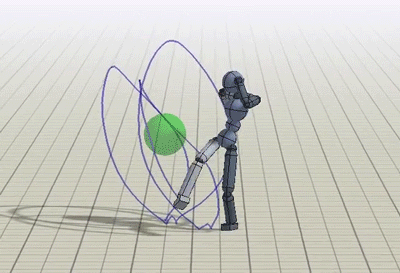

Policies trained to kick and throw a ball to a random target.
We can also train a simulated Atlas robot to imitate mocap clips from a human. Though the Atlas has a very different morphology and mass distribution, it is still able to reproduce the desired motions. Not only can the policies imitate the reference motions, they can also recover from pretty significant perturbations.


Atlas trained to perform a spin-kick and backflip. The policies are robust to
significant perturbations.
But what do we do if we don’t have mocap clips? Suppose we want to simulate a T-Rex. For various reasons, it is a bit difficult to mocap a T-Rex. So instead, we can have an artist hand-animate some keyframes and then train a policy to imitate those.

Simulated T-Rex trained to imitate artist-authored keyframes.
By why stop at a T-Rex? Let’s train a lion:
Simulated lion. Reference motion courtesy of Ziva Dynamics.
and a dragon:

Simulated dragon with a 418D state space and 94D action space.
The story here is that a simple method ends up working surprisingly well. Just by minimizing the tracking error, we are able to train policies for a diverse collection of characters and skills. We hope this work will help inspire the development of more dynamic motor skills for both simulated characters and robots in the real world. Exploring methods for imitating motions from more prevalent sources such as video is also an exciting avenue for scenarios that are challenging to mocap, such as animals and cluttered environments.
To learn more, check out our paper.
We would like to thank the co-authors of this work: Pieter Abbeel, Sergey Levine, and Michiel van de Panne. This project was done in collaboration with the University of British Columbia.