
Left: Given movie poster, Right: New movie title generated by MC-GAN.
Text is a prominent visual element of 2D design. Artists invest significant time into designing glyphs that are visually compatible with other elements in their shape and texture. This process is labor intensive and artists often design only the subset of glyphs that are necessary for a title or an annotation, which makes it difficult to alter the text after the design is created, or to transfer an observed instance of a font to your own project.
Early research on glyph synthesis focused on geometric modeling of outlines, which is limited to particular glyph topology (e.g., cannot be applied to decorative or hand-written glyphs) and cannot be used with image input. With the rise of deep neural networks, researchers have looked at modeling glyphs from images. On the other hand, synthesizing data consistent with partial observations is an interesting problem in computer vision and graphics such as multi-view image generation, completing missing regions in images, and generating 3D shapes. Font data is an example that provides a clean factorization of style and content.
Recent advances in conditional generative adversarial networks (cGANS) [1] have been successful in many generative applications. However, they do best only with fairly specialized domains and not with general or multi-domain style transfer. Similarly, when directly used to generate fonts, cGAN models produce significant artifacts. For instance, given the following five letters,

a conditional GAN model is not successful in generating all 26 letters with the same style:
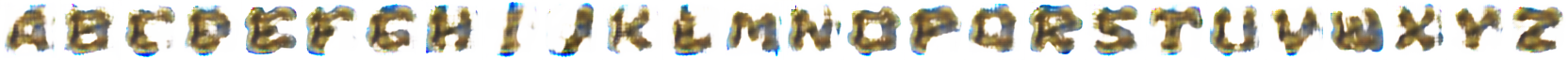
Multi-Content GAN for Few Shot Font Style Transfer
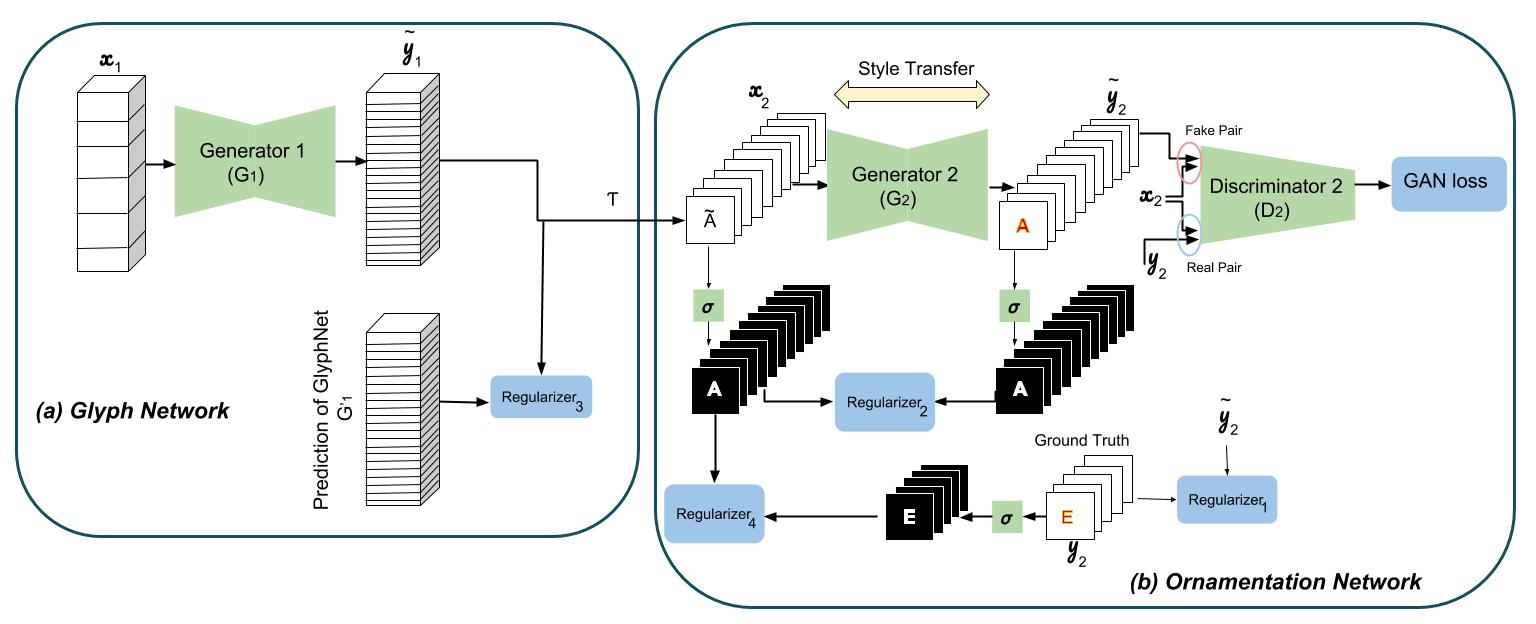
Instead of training a single network for all possible typeface ornamentations, we designed the multi-content GAN architecture [2] to retrain a customized magical network for each observed character set with only a handful of observed glyphs. This model considers content (i.e., A-Z glyphs) along channels and style (i.e., glyph ornamentations) along network layers to transfer the style of given glyphs to the contents of unseen ones.
The multi-content GAN model consists of a stacked cGAN architecture to predict the coarse glyph shapes and an ornamentation network to predict color and texture of the final glyphs. The first network, called GlyphNet, predicts glyph masks while the second network, called OrnaNet, fine-tunes color and ornamentation of the generated glyphs from the first network. Each sub-network follows the conditional generative adversarial network (cGAN) architecture modified for its specific purpose of stylizing glyphs or ornamentation prediction.
Network Architecture
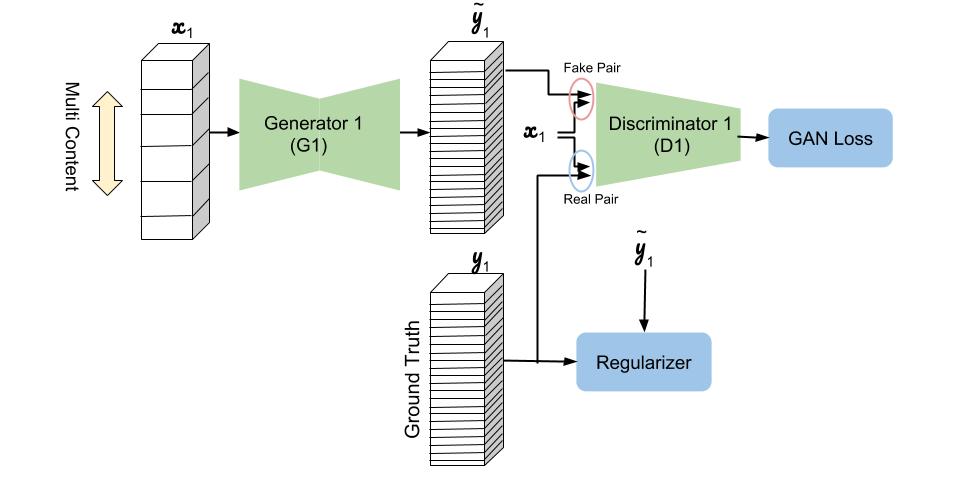
Here is the schematic of GlyphNet to learn the general shape of the font manifold from a set of training fonts. Input and output of the GlyphNet are stacks of the glyphs where a channel is assigned for each letter. In each training iteration, $x_1$ includes a randomly chosen subset of $y_1$ glyphs with the remaining input channels being zeroed out.
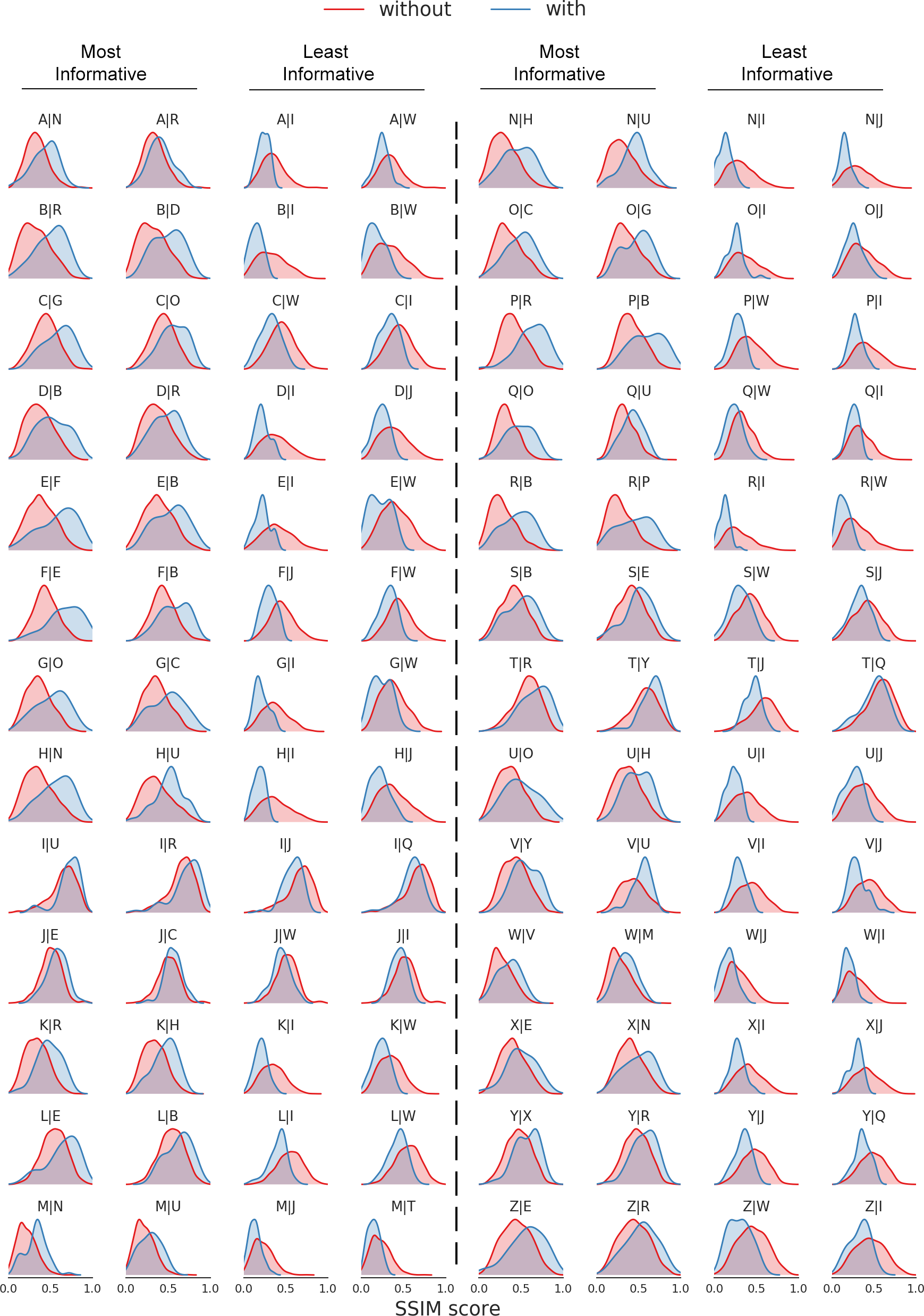
With this novel glyph stack design, correlations between different glyphs are learned across network channels in order to transfer their style automatically. The following plots represent such correlations through the structural similarity (SSIM) metric on a random set of 1500 font examples. Computing the structural similarity between each generated glyph and its ground truth, 25 distributions are found when a single letter has been observed at a time. These plots show the distributions $\alpha| \beta$ of generating letter $\alpha$ when letter $\beta$ is observed (in blue) vs when any other letter rather than $\beta$ is given (in red). Distributions for the two most informative given letters and the two least informative ones in generating each of the 26 letters are shown in this figure. For instance, looking at the fifth row of the figure, letters F and B are the most constructive in generating letter E compared with other letters while I and W are the least informative ones. As other examples, O and C are the most guiding letters for constructing G as well as R and B for generating P.
Therefore, for any desirable font with only a few observed letters, the pre-trained GlyphNet generates all 26 A-Z glyphs. But how should we transfer ornamentation? The second network, OrnaNet, takes these generated glyphs and after a simple reshape transformation and gray-scale channel repetition, represented by $\mathcal{T}$ in the next figure, generates outputs enriched with desirable color and ornamentation using a conditional GAN architecture. Inputs and outputs of the OrnaNet are batches of RGB images instead of stacks where the RGB channels for each letter, as an image, are repeats of its corresponding gray-scale glyph generated by the GlyphNet. Multiple regularizers in the OrnaNet penalize deviation of the masks of stylized letters from their corresponding glyph shapes.
Results
Below, we demonstrate exemplar sentences using the font style given in a single word.
![]()
![]()
![]()
![]()
Also, here is the gradual improvement in the OrnaNet prediction:
References
[1] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros. "Image-to-Image Translation with Conditional Adversarial Networks." CVPR 2017.
[2] Samaneh Azadi, Matthew Fisher, Vladimir Kim, Zhaowen Wang, Eli Shechtman, and Trevor Darrell. "Multi-Content GAN for Few-Shot Font Style Transfer." CVPR 2018.
More Information
For more information about Multi-Content GAN, please take a look at the following links:
Please let us know if you have any questions or suggestions.