Given an image, humans can easily infer the salient entities in it, and describe the scene effectively, such as, where objects are located (in a forest or in a kitchen?), what attributes an object has (brown or white?), and, importantly, how objects interact with other objects in a scene (running in a field, or being held by a person etc.). The task of visual description aims to develop visual systems that generate contextual descriptions about objects in images. Visual description is challenging because it requires recognizing not only objects (bear), but other visual elements, such as actions (standing) and attributes (brown), and constructing a fluent sentence describing how objects, actions, and attributes are related in an image (such as the brown bear is standing on a rock in the forest).
Current State of Visual Description

|

|
LRCN [Donahue et al. ‘15]: A brown bear standing on top of a lush green field. |
LRCN [Donahue et al. ‘15]: A black bear is standing in the grass. |
Descriptions generated by existing captioners on two images. On the left is an image of an object (bear) that is present in training data. On the right is an object (anteater) that the model hasn't seen in training.
Current visual description or image captioning models work quite well, but they can only describe objects seen in existing image captioning training datasets, and they require a large number of training examples to generate good captions. To learn how to describe an object like “jackal” or “anteater” in context, most description models require many examples of jackal or anteater images with corresponding descriptions. However, current visual description datasets, like MSCOCO, do not include descriptions about all objects. In contrast, recent works in object recognition through Convolutional Neural Networks (CNNs) can recognize hundreds of categories of objects. While object recognition models can recognize jackals and anteaters, description models cannot compose sentences to describe these animals correctly in context. In our work, we overcome this problem by building visual description systems which can describe new objects without pairs of images and sentences about these objects.
The Task: Describing Novel Objects
Here we define our task more formally. Given a dataset consisting of pairs of images and descriptions (paired image-sentence data, e.g. MSCOCO) as well as images with object labels but no descriptions (unpaired image data, such as ImageNet) we wish to learn how to describe objects unseen in paired image-sentence data. To do this we must build a model which can recognize different visual constituents (e.g., jackal, brown, standing, and field) and compose these in novel ways to form a coherent description. Below we describe the core components of our description model.
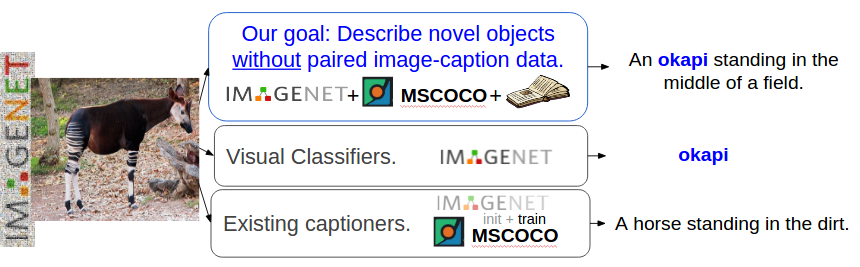
We aim to describe diverse objects which do not have training images with captions.
Using External Sources of Data
In order to generate captions about diverse categories of objects outside the image-caption training data, we take advantage of external data sources. Specifically, we use ImageNet images with object labels as the unpaired image data source and sentences from unannotated text corpora such as Wikipedia as our text data source. These are used to train our visual recognition CNN and language model respectively.

Train effectively on external resources
Capture semantic similarity
We want to be able to describe unseen objects (e.g. from ImageNet) that are similar to objects that have been seen in the paired image-sentence training data. We use dense word embeddings to achieve this. Word embeddings are dense high dimensional representations of words where words with similar meaning are closer in the embedding space.
In our previous work, called “Deep Compositional Captioning (DCC)” [1] we first train a caption model on MSCOCO paired image caption dataset. Then to describe novel objects, for each novel object (such as an okapi) we use word embeddings to identify an object that’s most similar amongst the objects in the MSCOCO dataset (in this case zebra). We then transfer (copy) the parameters learned by the model from the seen object to the unseen object (i.e. copy weights in the network corresponding to zebra to those corresponding to okapi).
Novel Object Captioning
While the DCC model is able to describe several unseen object categories, copying parameters from one object to another can create sentences with grammatical artifacts. E.g. for the object ‘racket’ the model copies weights from ‘tennis’, which results in sentences such as “A man playing racket on court”. In our more recent work [2], we incorporate the embeddings directly within our language model. Specifically, we use GloVe embeddings in the input and output of our language model. This implicitly enables the model to capture semantic similarity when describing unseen objects. This enables our model to generate sentences such as “A tennis player swinging a racket at a ball”. Additionally, incorporating the embeddings directly within the network makes our model end-to-end trainable.
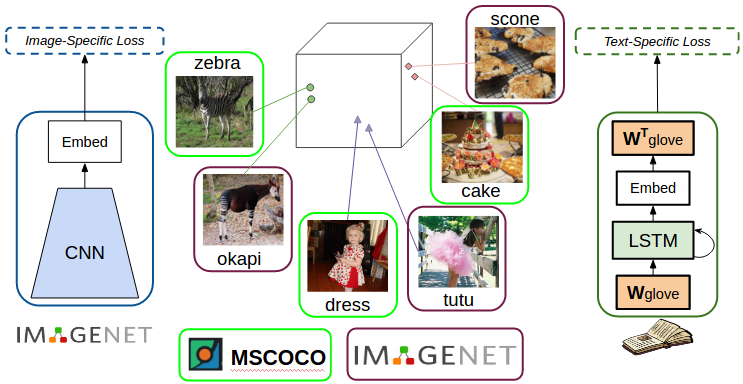
Incorporate dense word embeddings in the language model to capture semantic similarity.
Caption model and forgetting in neural networks.
We combine the outputs of the visual network and language model to a caption model. This model is similar to existing caption models which are also pre-trained on ImageNet. However, we observed that although the model is pre-trained on ImageNet, when the model is trained / tuned on the COCO image-caption dataset it tends to forget what it has seen before. The problem of forgetting in neural networks has also been observed by researchers at Montreal as well as Google DeepMind amongst others. In our work, we resolve this problem of forgetting using a joint training strategy.
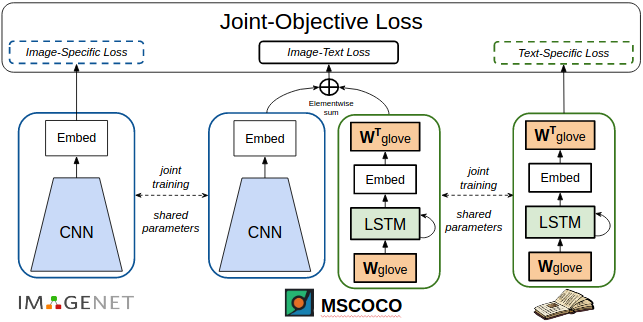
Share parameters and train jointly on different data/tasks to overcome "forgetting"
Specifically, our network has three components: a visual recognition network, a caption model, and a language model. All three components share parameters and are jointly trained. During training, each batch of inputs contains some images with labels, a different set of images and captions, and some plain sentences. These three inputs train the different components of the network. Since the parameters are shared between the three components, the network is jointly trained to recognize objects in images, caption images and generate sentences. This joint training helps the network overcome the problem of forgetting, and enables the model to generate descriptions for many novel object categories.
What’s Next?
One of the most common errors in our model comes from not recognizing objects, and one way to mitigate this is to use better visual features. Another common error comes from generating sentences which are not fluent (A cat and a cat on a bed) or may not appeal to “common sense” (e.g. ‘A woman is playing gymnastics’ is not particularly correct since one doesn’t “play” gymnastics). It would be interesting to develop solutions that can overcome these issues.
While in this work, we proposes joint training as a strategy to overcome the problem of forgetting, it might not always be possible to train on lots of different tasks and datasets. A different way to approach the problem would be to build a model that can learn to compose descriptions based on visual information and object labels. Such a model should also be able to integrate objects on the fly i.e. currently we pre-train our model on a select set of objects, we should also think about how we can incrementally train our model on new data about some new concepts. Solving some of these problems can help develop better and more robust visual description models.
[Links to trained models and code]
Examples

This blog post is based on the following research papers:
[1] L. A. Hendricks, S. Venugopalan, M. Rohrbach, R. Mooney, K. Saenko, and T. Darrell. Deep compositional captioning: Describing novel object categories without paired training data. In CVPR, 2016.
[2] S. Venugopalan, L. A. Hendricks, M. Rohrbach, R. Mooney, K. Saenko, and T. Darrell. Captioning images with diverse objects. In CVPR, 2017.